 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025



Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR Evaluation
Nov 19, 2025We introduce FinCriticalED (Financial Critical Error Detection), a visual benchmark for evaluating OCR and vision language models on financial documents at the fact level. Financial documents contain visually dense and table heavy layouts where numerical and temporal information is tightly coupled with structure. In high stakes settings, small OCR mistakes such as sign inversion or shifted dates can lead to materially different interpretations, while traditional OCR metrics like ROUGE and edit distance capture only surface level text similarity. \ficriticaled provides 500 image-HTML pairs with expert annotated financial facts covering over seven hundred numerical and temporal facts. It introduces three key contributions. First, it establishes the first fact level evaluation benchmark for financial document understanding, shifting evaluation from lexical overlap to domain critical factual correctness. Second, all annotations are created and verified by financial experts with strict quality control over signs, magnitudes, and temporal expressions. Third, we develop an LLM-as-Judge evaluation pipeline that performs structured fact extraction and contextual verification for visually complex financial documents. We benchmark OCR systems, open source vision language models, and proprietary models on FinCriticalED. Results show that although the strongest proprietary models achieve the highest factual accuracy, substantial errors remain in visually intricate numerical and temporal contexts. Through quantitative evaluation and expert case studies, FinCriticalED provides a rigorous foundation for advancing visual factual precision in financial and other precision critical domains.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025



Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
DualFete: Revisiting Teacher-Student Interactions from a Feedback Perspective for Semi-supervised Medical Image Segmentation
Nov 12, 2025The teacher-student paradigm has emerged as a canonical framework in semi-supervised learning. When applied to medical image segmentation, the paradigm faces challenges due to inherent image ambiguities, making it particularly vulnerable to erroneous supervision. Crucially, the student's iterative reconfirmation of these errors leads to self-reinforcing bias. While some studies attempt to mitigate this bias, they often rely on external modifications to the conventional teacher-student framework, overlooking its intrinsic potential for error correction. In response, this work introduces a feedback mechanism into the teacher-student framework to counteract error reconfirmations. Here, the student provides feedback on the changes induced by the teacher's pseudo-labels, enabling the teacher to refine these labels accordingly. We specify that this interaction hinges on two key components: the feedback attributor, which designates pseudo-labels triggering the student's update, and the feedback receiver, which determines where to apply this feedback. Building on this, a dual-teacher feedback model is further proposed, which allows more dynamics in the feedback loop and fosters more gains by resolving disagreements through cross-teacher supervision while avoiding consistent errors. Comprehensive evaluations on three medical image benchmarks demonstrate the method's effectiveness in addressing error propagation in semi-supervised medical image segmentation.
Compression then Matching: An Efficient Pre-training Paradigm for Multimodal Embedding
Nov 11, 2025Vision-language models advance multimodal representation learning by acquiring transferable semantic embeddings, thereby substantially enhancing performance across a range of vision-language tasks, including cross-modal retrieval, clustering, and classification. An effective embedding is expected to comprehensively preserve the semantic content of the input while simultaneously emphasizing features that are discriminative for downstream tasks. Recent approaches demonstrate that VLMs can be adapted into competitive embedding models via large-scale contrastive learning, enabling the simultaneous optimization of two complementary objectives. We argue that the two aforementioned objectives can be decoupled: a comprehensive understanding of the input facilitates the embedding model in achieving superior performance in downstream tasks via contrastive learning. In this paper, we propose CoMa, a compressed pre-training phase, which serves as a warm-up stage for contrastive learning. Experiments demonstrate that with only a small amount of pre-training data, we can transform a VLM into a competitive embedding model. CoMa achieves new state-of-the-art results among VLMs of comparable size on the MMEB, realizing optimization in both efficiency and effectiveness.
WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation
Nov 09, 2025User interface (UI) development requires translating design mockups into functional code, a process that remains repetitive and labor-intensive. While recent Vision-Language Models (VLMs) automate UI-to-Code generation, they generate only static HTML/CSS/JavaScript layouts lacking interactivity. To address this, we propose WebVIA, the first agentic framework for interactive UI-to-Code generation and validation. The framework comprises three components: 1) an exploration agent to capture multi-state UI screenshots; 2) a UI2Code model that generates executable interactive code; 3) a validation module that verifies the interactivity. Experiments demonstrate that WebVIA-Agent achieves more stable and accurate UI exploration than general-purpose agents (e.g., Gemini-2.5-Pro). In addition, our fine-tuned WebVIA-UI2Code models exhibit substantial improvements in generating executable and interactive HTML/CSS/JavaScript code, outperforming their base counterparts across both interactive and static UI2Code benchmarks. Our code and models are available at \href{https://zheny2751-dotcom.github.io/webvia.github.io/}{\texttt{https://webvia.github.io}}.
V-Shuffle: Zero-Shot Style Transfer via Value Shuffle
Nov 09, 2025



