 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanation for Regression via Disentanglement in Latent Space
Nov 23, 2023



Counterfactual Explanations (CEs) help address the question: How can the factors that influence the prediction of a predictive model be changed to achieve a more favorable outcome from a user's perspective? Thus, they bear the potential to guide the user's interaction with AI systems since they represent easy-to-understand explanations. To be applicable, CEs need to be realistic and actionable. In the literature, various methods have been proposed to generate CEs. However, the majority of research on CEs focuses on classification problems where questions like "What should I do to get my rejected loan approved?" are raised. In practice, answering questions like "What should I do to increase my salary?" are of a more regressive nature. In this paper, we introduce a novel method to generate CEs for a pre-trained regressor by first disentangling the label-relevant from the label-irrelevant dimensions in the latent space. CEs are then generated by combining the label-irrelevant dimensions and the predefined output. The intuition behind this approach is that the ideal counterfactual search should focus on the label-irrelevant characteristics of the input and suggest changes toward target-relevant characteristics. Searching in the latent space could help achieve this goal. We show that our method maintains the characteristics of the query sample during the counterfactual search. In various experiments, we demonstrate that the proposed method is competitive based on different quality measures on image and tabular datasets in regression problem settings. It efficiently returns results closer to the original data manifold compared to three state-of-the-art methods, which is essential for realistic high-dimensional machine learning applications. Our code will be made available as an open-source package upon the publication of this work.
Adversarial Reweighting Guided by Wasserstein Distance for Bias Mitigation
Nov 21, 2023



The unequal representation of different groups in a sample population can lead to discrimination of minority groups when machine learning models make automated decisions. To address these issues, fairness-aware machine learning jointly optimizes two (or more) metrics aiming at predictive effectiveness and low unfairness. However, the inherent under-representation of minorities in the data makes the disparate treatment of subpopulations less noticeable and difficult to deal with during learning. In this paper, we propose a novel adversarial reweighting method to address such \emph{representation bias}. To balance the data distribution between the majority and the minority groups, our approach deemphasizes samples from the majority group. To minimize empirical risk, our method prefers samples from the majority group that are close to the minority group as evaluated by the Wasserstein distance. Our theoretical analysis shows the effectiveness of our adversarial reweighting approach. Experiments demonstrate that our approach mitigates bias without sacrificing classification accuracy, outperforming related state-of-the-art methods on image and tabular benchmark datasets.
Causal Fairness-Guided Dataset Reweighting using Neural Networks
Nov 17, 2023



The importance of achieving fairness in machine learning models cannot be overstated. Recent research has pointed out that fairness should be examined from a causal perspective, and several fairness notions based on the on Pearl's causal framework have been proposed. In this paper, we construct a reweighting scheme of datasets to address causal fairness. Our approach aims at mitigating bias by considering the causal relationships among variables and incorporating them into the reweighting process. The proposed method adopts two neural networks, whose structures are intentionally used to reflect the structures of a causal graph and of an interventional graph. The two neural networks can approximate the causal model of the data, and the causal model of interventions. Furthermore, reweighting guided by a discriminator is applied to achieve various fairness notions. Experiments on real-world datasets show that our method can achieve causal fairness on the data while remaining close to the original data for downstream tasks.
Counterfactual Explanation via Search in Gaussian Mixture Distributed Latent Space
Jul 25, 2023



Counterfactual Explanations (CEs) are an important tool in Algorithmic Recourse for addressing two questions: 1. What are the crucial factors that led to an automated prediction/decision? 2. How can these factors be changed to achieve a more favorable outcome from a user's perspective? Thus, guiding the user's interaction with AI systems by proposing easy-to-understand explanations and easy-to-attain feasible changes is essential for the trustworthy adoption and long-term acceptance of AI systems. In the literature, various methods have been proposed to generate CEs, and different quality measures have been suggested to evaluate these methods. However, the generation of CEs is usually computationally expensive, and the resulting suggestions are unrealistic and thus non-actionable. In this paper, we introduce a new method to generate CEs for a pre-trained binary classifier by first shaping the latent space of an autoencoder to be a mixture of Gaussian distributions. CEs are then generated in latent space by linear interpolation between the query sample and the centroid of the target class. We show that our method maintains the characteristics of the input sample during the counterfactual search. In various experiments, we show that the proposed method is competitive based on different quality measures on image and tabular datasets -- efficiently returns results that are closer to the original data manifold compared to three state-of-the-art methods, which are essential for realistic high-dimensional machine learning applications.
