 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCL-Reasoner-V1.5: Advancing Math Reasoning with Offline Reinforcement Learning
Jan 21, 2026We present PCL-Reasoner-V1.5, a 32-billion-parameter large language model (LLM) for mathematical reasoning. The model is built upon Qwen2.5-32B and refined via supervised fine-tuning (SFT) followed by reinforcement learning (RL). A central innovation is our proposed offline RL method, which provides superior training stability and efficiency over standard online RL methods such as GRPO. Our model achieves state-of-the-art performance among models post-trained on Qwen2.5-32B, attaining average accuracies of 90.9% on AIME 2024 and 85.6% on AIME 2025. Our work demonstrates offline RL as a stable and efficient paradigm for advancing reasoning in LLMs. All experiments were conducted on Huawei Ascend 910C NPUs.
Scaling Test-time Inference for Visual Grounding
Jan 20, 2026Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): a method to scale the test-time computation (#generated tokens). Scaling the test-time computation of a small model is deployment-friendly, and yields better end-to-end latency as the cost of each token is much cheaper compared to directly running a large model. On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to achieve 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method can consistently and significantly improve the vanilla grounding and amodal grounding capabilities of small models to be on par with or outperform the larger models, thereby improving the efficiency for visual grounding.
AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
Jan 12, 2026To meet the ever-increasing demand for computational efficiency, Neural Processing Units (NPUs) have become critical in modern AI infrastructure. However, unlocking their full potential requires developing high-performance compute kernels using vendor-specific Domain-Specific Languages (DSLs), a task that demands deep hardware expertise and is labor-intensive. While Large Language Models (LLMs) have shown promise in general code generation, they struggle with the strict constraints and scarcity of training data in the NPU domain. Our preliminary study reveals that state-of-the-art general-purpose LLMs fail to generate functional complex kernels for Ascend NPUs, yielding a near-zero success rate. To address these challenges, we propose AscendKernelGen, a generation-evaluation integrated framework for NPU kernel development. We introduce Ascend-CoT, a high-quality dataset incorporating chain-of-thought reasoning derived from real-world kernel implementations, and KernelGen-LM, a domain-adaptive model trained via supervised fine-tuning and reinforcement learning with execution feedback. Furthermore, we design NPUKernelBench, a comprehensive benchmark for assessing compilation, correctness, and performance across varying complexity levels. Experimental results demonstrate that our approach significantly bridges the gap between general LLMs and hardware-specific coding. Specifically, the compilation success rate on complex Level-2 kernels improves from 0% to 95.5% (Pass@10), while functional correctness achieves 64.3% compared to the baseline's complete failure. These results highlight the critical role of domain-specific reasoning and rigorous evaluation in automating accelerator-aware code generation.
Coding in a Bubble? Evaluating LLMs in Resolving Context Adaptation Bugs During Code Adaptation
Jan 10, 2026Code adaptation is a fundamental but challenging task in software development, requiring developers to modify existing code for new contexts. A key challenge is to resolve Context Adaptation Bugs (CtxBugs), which occurs when code correct in its original context violates constraints in the target environment. Unlike isolated bugs, CtxBugs cannot be resolved through local fixes and require cross-context reasoning to identify semantic mismatches. Overlooking them may lead to critical failures in adaptation. Although Large Language Models (LLMs) show great potential in automating code-related tasks, their ability to resolve CtxBugs remains a significant and unexplored obstacle to their practical use in code adaptation. To bridge this gap, we propose CtxBugGen, a novel framework for generating CtxBugs to evaluate LLMs. Its core idea is to leverage LLMs' tendency to generate plausible but context-free code when contextual constraints are absent. The framework generates CtxBugs through a four-step process to ensure their relevance and validity: (1) Adaptation Task Selection, (2) Task-specific Perturbation,(3) LLM-based Variant Generation and (4) CtxBugs Identification. Based on the benchmark constructed by CtxBugGen, we conduct an empirical study with four state-of-the-art LLMs. Our results reveal their unsatisfactory performance in CtxBug resolution. The best performing LLM, Kimi-K2, achieves 55.93% on Pass@1 and resolves just 52.47% of CtxBugs. The presence of CtxBugs degrades LLMs' adaptation performance by up to 30%. Failure analysis indicates that LLMs often overlook CtxBugs and replicate them in their outputs. Our study highlights a critical weakness in LLMs' cross-context reasoning and emphasize the need for new methods to enhance their context awareness for reliable code adaptation.
AdaptEval: A Benchmark for Evaluating Large Language Models on Code Snippet Adaptation
Jan 08, 2026Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
A New Benchmark for the Appropriate Evaluation of RTL Code Optimization
Jan 05, 2026The rapid progress of artificial intelligence increasingly relies on efficient integrated circuit (IC) design. Recent studies have explored the use of large language models (LLMs) for generating Register Transfer Level (RTL) code, but existing benchmarks mainly evaluate syntactic correctness rather than optimization quality in terms of power, performance, and area (PPA). This work introduces RTL-OPT, a benchmark for assessing the capability of LLMs in RTL optimization. RTL-OPT contains 36 handcrafted digital designs that cover diverse implementation categories including combinational logic, pipelined datapaths, finite state machines, and memory interfaces. Each task provides a pair of RTL codes, a suboptimal version and a human-optimized reference that reflects industry-proven optimization patterns not captured by conventional synthesis tools. Furthermore, RTL-OPT integrates an automated evaluation framework to verify functional correctness and quantify PPA improvements, enabling standardized and meaningful assessment of generative models for hardware design optimization.
