 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
EHC-MM: Embodied Holistic Control for Mobile Manipulation
Sep 13, 2024



Mobile manipulation typically entails the base for mobility, the arm for accurate manipulation, and the camera for perception. It is necessary to follow the principle of Distant Mobility, Close Grasping(DMCG) in holistic control. We propose Embodied Holistic Control for Mobile Manipulation(EHC-MM) with the embodied function of sig(w): By formulating the DMCG principle as a Quadratic Programming (QP) problem, sig(w) dynamically balances the robot's emphasis between movement and manipulation with the consideration of the robot's state and environment. In addition, we propose the Monitor-Position-Based Servoing (MPBS) with sig(w), enabling the tracking of the target during the operation. This approach allows coordinated control between the robot's base, arm, and camera. Through extensive simulations and real-world experiments, our approach significantly improves both the success rate and efficiency of mobile manipulation tasks, achieving a 95.6% success rate in the real-world scenarios and a 52.8% increase in time efficiency.
ASGrasp: Generalizable Transparent Object Reconstruction and Grasping from RGB-D Active Stereo Camera
May 09, 2024



In this paper, we tackle the problem of grasping transparent and specular objects. This issue holds importance, yet it remains unsolved within the field of robotics due to failure of recover their accurate geometry by depth cameras. For the first time, we propose ASGrasp, a 6-DoF grasp detection network that uses an RGB-D active stereo camera. ASGrasp utilizes a two-layer learning-based stereo network for the purpose of transparent object reconstruction, enabling material-agnostic object grasping in cluttered environments. In contrast to existing RGB-D based grasp detection methods, which heavily depend on depth restoration networks and the quality of depth maps generated by depth cameras, our system distinguishes itself by its ability to directly utilize raw IR and RGB images for transparent object geometry reconstruction. We create an extensive synthetic dataset through domain randomization, which is based on GraspNet-1Billion. Our experiments demonstrate that ASGrasp can achieve over 90% success rate for generalizable transparent object grasping in both simulation and the real via seamless sim-to-real transfer. Our method significantly outperforms SOTA networks and even surpasses the performance upper bound set by perfect visible point cloud inputs.Project page: https://pku-epic.github.io/ASGrasp
What Foundation Models can Bring for Robot Learning in Manipulation : A Survey
Apr 28, 2024



The realization of universal robots is an ultimate goal of researchers. However, a key hurdle in achieving this goal lies in the robots' ability to manipulate objects in their unstructured surrounding environments according to different tasks. The learning-based approach is considered an effective way to address generalization. The impressive performance of foundation models in the fields of computer vision and natural language suggests the potential of embedding foundation models into manipulation tasks as a viable path toward achieving general manipulation capability. However, we believe achieving general manipulation capability requires an overarching framework akin to auto driving. This framework should encompass multiple functional modules, with different foundation models assuming distinct roles in facilitating general manipulation capability. This survey focuses on the contributions of foundation models to robot learning for manipulation. We propose a comprehensive framework and detail how foundation models can address challenges in each module of the framework. What's more, we examine current approaches, outline challenges, suggest future research directions, and identify potential risks associated with integrating foundation models into this domain.
RobotGPT: Robot Manipulation Learning from ChatGPT
Dec 03, 2023



