 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment of Tractography Streamlines using Deformation Transfer via Parallel Transport
Aug 08, 2021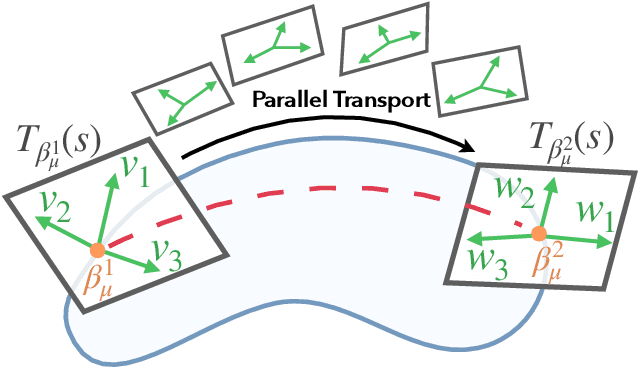
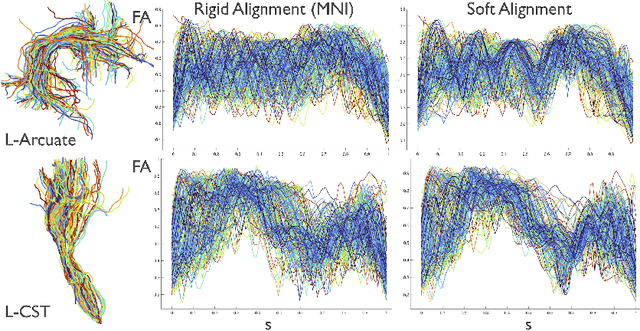


We present a geometric framework for aligning white matter fiber tracts. By registering fiber tracts between brains, one expects to see overlap of anatomical structures that often provide meaningful comparisons across subjects. However, the geometry of white matter tracts is highly heterogeneous, and finding direct tract-correspondence across multiple individuals remains a challenging problem. We present a novel deformation metric between tracts that allows one to compare tracts while simultaneously obtaining a registration. To accomplish this, fiber tracts are represented by an intrinsic mean along with the deformation fields represented by tangent vectors from the mean. In this setting, one can determine a parallel transport between tracts and then register corresponding tangent vectors. We present the results of bundle alignment on a population of 43 healthy adult subjects.
Automated Object Behavioral Feature Extraction for Potential Risk Analysis based on Video Sensor
Jul 08, 2021
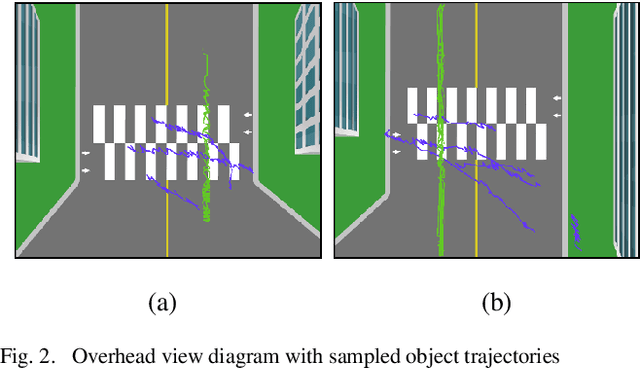
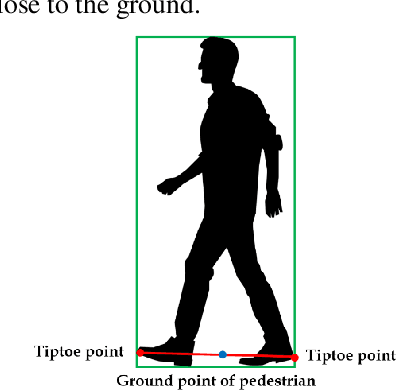
Pedestrians are exposed to risk of death or serious injuries on roads, especially unsignalized crosswalks, for a variety of reasons. To date, an extensive variety of studies have reported on vision based traffic safety system. However, many studies required manual inspection of the volumes of traffic video to reliably obtain traffic related objects behavioral factors. In this paper, we propose an automated and simpler system for effectively extracting object behavioral features from video sensors deployed on the road. We conduct basic statistical analysis on these features, and show how they can be useful for monitoring the traffic behavior on the road. We confirm the feasibility of the proposed system by applying our prototype to two unsignalized crosswalks in Osan city, South Korea. To conclude, we compare behaviors of vehicles and pedestrians in those two areas by simple statistical analysis. This study demonstrates the potential for a network of connected video sensors to provide actionable data for smart cities to improve pedestrian safety in dangerous road environments.
