 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODEBLOCK: Learning to Supervise Code at the Right Granularity
Jun 10, 2026Supervised fine-tuning of code LLMs typically applies uniform cross-entropy loss to all response tokens, implicitly assuming that every token provides equally useful learning signal. Recent token-level selection methods challenge this assumption in natural-language SFT by supervising only high-value tokens. However, directly transferring token-level masking to code can break syntactically and semantically coherent program units, because code depends on structural completeness and definition-use relations. We therefore propose CodeBlock, a structure-aware sparse supervision framework that selects structure-complete code evidence rather than isolated tokens. CodeBlock first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training, the full response remains available as context, while loss is applied only to selected code items and informative natural-language tokens. Experiments on six code-generation benchmarks show that CodeBlock achieves stronger average pass@1 than full-token SFT and competitive selection baselines, while using only 1.9% of supervised response tokens.
Provable Fairness Repair for Deep Neural Networks
May 19, 2026Deep neural networks (DNNs) are suffering from ethical issues such as individual discrimination. In response, extensive NN repair techniques have been developed to adjust models and mitigate such undesired behaviors. However, existing fairness repair methods are typically data-centric, which often lack provable guarantees and generalization to unseen samples. To overcome these limitations, we propose ProF, a novel fairness repair framework with provable guarantees. The key intuition of ProF is to leverage interval bound propagation (a widely used NN verification technique) to soundly capture model outputs over the whole set $S(\mathbf{x})$ around a biased sample $\mathbf{x}$. The derived bounds are utilized to guide fairness repair which encourages the model to produce consistent outputs on $S(\mathbf{x})$. Specifically, we integrate fairness constraints and model modifications into a unified constraint-solving formulation, which can be transformed to a Mixed-Integer Linear Programming (MILP) problem solvable by off-the-shelf solvers. The solution to the MILP problem effectively induces a repaired model with guaranteed fairness over the whole set $S(\mathbf{x})$. We evaluate ProF on four widely used benchmark datasets and demonstrate that it achieves provable fairness repair, with generalization of up to 95.93\% on full datasets and 93.16\% on the entire input space. Notably, ProF can be easily configured to support multiple sensitive attributes and more practical fairness definitions, while providing provable repair guarantees and delivering around 90\% fairness improvement. Our code is available at https://github.com/nninjn/ProF.
* 15 pages, 6 figures, 7 tables. full version of the paper accepted by ASE 2025
Learning How Much to Think: Difficulty-Aware Dynamic MoEs for Graph Node Classification
Apr 13, 2026Mixture-of-Experts (MoE) architectures offer a scalable path for Graph Neural Networks (GNNs) in node classification tasks but typically rely on static and rigid routing strategies that enforce a uniform expert budget or coarse-grained expert toggles on all nodes. This limitation overlooks the varying discriminative difficulty of nodes and leads to under-fitting for hard nodes and redundant computation for easy ones. To resolve this issue, we propose D2MoE, a novel framework that shifts the focus from static expert selection to node-wise expert resource allocation. By using predictive entropy as a real-time proxy for difficulty, D2MoE employs a difficulty-driven top-p routing mechanism to adaptively concentrate expert resources on hard nodes while reducing overhead for easy ones, achieving continuous and fine-grained expert budget scaling for node classification. Experiments on 13 benchmarks demonstrate that D2MoE achieves consistent state-of-the-art performance, surpassing leading baselines by up to 7.92% in accuracy on heterophilous graphs. Notably, on large-scale graphs, it reduces memory consumption by up to 73.07% and training time by 46.53% compared to the best-performing Graph MoE, thereby validating its superior efficiency.