We present RobotGPT, an innovative decision framework for robotic manipulation that prioritizes stability and safety. The execution code generated by ChatGPT cannot guarantee the stability and safety of the system. ChatGPT may provide different answers for the same task, leading to unpredictability. This instability prevents the direct integration of ChatGPT into the robot manipulation loop. Although setting the temperature to 0 can generate more consistent outputs, it may cause ChatGPT to lose diversity and creativity. Our objective is to leverage ChatGPT's problem-solving capabilities in robot manipulation and train a reliable agent. The framework includes an effective prompt structure and a robust learning model. Additionally, we introduce a metric for measuring task difficulty to evaluate ChatGPT's performance in robot manipulation. Furthermore, we evaluate RobotGPT in both simulation and real-world environments. Compared to directly using ChatGPT to generate code, our framework significantly improves task success rates, with an average increase from 38.5% to 91.5%. Therefore, training a RobotGPT by utilizing ChatGPT as an expert is a more stable approach compared to directly using ChatGPT as a task planner.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022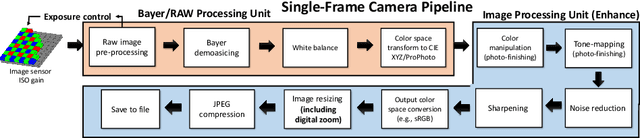
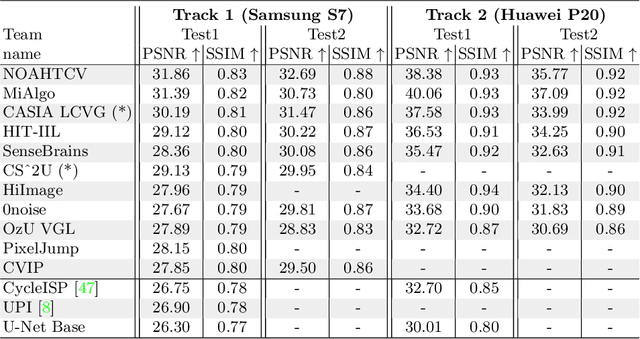
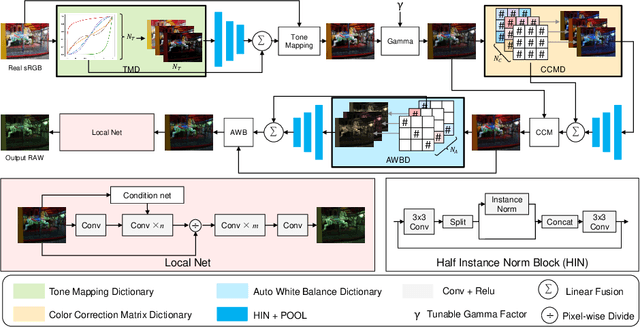
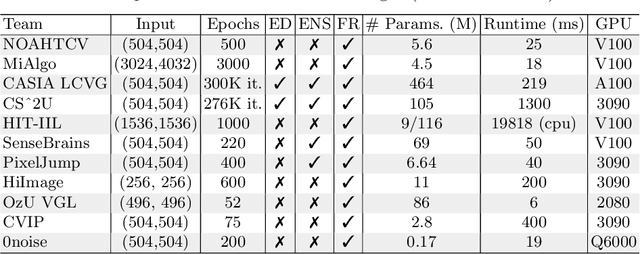
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Lightweight Vision Transformer with Cross Feature Attention
Jul 15, 2022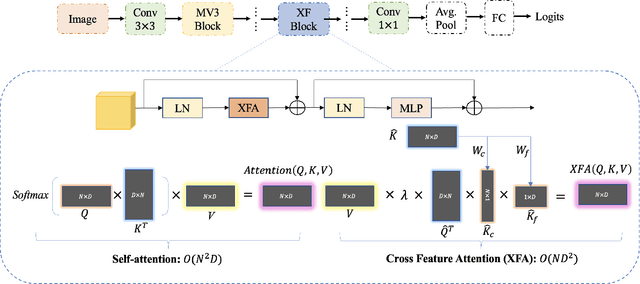
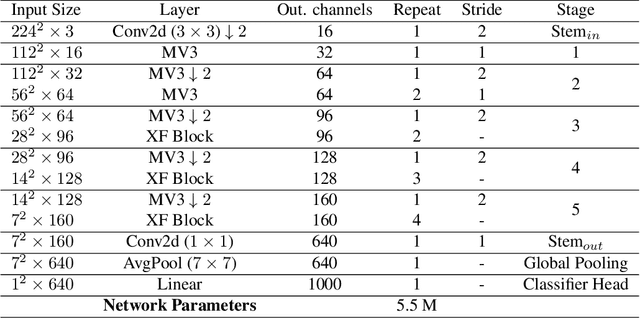


