 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMAligner: Enhancing Image Alignment via Diffusion Model Based View Synthesis
Feb 26, 2026Image alignment is a fundamental task in computer vision with broad applications. Existing methods predominantly employ optical flow-based image warping. However, this technique is susceptible to common challenges such as occlusions and illumination variations, leading to degraded alignment visual quality and compromised accuracy in downstream tasks. In this paper, we present DMAligner, a diffusion-based framework for image alignment through alignment-oriented view synthesis. DMAligner is crafted to tackle the challenges in image alignment from a new perspective, employing a generation-based solution that showcases strong capabilities and avoids the problems associated with flow-based image warping. Specifically, we propose a Dynamics-aware Diffusion Training approach for learning conditional image generation, synthesizing a novel view for image alignment. This incorporates a Dynamics-aware Mask Producing (DMP) module to adaptively distinguish dynamic foreground regions from static backgrounds, enabling the diffusion model to more effectively handle challenges that classical methods struggle to solve. Furthermore, we develop the Dynamic Scene Image Alignment (DSIA) dataset using Blender, which includes 1,033 indoor and outdoor scenes with over 30K image pairs tailored for image alignment. Extensive experimental results demonstrate the superiority of the proposed approach on DSIA benchmarks, as well as on a series of widely-used video datasets for qualitative comparisons. Our code is available at https://github.com/boomluo02/DMAligner.
RAW-Flow: Advancing RGB-to-RAW Image Reconstruction with Deterministic Latent Flow Matching
Jan 28, 2026RGB-to-RAW reconstruction, or the reverse modeling of a camera Image Signal Processing (ISP) pipeline, aims to recover high-fidelity RAW data from RGB images. Despite notable progress, existing learning-based methods typically treat this task as a direct regression objective and struggle with detail inconsistency and color deviation, due to the ill-posed nature of inverse ISP and the inherent information loss in quantized RGB images. To address these limitations, we pioneer a generative perspective by reformulating RGB-to-RAW reconstruction as a deterministic latent transport problem and introduce a novel framework named RAW-Flow, which leverages flow matching to learn a deterministic vector field in latent space, to effectively bridge the gap between RGB and RAW representations and enable accurate reconstruction of structural details and color information. To further enhance latent transport, we introduce a cross-scale context guidance module that injects hierarchical RGB features into the flow estimation process. Moreover, we design a dual-domain latent autoencoder with a feature alignment constraint to support the proposed latent transport framework, which jointly encodes RGB and RAW inputs while promoting stable training and high-fidelity reconstruction. Extensive experiments demonstrate that RAW-Flow outperforms state-of-the-art approaches both quantitatively and visually.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024



This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Learning Real-World Image De-Weathering with Imperfect Supervision
Oct 23, 2023



Real-world image de-weathering aims at removing various undesirable weather-related artifacts. Owing to the impossibility of capturing image pairs concurrently, existing real-world de-weathering datasets often exhibit inconsistent illumination, position, and textures between the ground-truth images and the input degraded images, resulting in imperfect supervision. Such non-ideal supervision negatively affects the training process of learning-based de-weathering methods. In this work, we attempt to address the problem with a unified solution for various inconsistencies. Specifically, inspired by information bottleneck theory, we first develop a Consistent Label Constructor (CLC) to generate a pseudo-label as consistent as possible with the input degraded image while removing most weather-related degradations. In particular, multiple adjacent frames of the current input are also fed into CLC to enhance the pseudo-label. Then we combine the original imperfect labels and pseudo-labels to jointly supervise the de-weathering model by the proposed Information Allocation Strategy (IAS). During testing, only the de-weathering model is used for inference. Experiments on two real-world de-weathering datasets show that our method helps existing de-weathering models achieve better performance. Codes are available at https://github.com/1180300419/imperfect-deweathering.
Self-supervised Learning to Bring Dual Reversed Rolling Shutter Images Alive
May 31, 2023



Modern consumer cameras usually employ the rolling shutter (RS) mechanism, where images are captured by scanning scenes row-by-row, yielding RS distortions for dynamic scenes. To correct RS distortions, existing methods adopt a fully supervised learning manner, where high framerate global shutter (GS) images should be collected as ground-truth supervision. In this paper, we propose a Self-supervised learning framework for Dual reversed RS distortions Correction (SelfDRSC), where a DRSC network can be learned to generate a high framerate GS video only based on dual RS images with reversed distortions. In particular, a bidirectional distortion warping module is proposed for reconstructing dual reversed RS images, and then a self-supervised loss can be deployed to train DRSC network by enhancing the cycle consistency between input and reconstructed dual reversed RS images. Besides start and end RS scanning time, GS images at arbitrary intermediate scanning time can also be supervised in SelfDRSC, thus enabling the learned DRSC network to generate a high framerate GS video. Moreover, a simple yet effective self-distillation strategy is introduced in self-supervised loss for mitigating boundary artifacts in generated GS images. On synthetic dataset, SelfDRSC achieves better or comparable quantitative metrics in comparison to state-of-the-art methods trained in the full supervision manner. On real-world RS cases, our SelfDRSC can produce high framerate GS videos with finer correction textures and better temporary consistency. The source code and trained models are made publicly available at https://github.com/shangwei5/SelfDRSC.
Spatially Adaptive Self-Supervised Learning for Real-World Image Denoising
Mar 27, 2023Significant progress has been made in self-supervised image denoising (SSID) in the recent few years. However, most methods focus on dealing with spatially independent noise, and they have little practicality on real-world sRGB images with spatially correlated noise. Although pixel-shuffle downsampling has been suggested for breaking the noise correlation, it breaks the original information of images, which limits the denoising performance. In this paper, we propose a novel perspective to solve this problem, i.e., seeking for spatially adaptive supervision for real-world sRGB image denoising. Specifically, we take into account the respective characteristics of flat and textured regions in noisy images, and construct supervisions for them separately. For flat areas, the supervision can be safely derived from non-adjacent pixels, which are much far from the current pixel for excluding the influence of the noise-correlated ones. And we extend the blind-spot network to a blind-neighborhood network (BNN) for providing supervision on flat areas. For textured regions, the supervision has to be closely related to the content of adjacent pixels. And we present a locally aware network (LAN) to meet the requirement, while LAN itself is selectively supervised with the output of BNN. Combining these two supervisions, a denoising network (e.g., U-Net) can be well-trained. Extensive experiments show that our method performs favorably against state-of-the-art SSID methods on real-world sRGB photographs. The code is available at https://github.com/nagejacob/SpatiallyAdaptiveSSID.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022