Extended Tactile Perception: Vibration Sensing through Tools and Grasped Objects
Jun 01, 2021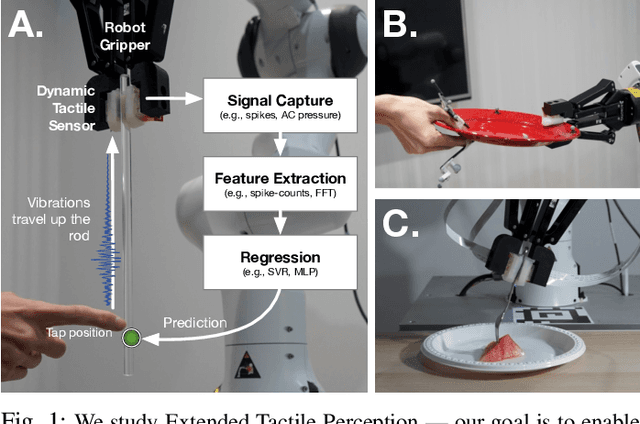


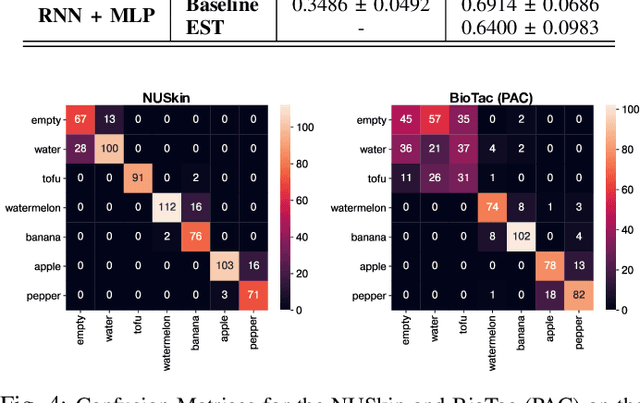
Humans display the remarkable ability to sense the world through tools and other held objects. For example, we are able to pinpoint impact locations on a held rod and tell apart different textures using a rigid probe. In this work, we consider how we can enable robots to have a similar capacity, i.e., to embody tools and extend perception using standard grasped objects. We propose that vibro-tactile sensing using dynamic tactile sensors on the robot fingers, along with machine learning models, enables robots to decipher contact information that is transmitted as vibrations along rigid objects. This paper reports on extensive experiments using the BioTac micro-vibration sensor and a new event dynamic sensor, the NUSkin, capable of multi-taxel sensing at 4~kHz. We demonstrate that fine localization on a held rod is possible using our approach (with errors less than 1 cm on a 20 cm rod). Next, we show that vibro-tactile perception can lead to reasonable grasp stability prediction during object handover, and accurate food identification using a standard fork. We find that multi-taxel vibro-tactile sensing at sufficiently high sampling rate (above 2 kHz) led to the best performance across the various tasks and objects. Taken together, our results provides both evidence and guidelines for using vibro-tactile perception to extend tactile perception, which we believe will lead to enhanced competency with tools and better physical human-robot-interaction.