Recent advances in vision transformers (ViTs) have achieved great performance in visual recognition tasks. Convolutional neural networks (CNNs) exploit spatial inductive bias to learn visual representations, but these networks are spatially local. ViTs can learn global representations with their self-attention mechanism, but they are usually heavy-weight and unsuitable for mobile devices. In this paper, we propose cross feature attention (XFA) to bring down computation cost for transformers, and combine efficient mobile CNNs to form a novel efficient light-weight CNN-ViT hybrid model, XFormer, which can serve as a general-purpose backbone to learn both global and local representation. Experimental results show that XFormer outperforms numerous CNN and ViT-based models across different tasks and datasets. On ImageNet1K dataset, XFormer achieves top-1 accuracy of 78.5% with 5.5 million parameters, which is 2.2% and 6.3% more accurate than EfficientNet-B0 (CNN-based) and DeiT (ViT-based) for similar number of parameters. Our model also performs well when transferring to object detection and semantic segmentation tasks. On MS COCO dataset, XFormer exceeds MobileNetV2 by 10.5 AP (22.7 -> 33.2 AP) in YOLOv3 framework with only 6.3M parameters and 3.8G FLOPs. On Cityscapes dataset, with only a simple all-MLP decoder, XFormer achieves mIoU of 78.5 and FPS of 15.3, surpassing state-of-the-art lightweight segmentation networks.
WPNAS: Neural Architecture Search by jointly using Weight Sharing and Predictor
Mar 04, 2022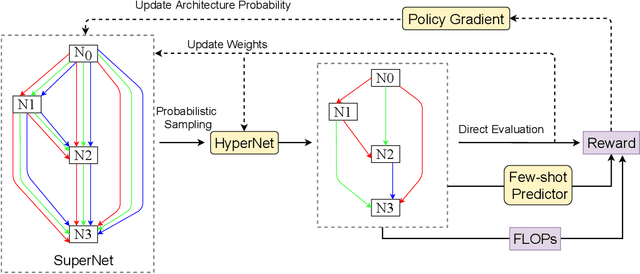
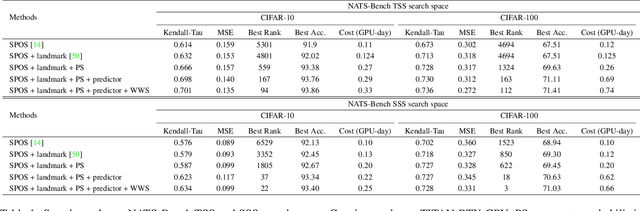
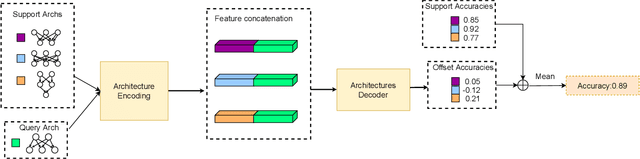
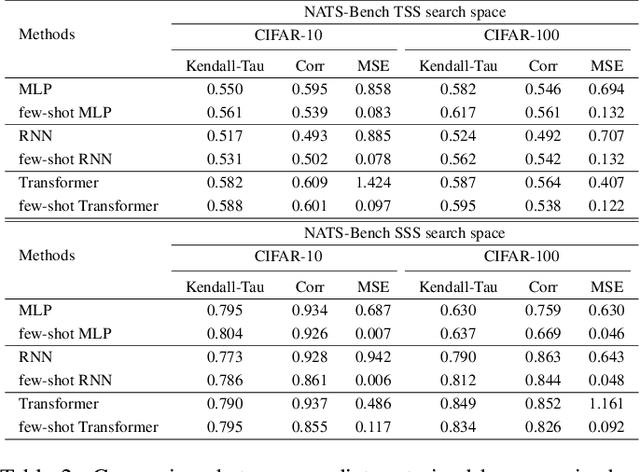
Weight sharing based and predictor based methods are two major types of fast neural architecture search methods. In this paper, we propose to jointly use weight sharing and predictor in a unified framework. First, we construct a SuperNet in a weight-sharing way and probabilisticly sample architectures from the SuperNet. To increase the correctness of the evaluation of architectures, besides direct evaluation using the inherited weights, we further apply a few-shot predictor to assess the architecture on the other hand. The final evaluation of the architecture is the combination of direct evaluation, the prediction from the predictor and the cost of the architecture. We regard the evaluation as a reward and apply a self-critical policy gradient approach to update the architecture probabilities. To further reduce the side effects of weight sharing, we propose a weakly weight sharing method by introducing another HyperNet. We conduct experiments on datasets including CIFAR-10, CIFAR-100 and ImageNet under NATS-Bench, DARTS and MobileNet search space. The proposed WPNAS method achieves state-of-the-art performance on these datasets.