 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Jun 09, 2026Conventional LLMs keep the full KV cache loaded during decoding, causing a severe GPU memory bottleneck for ultra-long context serving. In this report, we propose Lookahead Sparse Attention (LSA), a novel inference paradigm powered by a Neural Memory Indexer built upon the DeepSeek-V4 architecture. Rather than passively attending to all historical tokens, LSA proactively predicts future context demands and preserves only the query-critical KV chunks in the GPU memory. Crucially, we instantiate this architecture via a backbone-free decoupled training strategy. By formulating the indexer as a standard dual-encoder architecture, we train it independently using standard retrieval training frameworks without ever loading the massive backbone model into GPU memory. We demonstrate that this "less is more" paradigm significantly maximizes serving efficiency while acting as an effective attention denoiser in tasks that rely on long-term global memory. Across primary long-context evaluation suites (e.g., LongBench-v2, LongMemEval, and RULER), FM-DS-V4 compresses the average physical KV cache footprint down to merely 13.5% of the full-context baseline, while consistently preserving or slightly elevating downstream accuracy (+0.6% absolute margin on average). Crucially, at extreme 500K scales, FlashMemory suppresses the physical KV cache overhead by over 90% without destabilizing the backbone's core reasoning capacities.
Training LLM Agents for Spontaneous, Reward-Free Self-Evolution via World Knowledge Exploration
Apr 20, 2026Most agents today ``self-evolve'' by following rewards and rules defined by humans. However, this process remains fundamentally dependent on external supervision; without human guidance, the evolution stops. In this work, we train agents to possess an intrinsic meta-evolution capability to spontaneously learn about unseen environments prior to task execution. To instill this ability, we design an outcome-based reward mechanism that measures how much an agent's self-generated world knowledge improves its success rate on downstream tasks. This reward signal is used exclusively during the training phase to teach the model how to explore and summarize effectively. At inference time, the agent requires no external rewards or human instructions. It spontaneously performs native self-evolution to adapt to unknown environments using its internal parameters. When applied to Qwen3-30B and Seed-OSS-36B, this shift to native evolution yields a 20% performance increase on WebVoyager and WebWalker. Most strikingly, the generated world knowledge even enables a compact 14B Qwen3 model to outperform the unassisted Gemini-2.5-Flash, establishing a new paradigm for truly evolving agents.
Adaptive Spiking Neurons for Vision and Language Modeling
Apr 14, 2026Regarded as the third generation of neural networks, Spiking Neural Networks (SNNs) have garnered significant traction due to their biological plausibility and energy efficiency. Recent advancements in large models necessitate spiking neurons capable of high performance, adaptability, and training efficiency. In this work, we first propose a novel functional perspective that provides general guidance for designing the new generation of spiking neurons. Following the insightful guidelines, we propose the Adaptive Spiking Neuron (ASN), which incorporates trainable parameters to learn membrane potential dynamics and enable adaptive firing. ASN adopts an integer training and spike inference paradigm, facilitating efficient SNN training. To further enhance robustness, we propose a specialized variant of ASN, the Normalized Adaptive Spiking Neuron (NASN), which integrates normalization to stabilize training. We evaluate our neuron model on 19 datasets spanning five distinct tasks in both vision and language modalities, demonstrating the effectiveness and versatility of the ASN family. Our ASN family is expected to become the new generation of general-purpose spiking neurons.
Winner-Take-All Spiking Transformer for Language Modeling
Apr 13, 2026Spiking Transformers, which combine the scalability of Transformers with the sparse, energy-efficient property of Spiking Neural Networks (SNNs), have achieved impressive results in neuromorphic and vision tasks and attracted increasing attention. However, existing directly trained spiking transformers primarily focus on vision tasks. For language modeling with spiking transformer, convergence relies heavily on softmax-based spiking self-attention, which incurs high energy costs and poses challenges for neuromorphic deployment. To address this issue, we introduce Winner-Take-All (WTA) mechanisms into spiking transformers and propose two novel softmax-free, spike-driven self-attention modules: WTA Spiking Self-Attention (WSSA) and Causal WTA Spiking Self-Attention (CWSSA). Based on them, we design WTA-based Encoder-only Spiking Transformer (WE-Spikingformer) for masked language modeling and WTA-based Decoder-only Spiking Transformer (WD-Spikingformer) for causal language modeling, systematically exploring softmax-free, spiking-driven Transformer architectures trained end-to-end for natural language processing tasks. Extensive experiments on 16 datasets spanning natural language understanding, question-answering tasks, and commonsense reasoning tasks validate the effectiveness of our approach and highlight the promise of spiking transformers for general language modeling and energy-efficient artificial intelligence.