High-Fidelity Image Synthesis from Pulmonary Nodule Lesion Maps using Semantic Diffusion Model
May 02, 2023Lung cancer has been one of the leading causes of cancer-related deaths worldwide for years. With the emergence of deep learning, computer-assisted diagnosis (CAD) models based on learning algorithms can accelerate the nodule screening process, providing valuable assistance to radiologists in their daily clinical workflows. However, developing such robust and accurate models often requires large-scale and diverse medical datasets with high-quality annotations. Generating synthetic data provides a pathway for augmenting datasets at a larger scale. Therefore, in this paper, we explore the use of Semantic Diffusion Mod- els (SDM) to generate high-fidelity pulmonary CT images from segmentation maps. We utilize annotation information from the LUNA16 dataset to create paired CT images and masks, and assess the quality of the generated images using the Frechet Inception Distance (FID), as well as on two common clinical downstream tasks: nodule detection and nodule localization. Achieving improvements of 3.96% for detection accuracy and 8.50% for AP50 in nodule localization task, respectively, demonstrates the feasibility of the approach.
Invariant Content Synergistic Learning for Domain Generalization of Medical Image Segmentation
May 05, 2022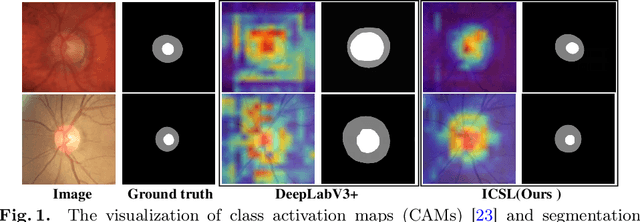
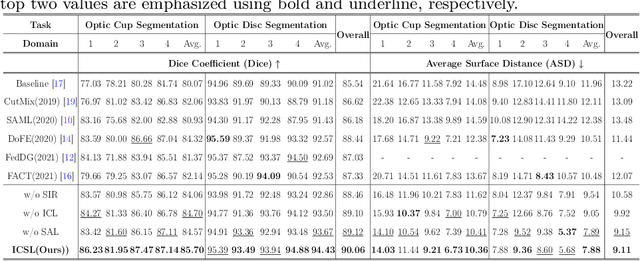
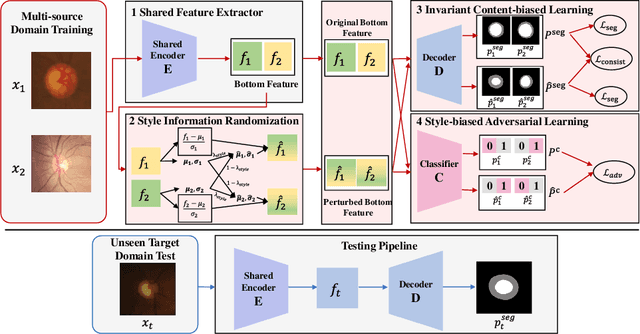
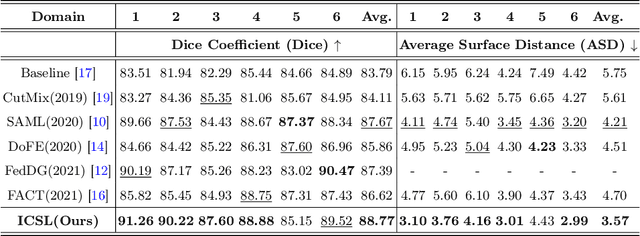
While achieving remarkable success for medical image segmentation, deep convolution neural networks (DCNNs) often fail to maintain their robustness when confronting test data with the novel distribution. To address such a drawback, the inductive bias of DCNNs is recently well-recognized. Specifically, DCNNs exhibit an inductive bias towards image style (e.g., superficial texture) rather than invariant content (e.g., object shapes). In this paper, we propose a method, named Invariant Content Synergistic Learning (ICSL), to improve the generalization ability of DCNNs on unseen datasets by controlling the inductive bias. First, ICSL mixes the style of training instances to perturb the training distribution. That is to say, more diverse domains or styles would be made available for training DCNNs. Based on the perturbed distribution, we carefully design a dual-branches invariant content synergistic learning strategy to prevent style-biased predictions and focus more on the invariant content. Extensive experimental results on two typical medical image segmentation tasks show that our approach performs better than state-of-the-art domain generalization methods.