Attention injection-based style transfer has achieved remarkable progress in recent years. However, existing methods often suffer from content leakage, where the undesired semantic content of the style image mistakenly appears in the stylized output. In this paper, we propose V-Shuffle, a zero-shot style transfer method that leverages multiple style images from the same style domain to effectively navigate the trade-off between content preservation and style fidelity. V-Shuffle implicitly disrupts the semantic content of the style images by shuffling the value features within the self-attention layers of the diffusion model, thereby preserving low-level style representations. We further introduce a Hybrid Style Regularization that complements these low-level representations with high-level style textures to enhance style fidelity. Empirical results demonstrate that V-Shuffle achieves excellent performance when utilizing multiple style images. Moreover, when applied to a single style image, V-Shuffle outperforms previous state-of-the-art methods.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025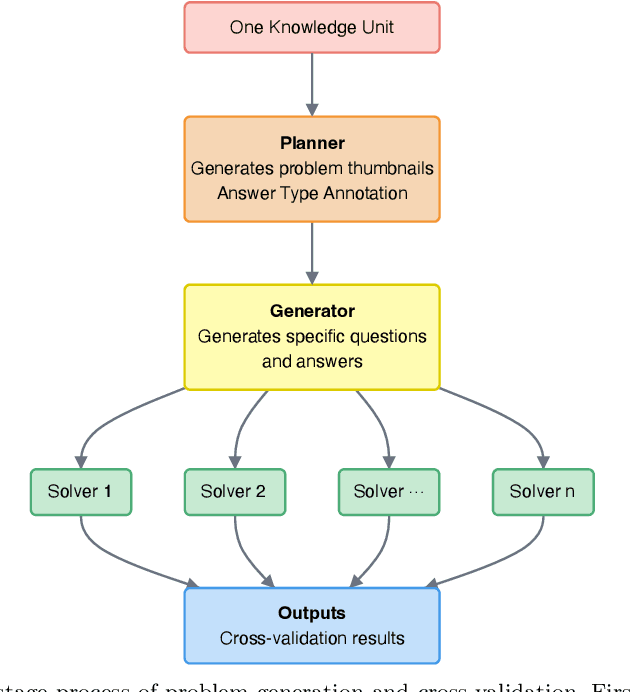
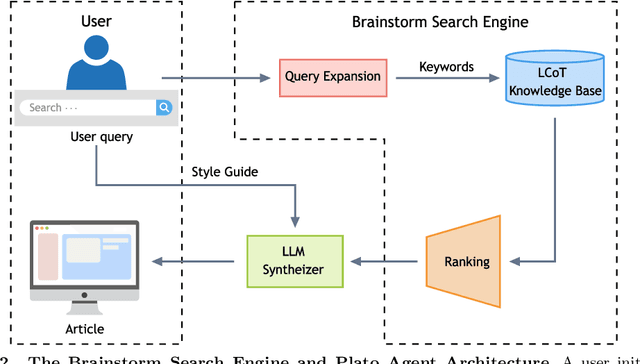
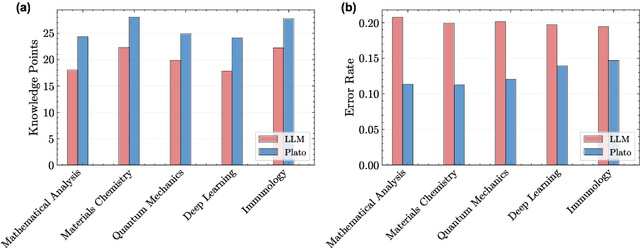
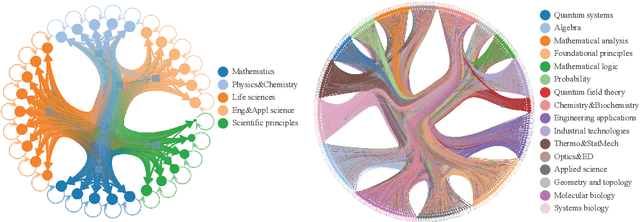
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025



The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Addressing Mark Imbalance in Integration-free Neural Marked Temporal Point Processes
Oct 23, 2025Marked Temporal Point Process (MTPP) has been well studied to model the event distribution in marked event streams, which can be used to predict the mark and arrival time of the next event. However, existing studies overlook that the distribution of event marks is highly imbalanced in many real-world applications, with some marks being frequent but others rare. The imbalance poses a significant challenge to the performance of the next event prediction, especially for events of rare marks. To address this issue, we propose a thresholding method, which learns thresholds to tune the mark probability normalized by the mark's prior probability to optimize mark prediction, rather than predicting the mark directly based on the mark probability as in existing studies. In conjunction with this method, we predict the mark first and then the time. In particular, we develop a novel neural MTPP model to support effective time sampling and estimation of mark probability without computationally expensive numerical improper integration. Extensive experiments on real-world datasets demonstrate the superior performance of our solution against various baselines for the next event mark and time prediction. The code is available at https://github.com/undes1red/IFNMTPP.