 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded 3D-Aware Spatial Vision-Language Modeling
May 28, 2026We present GR3D, a spatial vision language model equipped with three complementary grounding capabilities--explicit 2D grounding, implicit 2D grounding, and monocular 3D grounding--within a single framework. GR3D introduces an implicit grounding mechanism that identifies entity mentions during generation and inserts the corresponding region tokens into the text stream, allowing the model to reference visual evidence on the fly when producing spatial chain-of-thought responses. In parallel, a region-prompted monocular 3D grounding design predicts 3D bounding boxes in the camera view from grounded region queries, supported by intrinsic-aware normalization and dense geometric supervision. Together, these grounding capabilities enable GR3D to decompose complex spatial understanding problems into grounded 2D perception followed by 3D inference. GR3D achieves consistent improvements across grounded and non-grounded spatial benchmarks, demonstrating grounding as an effective inductive bias for strengthening spatial understanding in VLMs. These grounding capabilities collectively enhance general spatial understanding beyond the grounding task itself.
JetViT: Efficient High-Resolution Vision Transformer with Post-Training Attention Search
May 26, 2026We introduce JetViT, a novel family of hybrid-architecture Vision Transformer (ViT) models that match the accuracy of state-of-the-art full-attention vision foundation models while achieving substantially higher inference efficiency on high-resolution images. At the core of our approach is Post-Training Attention Search, a post-training acceleration framework that converts pre-trained full-attention ViTs into efficient hybrid-attention variants by identifying and replacing redundant full-attention blocks with linear or window-attention blocks. By inheriting the MLP and attention weights from the base model, Post-Training Attention Search efficiently explores the architectural design space through three key steps: (1) optimizing the linear-attention block design; (2) finding the best combination of linear-attention and window-attention blocks; and (3) identifying and preserving critical full-attention blocks. We evaluate JetViT on two representative high-resolution vision foundation models, DINOv3 and DepthAnythingV2. On the NVIDIA H100 GPU, JetViT achieves up to 1.79x higher throughput and up to 44.81% lower latency without sacrificing accuracy. We will release our code and accelerated ViT models soon.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
UAV-DETR: DETR for Anti-Drone Target Detection
Mar 24, 2026Drone detection is pivotal in numerous security and counter-UAV applications. However, existing deep learning-based methods typically struggle to balance robust feature representation with computational efficiency. This challenge is particularly acute when detecting miniature drones against complex backgrounds under severe environmental interference. To address these issues, we introduce UAV-DETR, a novel framework that integrates a small-target-friendly architecture with real-time detection capabilities. Specifically, UAV-DETR features a WTConv-enhanced backbone and a Sliding Window Self-Attention (SWSA-IFI) encoder, capturing the high-frequency structural details of tiny targets while drastically reducing parameter overhead. Furthermore, we propose an Efficient Cross-Scale Feature Recalibration and Fusion Network (ECFRFN) to suppress background noise and aggregate multi-scale semantics. To further enhance accuracy, UAV-DETR incorporates a hybrid Inner-CIoU and NWD loss strategy, mitigating the extreme sensitivity of standard IoU metrics to minor positional deviations in small objects. Extensive experiments demonstrate that UAV-DETR significantly outperforms the baseline RT-DETR on our custom UAV dataset (+6.61% in mAP50:95, with a 39.8% reduction in parameters) and the public DUT-ANTI-UAV benchmark (+1.4% in Precision, +1.0% in F1-Score). These results establish UAV-DETR as a superior trade-off between efficiency and precision in counter-UAV object detection. The code is available at https://github.com/wd-sir/UAVDETR.
Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025



Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025

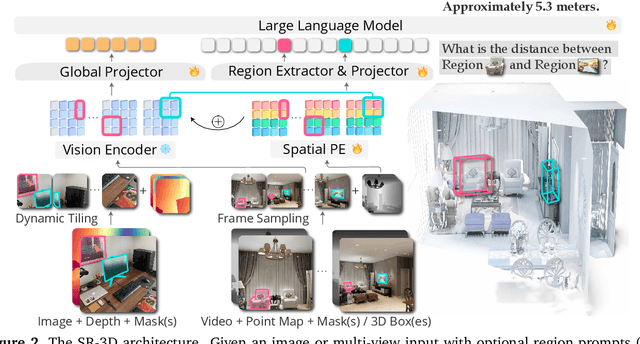

We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
Test-Time Scaling Strategies for Generative Retrieval in Multimodal Conversational Recommendations
Aug 25, 2025



The rapid evolution of e-commerce has exposed the limitations of traditional product retrieval systems in managing complex, multi-turn user interactions. Recent advances in multimodal generative retrieval -- particularly those leveraging multimodal large language models (MLLMs) as retrievers -- have shown promise. However, most existing methods are tailored to single-turn scenarios and struggle to model the evolving intent and iterative nature of multi-turn dialogues when applied naively. Concurrently, test-time scaling has emerged as a powerful paradigm for improving large language model (LLM) performance through iterative inference-time refinement. Yet, its effectiveness typically relies on two conditions: (1) a well-defined problem space (e.g., mathematical reasoning), and (2) the model's ability to self-correct -- conditions that are rarely met in conversational product search. In this setting, user queries are often ambiguous and evolving, and MLLMs alone have difficulty grounding responses in a fixed product corpus. Motivated by these challenges, we propose a novel framework that introduces test-time scaling into conversational multimodal product retrieval. Our approach builds on a generative retriever, further augmented with a test-time reranking (TTR) mechanism that improves retrieval accuracy and better aligns results with evolving user intent throughout the dialogue. Experiments across multiple benchmarks show consistent improvements, with average gains of 14.5 points in MRR and 10.6 points in nDCG@1.