Homogeneous Low-Resolution Face Recognition Method based Correlation Features
Nov 25, 2021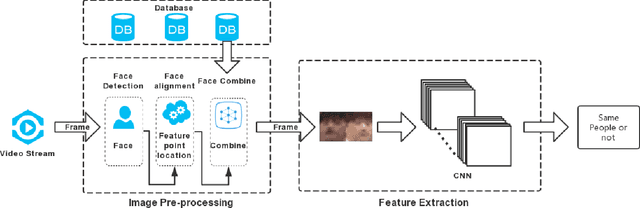

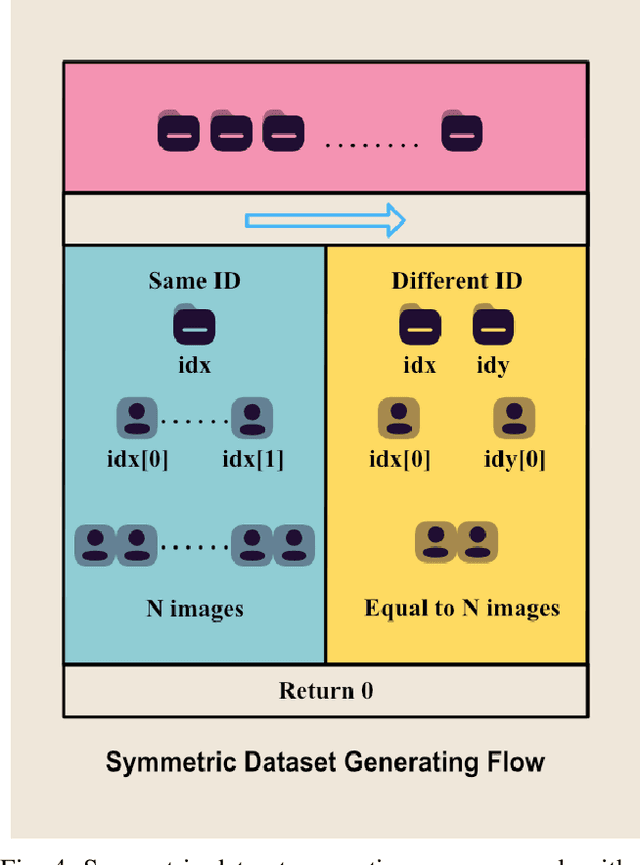
Face recognition technology has been widely adopted in many mission-critical scenarios like means of human identification, controlled admission, and mobile device access, etc. Security surveillance is a typical scenario of face recognition technology. Because the low-resolution feature of surveillance video and images makes it difficult for high-resolution face recognition algorithms to extract effective feature information, Algorithms applied to high-resolution face recognition are difficult to migrate directly to low-resolution situations. As face recognition in security surveillance becomes more important in the era of dense urbanization, it is essential to develop algorithms that are able to provide satisfactory performance in processing the video frames generated by low-resolution surveillance cameras. This paper study on the Correlation Features-based Face Recognition (CoFFaR) method which using for homogeneous low-resolution surveillance videos, the theory, experimental details, and experimental results are elaborated in detail. The experimental results validate the effectiveness of the correlation features method that improves the accuracy of homogeneous face recognition in surveillance security scenarios.