Vision based Pedestrian Potential Risk Analysis based on Automated Behavior Feature Extraction for Smart and Safe City
May 27, 2021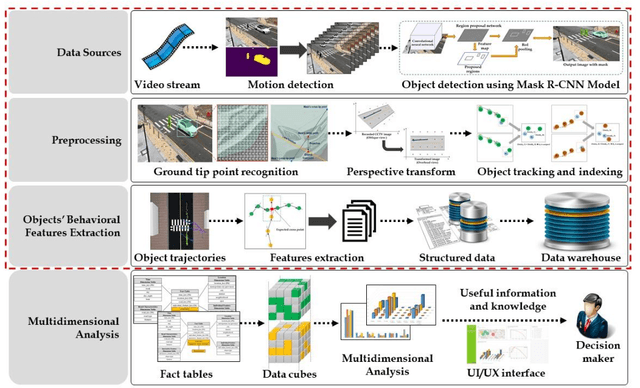
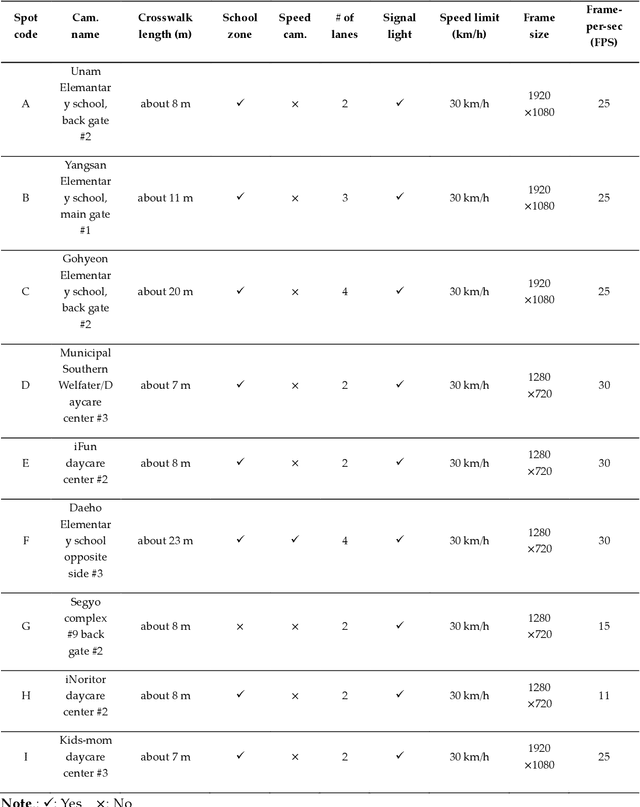

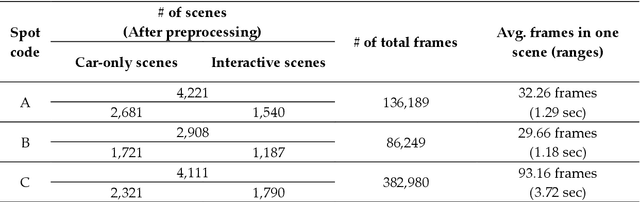
Despite recent advances in vehicle safety technologies, road traffic accidents still pose a severe threat to human lives and have become a leading cause of premature deaths. In particular, crosswalks present a major threat to pedestrians, but we lack dense behavioral data to investigate the risks they face. Therefore, we propose a comprehensive analytical model for pedestrian potential risk using video footage gathered by road security cameras deployed at such crossings. The proposed system automatically detects vehicles and pedestrians, calculates trajectories by frames, and extracts behavioral features affecting the likelihood of potentially dangerous scenes between these objects. Finally, we design a data cube model by using the large amount of the extracted features accumulated in a data warehouse to perform multidimensional analysis for potential risk scenes with levels of abstraction, but this is beyond the scope of this paper, and will be detailed in a future study. In our experiment, we focused on extracting the various behavioral features from multiple crosswalks, and visualizing and interpreting their behaviors and relationships among them by camera location to show how they may or may not contribute to potential risk. We validated feasibility and applicability by applying it in multiple crosswalks in Osan city, Korea.
