 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025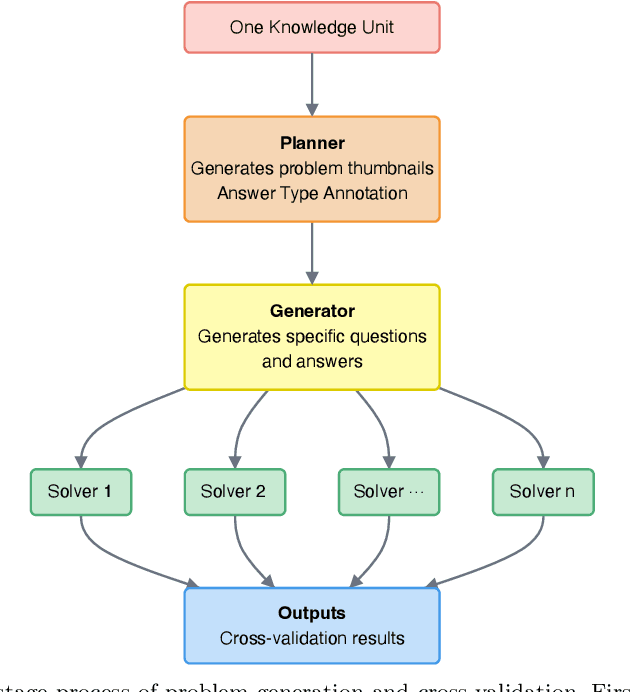
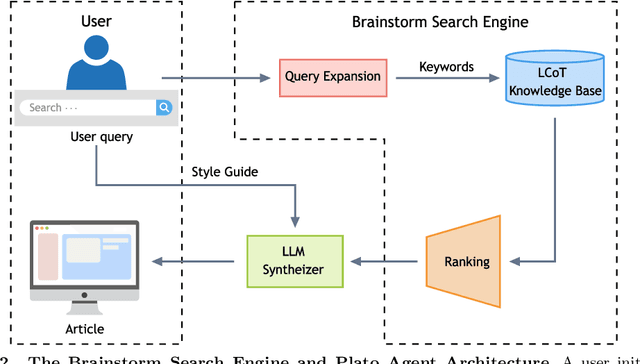
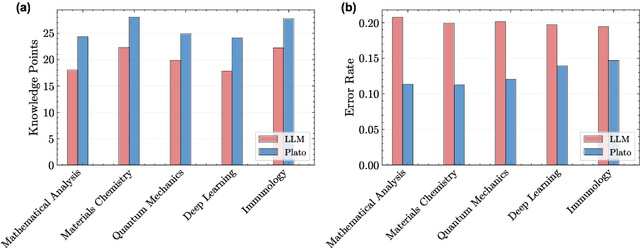
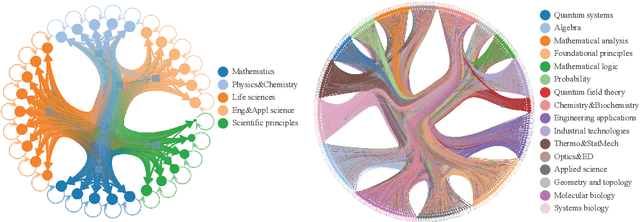
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.