The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
Feb 12, 2026In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.
Free(): Learning to Forget in Malloc-Only Reasoning Models
Feb 08, 2026Reasoning models enhance problem-solving by scaling test-time compute, yet they face a critical paradox: excessive thinking tokens often degrade performance rather than improve it. We attribute this to a fundamental architectural flaw: standard LLMs operate as "malloc-only" engines, continuously accumulating valid and redundant steps alike without a mechanism to prune obsolete information. To break this cycle, we propose Free()LM, a model that introduces an intrinsic self-forgetting capability via the Free-Module, a plug-and-play LoRA adapter. By iteratively switching between reasoning and cleaning modes, Free()LM dynamically identifies and prunes useless context chunks, maintaining a compact and noise-free state. Extensive experiments show that Free()LM provides consistent improvements across all model scales (8B to 685B). It achieves a 3.3% average improvement over top-tier reasoning baselines, even establishing a new SOTA on IMOanswerBench using DeepSeek V3.2-Speciale. Most notably, in long-horizon tasks where the standard Qwen3-235B-A22B model suffers a total collapse (0% accuracy), Free()LM restores performance to 50%. Our findings suggest that sustainable intelligence requires the freedom to forget as much as the power to think.
Locas: Your Models are Principled Initializers of Locally-Supported Parametric Memories
Feb 04, 2026In this paper, we aim to bridge test-time-training with a new type of parametric memory that can be flexibly offloaded from or merged into model parameters. We present Locas, a Locally-Supported parametric memory that shares the design of FFN blocks in modern transformers, allowing it to be flexibly permanentized into the model parameters while supporting efficient continual learning. We discuss two major variants of Locas: one with a conventional two-layer MLP design that has a clearer theoretical guarantee; the other one shares the same GLU-FFN structure with SOTA LLMs, and can be easily attached to existing models for both parameter-efficient and computation-efficient continual learning. Crucially, we show that proper initialization of such low-rank sideway-FFN-style memories -- performed in a principled way by reusing model parameters, activations and/or gradients -- is essential for fast convergence, improved generalization, and catastrophic forgetting prevention. We validate the proposed memory mechanism on the PG-19 whole-book language modeling and LoCoMo long-context dialogue question answering tasks. With only 0.02\% additional parameters in the lowest case, Locas-GLU is capable of storing the information from past context while maintaining a much smaller context window. In addition, we also test the model's general capability loss after memorizing the whole book with Locas, through comparative MMLU evaluation. Results show the promising ability of Locas to permanentize past context into parametric knowledge with minimized catastrophic forgetting of the model's existing internal knowledge.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025



The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Effidit: Your AI Writing Assistant
Aug 04, 2022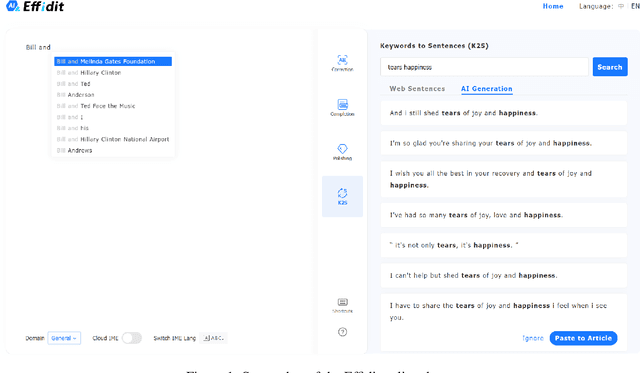
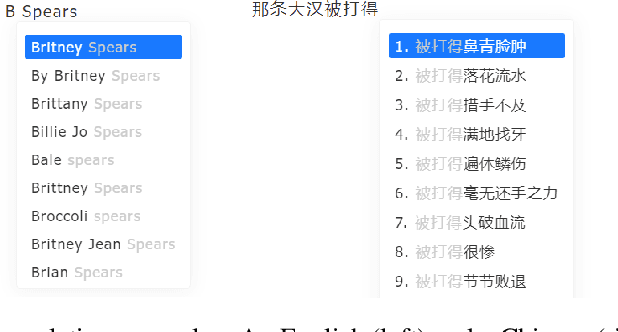

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.