CrossHGL: A Text-Free Foundation Model for Cross-Domain Heterogeneous Graph Learning
Mar 29, 2026Heterogeneous graph representation learning (HGRL) is essential for modeling complex systems with diverse node and edge types. However, most existing methods are limited to closed-world settings with shared schemas and feature spaces, hindering cross-domain generalization. While recent graph foundation models improve transferability, they often target homogeneous graphs, rely on domain-specific schemas, or require rich textual attributes. Consequently, text-free and few-shot cross-domain HGRL remains underexplored. To address this, we propose CrossHGL, a foundation framework that preserves and transfers multi-relational structural semantics without external textual supervision. Specifically, a semantic-preserving transformation strategy homogenizes heterogeneous graphs while encoding interaction semantics into edge features. Based on this, a prompt-aware multi-domain pre-training framework with a Tri-Prompt mechanism captures transferable knowledge across feature, edge, and structure perspectives via self-supervised contrastive learning. For target-domain adaptation, we develop a parameter-efficient fine-tuning strategy that freezes the pre-trained backbone and performs few-shot classification via prompt composition and prototypical learning. Experiments on node-level and graph-level tasks show that CrossHGL consistently outperforms state-of-the-art baselines, yielding average relative improvements of 25.1% and 7.6% in Micro-F1 for node and graph classification, respectively, while remaining competitive in challenging feature-degenerated settings.
RealHD: A High-Quality Dataset for Robust Detection of State-of-the-Art AI-Generated Images
Feb 11, 2026The rapid advancement of generative AI has raised concerns about the authenticity of digital images, as highly realistic fake images can now be generated at low cost, potentially increasing societal risks. In response, several datasets have been established to train detection models aimed at distinguishing AI-generated images from real ones. However, existing datasets suffer from limited generalization, low image quality, overly simple prompts, and insufficient image diversity. To address these limitations, we propose a high-quality, large-scale dataset comprising over 730,000 images across multiple categories, including both real and AI-generated images. The generated images are synthesized via state-of-the-art methods, including text-to-image generation (guided by over 10,000 carefully designed prompts), image inpainting, image refinement, and face swapping. Each generated image is annotated with its generation method and category. Inpainting images further include binary masks to indicate inpainted regions, providing rich metadata for analysis. Compared to existing datasets, detection models trained on our dataset demonstrate superior generalization capabilities. Our dataset not only serves as a strong benchmark for evaluating detection methods but also contributes to advancing the robustness of AI-generated image detection techniques. Building upon this, we propose a lightweight detection method based on image noise entropy, which transforms the original image into an entropy tensor of Non-Local Means (NLM) noise before classification. Extensive experiments demonstrate that models trained on our dataset achieve strong generalization, and our method delivers competitive performance, establishing a solid baseline for future research. The dataset and source code are publicly available at https://real-hd.github.io.
* Published in the Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM 2025)
Improving the Convergence Rate of Ray Search Optimization for Query-Efficient Hard-Label Attacks
Dec 24, 2025In hard-label black-box adversarial attacks, where only the top-1 predicted label is accessible, the prohibitive query complexity poses a major obstacle to practical deployment. In this paper, we focus on optimizing a representative class of attacks that search for the optimal ray direction yielding the minimum $\ell_2$-norm perturbation required to move a benign image into the adversarial region. Inspired by Nesterov's Accelerated Gradient (NAG), we propose a momentum-based algorithm, ARS-OPT, which proactively estimates the gradient with respect to a future ray direction inferred from accumulated momentum. We provide a theoretical analysis of its convergence behavior, showing that ARS-OPT enables more accurate directional updates and achieves faster, more stable optimization. To further accelerate convergence, we incorporate surrogate-model priors into ARS-OPT's gradient estimation, resulting in PARS-OPT with enhanced performance. The superiority of our approach is supported by theoretical guarantees under standard assumptions. Extensive experiments on ImageNet and CIFAR-10 demonstrate that our method surpasses 13 state-of-the-art approaches in query efficiency.
\emph{FoQuS}: A Forgetting-Quality Coreset Selection Framework for Automatic Modulation Recognition
Sep 10, 2025Deep learning-based Automatic Modulation Recognition (AMR) model has made significant progress with the support of large-scale labeled data. However, when developing new models or performing hyperparameter tuning, the time and energy consumption associated with repeated training using massive amounts of data are often unbearable. To address the above challenges, we propose \emph{FoQuS}, which approximates the effect of full training by selecting a coreset from the original dataset, thereby significantly reducing training overhead. Specifically, \emph{FoQuS} records the prediction trajectory of each sample during full-dataset training and constructs three importance metrics based on training dynamics. Experiments show that \emph{FoQuS} can maintain high recognition accuracy and good cross-architecture generalization on multiple AMR datasets using only 1\%-30\% of the original data.
