 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Soil Macronutrient Levels: A Machine Learning Approach Models Trained on pH, Conductivity, and Average Power of Acid-Base Solutions
Apr 05, 2025



Soil macronutrients, particularly potassium ions (K$^+$), are indispensable for plant health, underpinning various physiological and biological processes, and facilitating the management of both biotic and abiotic stresses. Deficient macronutrient content results in stunted growth, delayed maturation, and increased vulnerability to environmental stressors, thereby accentuating the imperative for precise soil nutrient monitoring. Traditional techniques such as chemical assays, atomic absorption spectroscopy, inductively coupled plasma optical emission spectroscopy, and electrochemical methods, albeit advanced, are prohibitively expensive and time-intensive, thus unsuitable for real-time macronutrient assessment. In this study, we propose an innovative soil testing protocol utilizing a dataset derived from synthetic solutions to model soil behaviour. The dataset encompasses physical properties including conductivity and pH, with a concentration on three key macronutrients: nitrogen (N), phosphorus (P), and potassium (K). Four machine learning algorithms were applied to the dataset, with random forest regressors and neural networks being selected for the prediction of soil nutrient concentrations. Comparative analysis with laboratory soil testing results revealed prediction errors of 23.6% for phosphorus and 16% for potassium using the random forest model, and 26.3% for phosphorus and 21.8% for potassium using the neural network model. This methodology illustrates a cost-effective and efficacious strategy for real-time soil nutrient monitoring, offering substantial advancements over conventional techniques and enhancing the capability to sustain optimal nutrient levels conducive to robust crop growth.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025
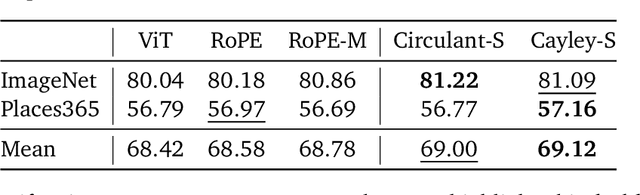
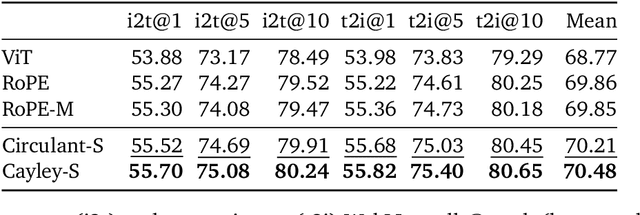

We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Modeling the Real World with High-Density Visual Particle Dynamics
Jun 28, 2024



We present High-Density Visual Particle Dynamics (HD-VPD), a learned world model that can emulate the physical dynamics of real scenes by processing massive latent point clouds containing 100K+ particles. To enable efficiency at this scale, we introduce a novel family of Point Cloud Transformers (PCTs) called Interlacers leveraging intertwined linear-attention Performer layers and graph-based neighbour attention layers. We demonstrate the capabilities of HD-VPD by modeling the dynamics of high degree-of-freedom bi-manual robots with two RGB-D cameras. Compared to the previous graph neural network approach, our Interlacer dynamics is twice as fast with the same prediction quality, and can achieve higher quality using 4x as many particles. We illustrate how HD-VPD can evaluate motion plan quality with robotic box pushing and can grasping tasks. See videos and particle dynamics rendered by HD-VPD at https://sites.google.com/view/hd-vpd.
Structured Unrestricted-Rank Matrices for Parameter Efficient Fine-tuning
Jun 25, 2024



Recent efforts to scale Transformer models have demonstrated rapid progress across a wide range of tasks (Wei et al., 2022). However, fine-tuning these models for downstream tasks is expensive due to their large parameter counts. Parameter-efficient fine-tuning (PEFT) approaches have emerged as a viable alternative by allowing us to fine-tune models by updating only a small number of parameters. In this work, we propose a general framework for parameter efficient fine-tuning (PEFT), based on structured unrestricted-rank matrices (SURM) which can serve as a drop-in replacement for popular approaches such as Adapters and LoRA. Unlike other methods like LoRA, SURMs provides more flexibility in finding the right balance between compactness and expressiveness. This is achieved by using low displacement rank matrices (LDRMs), which hasn't been used in this context before. SURMs remain competitive with baselines, often providing significant quality improvements while using a smaller parameter budget. SURMs achieve 5-7% accuracy gains on various image classification tasks while replacing low-rank matrices in LoRA. It also results in up to 12x reduction of the number of parameters in adapters (with virtually no loss in quality) on the GLUE benchmark.
Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
Apr 04, 2024We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention
Dec 04, 2023



We present Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT): a new paradigm for addressing the emerging challenge of scaling up Robotics Transformers (RT) for on-robot deployment. SARA-RT relies on the new method of fine-tuning proposed by us, called up-training. It converts pre-trained or already fine-tuned Transformer-based robotic policies of quadratic time complexity (including massive billion-parameter vision-language-action models or VLAs), into their efficient linear-attention counterparts maintaining high quality. We demonstrate the effectiveness of SARA-RT by speeding up: (a) the class of recently introduced RT-2 models, the first VLA robotic policies pre-trained on internet-scale data, as well as (b) Point Cloud Transformer (PCT) robotic policies operating on large point clouds. We complement our results with the rigorous mathematical analysis providing deeper insight into the phenomenon of SARA.
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.