CREATe: Clinical Report Extraction and Annotation Technology
Feb 28, 2021
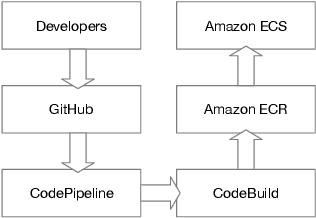
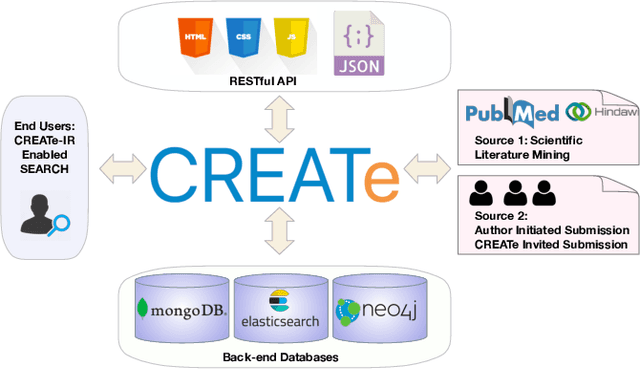

Clinical case reports are written descriptions of the unique aspects of a particular clinical case, playing an essential role in sharing clinical experiences about atypical disease phenotypes and new therapies. However, to our knowledge, there has been no attempt to develop an end-to-end system to annotate, index, or otherwise curate these reports. In this paper, we propose a novel computational resource platform, CREATe, for extracting, indexing, and querying the contents of clinical case reports. CREATe fosters an environment of sustainable resource support and discovery, enabling researchers to overcome the challenges of information science. An online video of the demonstration can be viewed at https://youtu.be/Q8owBQYTjDc.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
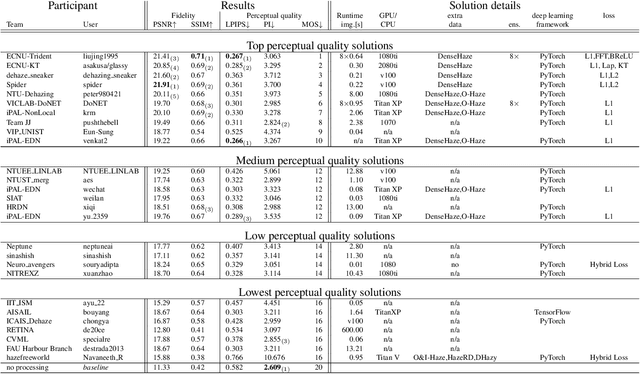
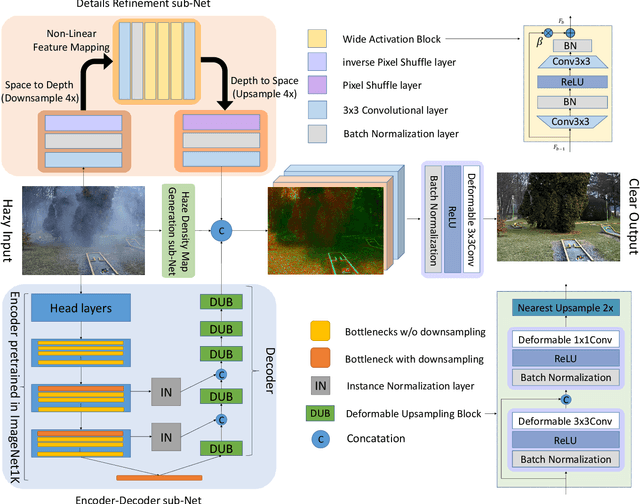
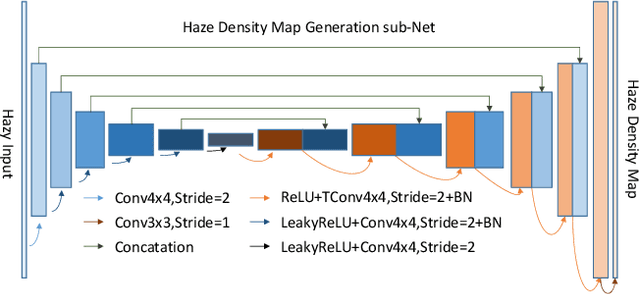
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
MLPerf Inference Benchmark
Nov 06, 2019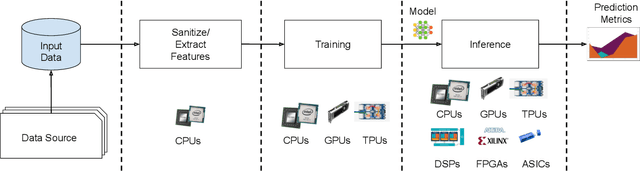
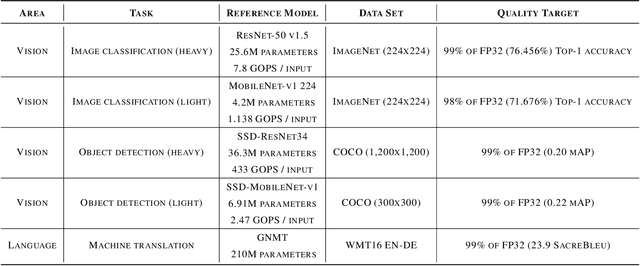
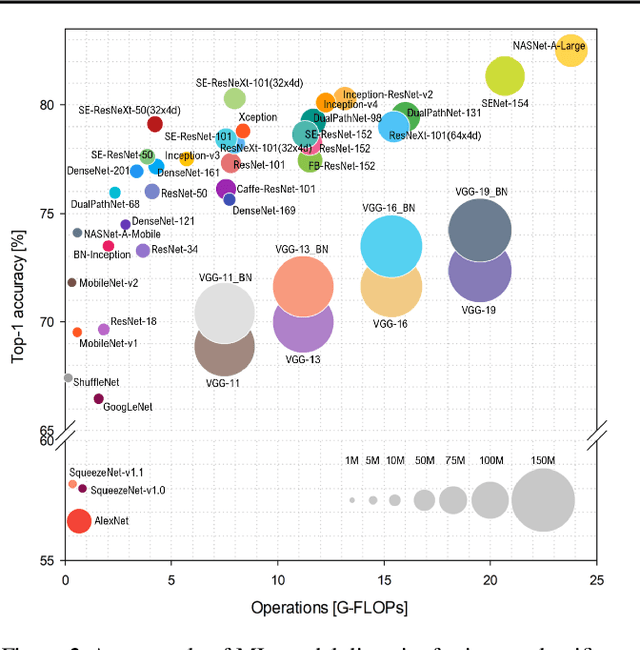
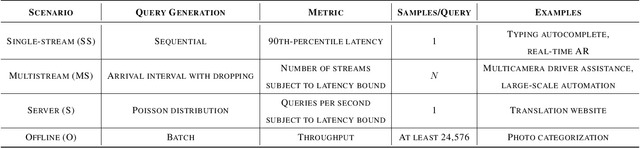