Boosting Ray Search Procedure of Hard-label Attacks with Transfer-based Priors
Jul 23, 2025One of the most practical and challenging types of black-box adversarial attacks is the hard-label attack, where only the top-1 predicted label is available. One effective approach is to search for the optimal ray direction from the benign image that minimizes the $\ell_p$-norm distance to the adversarial region. The unique advantage of this approach is that it transforms the hard-label attack into a continuous optimization problem. The objective function value is the ray's radius, which can be obtained via binary search at a high query cost. Existing methods use a "sign trick" in gradient estimation to reduce the number of queries. In this paper, we theoretically analyze the quality of this gradient estimation and propose a novel prior-guided approach to improve ray search efficiency both theoretically and empirically. Specifically, we utilize the transfer-based priors from surrogate models, and our gradient estimators appropriately integrate them by approximating the projection of the true gradient onto the subspace spanned by these priors and random directions, in a query-efficient manner. We theoretically derive the expected cosine similarities between the obtained gradient estimators and the true gradient, and demonstrate the improvement achieved by incorporating priors. Extensive experiments on the ImageNet and CIFAR-10 datasets show that our approach significantly outperforms 11 state-of-the-art methods in terms of query efficiency.
DUSE: A Data Expansion Framework for Low-resource Automatic Modulation Recognition based on Active Learning
Jul 16, 2025Although deep neural networks have made remarkable achievements in the field of automatic modulation recognition (AMR), these models often require a large amount of labeled data for training. However, in many practical scenarios, the available target domain data is scarce and difficult to meet the needs of model training. The most direct way is to collect data manually and perform expert annotation, but the high time and labor costs are unbearable. Another common method is data augmentation. Although it can enrich training samples to a certain extent, it does not introduce new data and therefore cannot fundamentally solve the problem of data scarcity. To address these challenges, we introduce a data expansion framework called Dynamic Uncertainty-driven Sample Expansion (DUSE). Specifically, DUSE uses an uncertainty scoring function to filter out useful samples from relevant AMR datasets and employs an active learning strategy to continuously refine the scorer. Extensive experiments demonstrate that DUSE consistently outperforms 8 coreset selection baselines in both class-balance and class-imbalance settings. Besides, DUSE exhibits strong cross-architecture generalization for unseen models.
Better Reasoning with Less Data: Enhancing VLMs Through Unified Modality Scoring
Jun 10, 2025

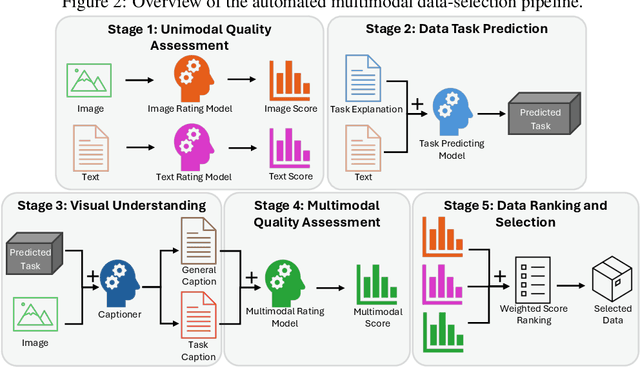

The application of visual instruction tuning and other post-training techniques has significantly enhanced the capabilities of Large Language Models (LLMs) in visual understanding, enriching Vision-Language Models (VLMs) with more comprehensive visual language datasets. However, the effectiveness of VLMs is highly dependent on large-scale, high-quality datasets that ensure precise recognition and accurate reasoning. Two key challenges hinder progress: (1) noisy alignments between images and the corresponding text, which leads to misinterpretation, and (2) ambiguous or misleading text, which obscures visual content. To address these challenges, we propose SCALE (Single modality data quality and Cross modality Alignment Evaluation), a novel quality-driven data selection pipeline for VLM instruction tuning datasets. Specifically, SCALE integrates a cross-modality assessment framework that first assigns each data entry to its appropriate vision-language task, generates general and task-specific captions (covering scenes, objects, style, etc.), and evaluates the alignment, clarity, task rarity, text coherence, and image clarity of each entry based on the generated captions. We reveal that: (1) current unimodal quality assessment methods evaluate one modality while overlooking the rest, which can underestimate samples essential for specific tasks and discard the lower-quality instances that help build model robustness; and (2) appropriately generated image captions provide an efficient way to transfer the image-text multimodal task into a unified text modality.