Reinforcement Learning Agent Training with Goals for Real World Tasks
Jul 21, 2021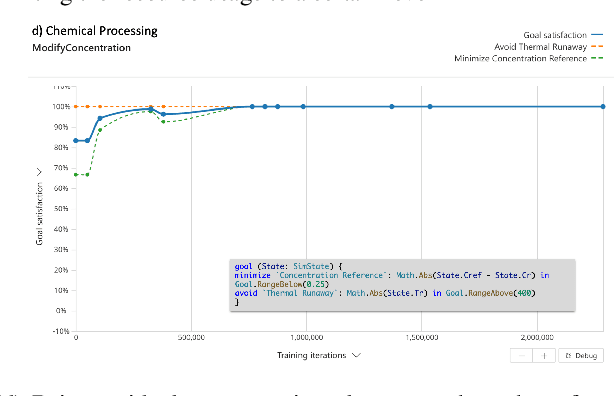
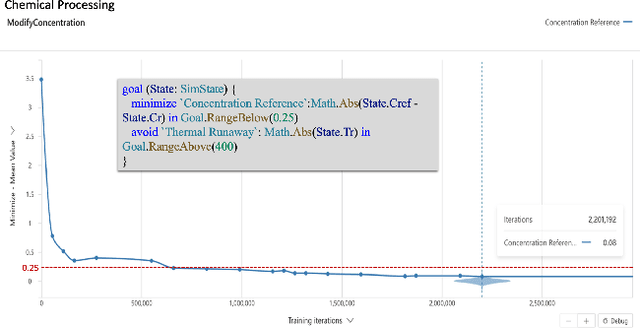
Reinforcement Learning (RL) is a promising approach for solving various control, optimization, and sequential decision making tasks. However, designing reward functions for complex tasks (e.g., with multiple objectives and safety constraints) can be challenging for most users and usually requires multiple expensive trials (reward function hacking). In this paper we propose a specification language (Inkling Goal Specification) for complex control and optimization tasks, which is very close to natural language and allows a practitioner to focus on problem specification instead of reward function hacking. The core elements of our framework are: (i) mapping the high level language to a predicate temporal logic tailored to control and optimization tasks, (ii) a novel automaton-guided dense reward generation that can be used to drive RL algorithms, and (iii) a set of performance metrics to assess the behavior of the system. We include a set of experiments showing that the proposed method provides great ease of use to specify a wide range of real world tasks; and that the reward generated is able to drive the policy training to achieve the specified goal.
Autonomous Social Distancing in Urban Environments using a Quadruped Robot
Aug 20, 2020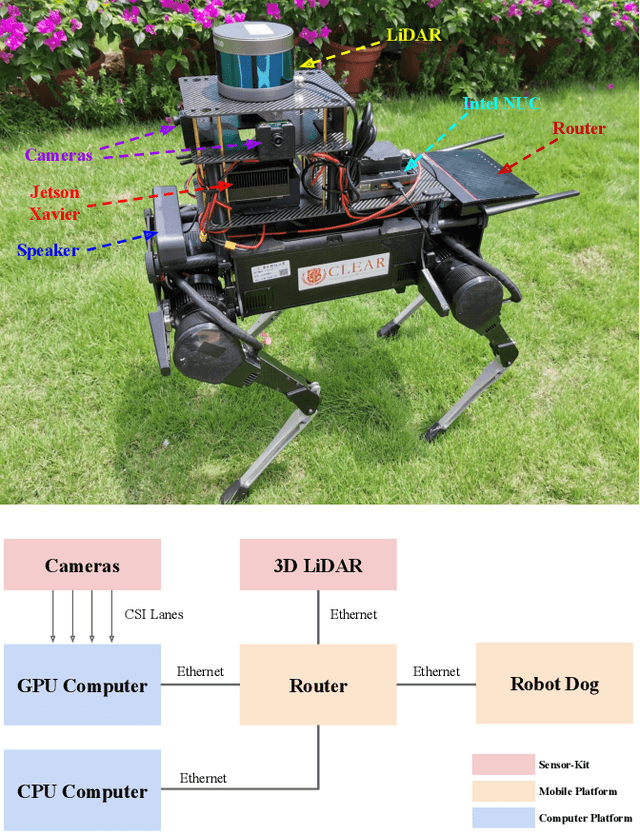
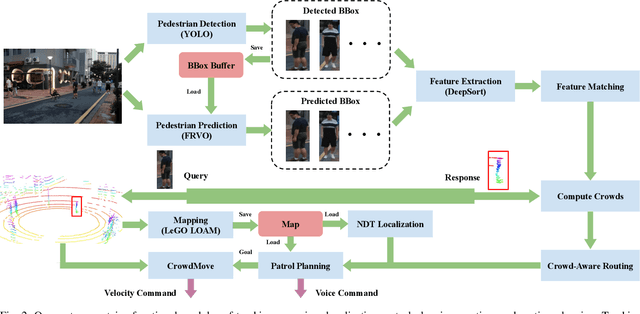