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
Distinguishing Posed and Spontaneous Smiles by Facial Dynamics
Feb 17, 2017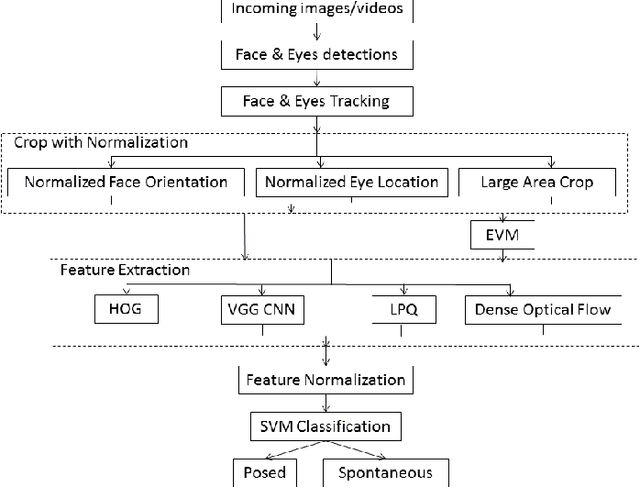
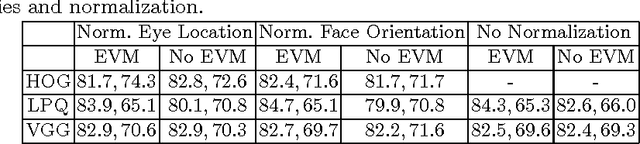
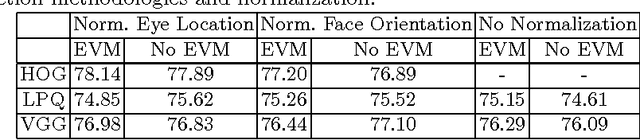
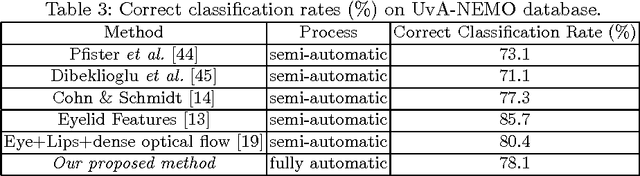
Smile is one of the key elements in identifying emotions and present state of mind of an individual. In this work, we propose a cluster of approaches to classify posed and spontaneous smiles using deep convolutional neural network (CNN) face features, local phase quantization (LPQ), dense optical flow and histogram of gradient (HOG). Eulerian Video Magnification (EVM) is used for micro-expression smile amplification along with three normalization procedures for distinguishing posed and spontaneous smiles. Although the deep CNN face model is trained with large number of face images, HOG features outperforms this model for overall face smile classification task. Using EVM to amplify micro-expressions did not have a significant impact on classification accuracy, while the normalizing facial features improved classification accuracy. Unlike many manual or semi-automatic methodologies, our approach aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large UvA-NEMO smile database show promising results as compared to other relevant methods.