The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022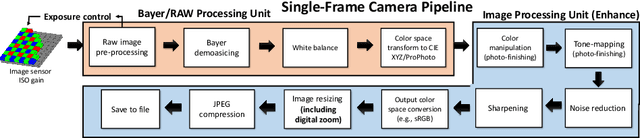
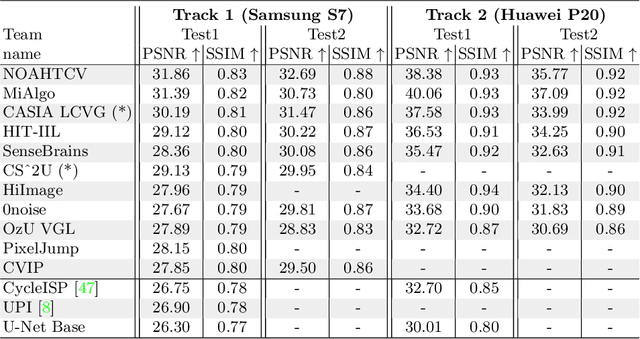
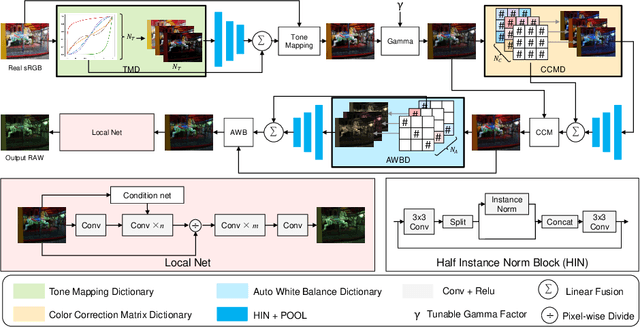
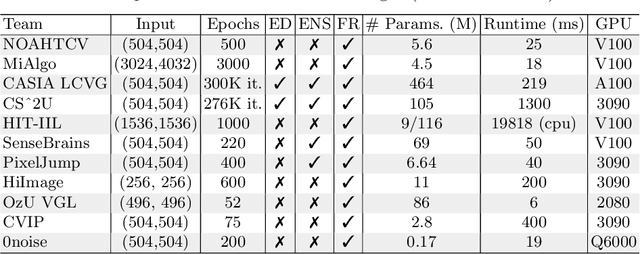
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022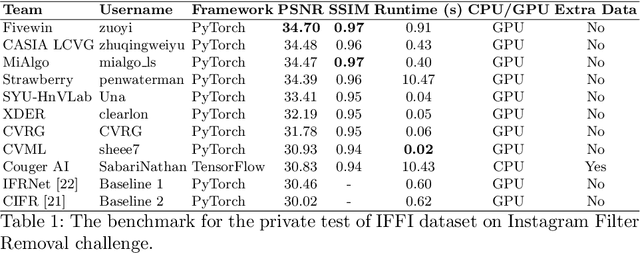

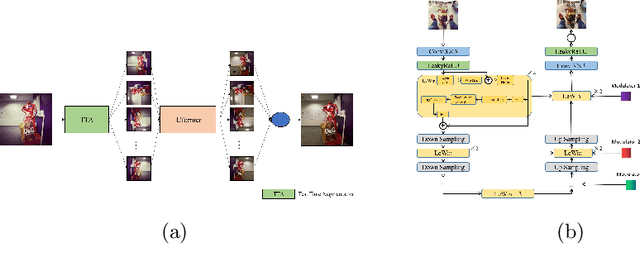
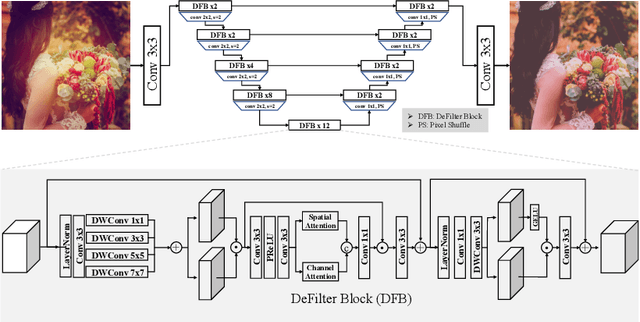
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.