The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining
Jan 01, 2026Multilingual large language models achieve impressive cross-lingual performance despite largely monolingual pretraining. While bilingual data in pretraining corpora is widely believed to enable these abilities, details of its contributions remain unclear. We investigate this question by pretraining models from scratch under controlled conditions, comparing the standard web corpus with a monolingual-only version that removes all multilingual documents. Despite constituting only 2% of the corpus, removing bilingual data causes translation performance to drop 56% in BLEU, while behaviour on cross-lingual QA and general reasoning tasks remains stable, with training curves largely overlapping the baseline. To understand this asymmetry, we categorize bilingual data into parallel (14%), code-switching (72%), and miscellaneous documents (14%) based on the semantic relevance of content in different languages. We then conduct granular ablations by reintroducing parallel or code-switching data into the monolingual-only corpus. Our experiments reveal that parallel data almost fully restores translation performance (91% of the unfiltered baseline), whereas code-switching contributes minimally. Other cross-lingual tasks remain largely unaffected by either type. These findings reveal that translation critically depends on systematic token-level alignments from parallel data, whereas cross-lingual understanding and reasoning appear to be achievable even without bilingual data.
LinkedOut: Linking World Knowledge Representation Out of Video LLM for Next-Generation Video Recommendation
Dec 18, 2025Video Large Language Models (VLLMs) unlock world-knowledge-aware video understanding through pretraining on internet-scale data and have already shown promise on tasks such as movie analysis and video question answering. However, deploying VLLMs for downstream tasks such as video recommendation remains challenging, since real systems require multi-video inputs, lightweight backbones, low-latency sequential inference, and rapid response. In practice, (1) decode-only generation yields high latency for sequential inference, (2) typical interfaces do not support multi-video inputs, and (3) constraining outputs to language discards fine-grained visual details that matter for downstream vision tasks. We argue that these limitations stem from the absence of a representation that preserves pixel-level detail while leveraging world knowledge. We present LinkedOut, a representation that extracts VLLM world knowledge directly from video to enable fast inference, supports multi-video histories, and removes the language bottleneck. LinkedOut extracts semantically grounded, knowledge-aware tokens from raw frames using VLLMs, guided by promptable queries and optional auxiliary modalities. We introduce a cross-layer knowledge fusion MoE that selects the appropriate level of abstraction from the rich VLLM features, enabling personalized, interpretable, and low-latency recommendation. To our knowledge, LinkedOut is the first VLLM-based video recommendation method that operates on raw frames without handcrafted labels, achieving state-of-the-art results on standard benchmarks. Interpretability studies and ablations confirm the benefits of layer diversity and layer-wise fusion, pointing to a practical path that fully leverages VLLM world-knowledge priors and visual reasoning for downstream vision tasks such as recommendation.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Leveraging Large Language Models for Career Mobility Analysis: A Study of Gender, Race, and Job Change Using U.S. Online Resume Profiles
Nov 15, 2025
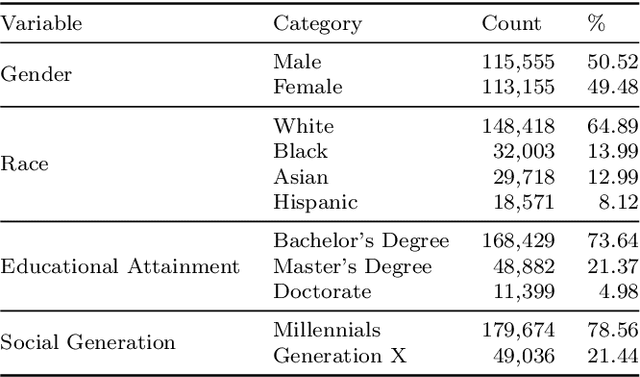


We present a large-scale analysis of career mobility of college-educated U.S. workers using online resume profiles to investigate how gender, race, and job change options are associated with upward mobility. This study addresses key research questions of how the job changes affect their upward career mobility, and how the outcomes of upward career mobility differ by gender and race. We address data challenges -- such as missing demographic attributes, missing wage data, and noisy occupation labels -- through various data processing and Artificial Intelligence (AI) methods. In particular, we develop a large language models (LLMs) based occupation classification method known as FewSOC that achieves accuracy significantly higher than the original occupation labels in the resume dataset. Analysis of 228,710 career trajectories reveals that intra-firm occupation change has been found to facilitate upward mobility most strongly, followed by inter-firm occupation change and inter-firm lateral move. Women and Black college graduates experience significantly lower returns from job changes than men and White peers. Multilevel sensitivity analyses confirm that these disparities are robust to cluster-level heterogeneity and reveal additional intersectional patterns.