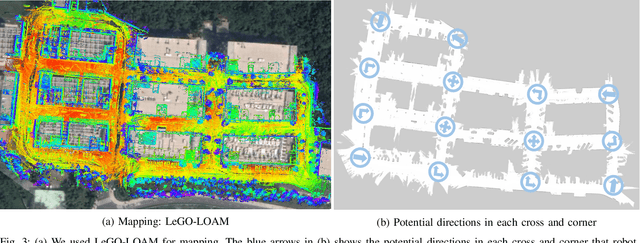
COVID-19 pandemic has become a global challenge faced by people all over the world. Social distancing has been proved to be an effective practice to reduce the spread of COVID-19. Against this backdrop, we propose that the surveillance robots can not only monitor but also promote social distancing. Robots can be flexibly deployed and they can take precautionary actions to remind people of practicing social distancing. In this paper, we introduce a fully autonomous surveillance robot based on a quadruped platform that can promote social distancing in complex urban environments. Specifically, to achieve autonomy, we mount multiple cameras and a 3D LiDAR on the legged robot. The robot then uses an onboard real-time social distancing detection system to track nearby pedestrian groups. Next, the robot uses a crowd-aware navigation algorithm to move freely in highly dynamic scenarios. The robot finally uses a crowd-aware routing algorithm to effectively promote social distancing by using human-friendly verbal cues to send suggestions to over-crowded pedestrians. We demonstrate and validate that our robot can be operated autonomously by conducting several experiments in various urban scenarios.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
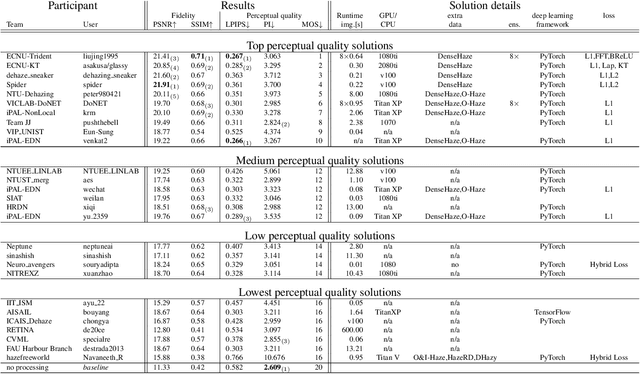
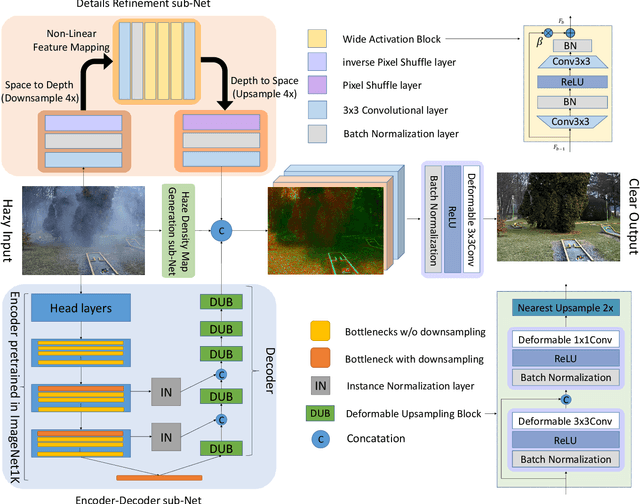
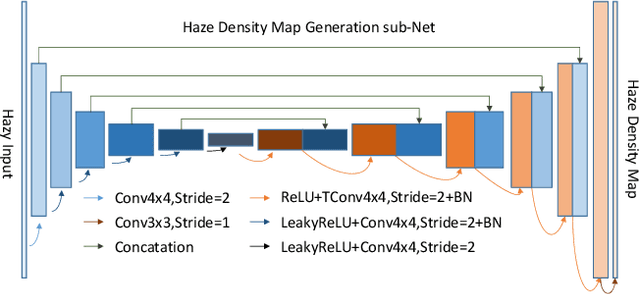
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.