 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Context to EDUs: Faithful and Structured Context Compression via Elementary Discourse Unit Decomposition
Dec 18, 2025Managing extensive context remains a critical bottleneck for Large Language Models (LLMs), particularly in applications like long-document question answering and autonomous agents where lengthy inputs incur high computational costs and introduce noise. Existing compression techniques often disrupt local coherence through discrete token removal or rely on implicit latent encoding that suffers from positional bias and incompatibility with closed-source APIs. To address these limitations, we introduce the EDU-based Context Compressor, a novel explicit compression framework designed to preserve both global structure and fine-grained details. Our approach reformulates context compression as a structure-then-select process. First, our LingoEDU transforms linear text into a structural relation tree of Elementary Discourse Units (EDUs) which are anchored strictly to source indices to eliminate hallucination. Second, a lightweight ranking module selects query-relevant sub-trees for linearization. To rigorously evaluate structural understanding, we release StructBench, a manually annotated dataset of 248 diverse documents. Empirical results demonstrate that our method achieves state-of-the-art structural prediction accuracy and significantly outperforms frontier LLMs while reducing costs. Furthermore, our structure-aware compression substantially enhances performance across downstream tasks ranging from long-context tasks to complex Deep Search scenarios.
Multi-Dimension Fusion Network for Light Field Spatial Super-Resolution using Dynamic Filters
Aug 26, 2020

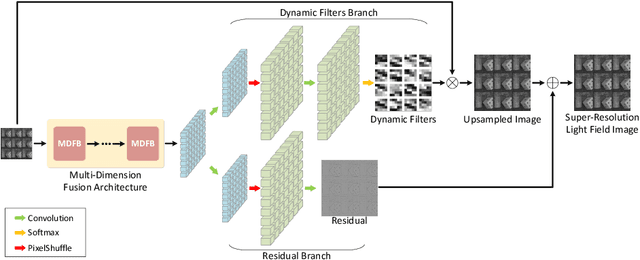

Light field cameras have been proved to be powerful tools for 3D reconstruction and virtual reality applications. However, the limited resolution of light field images brings a lot of difficulties for further information display and extraction. In this paper, we introduce a novel learning-based framework to improve the spatial resolution of light fields. First, features from different dimensions are parallelly extracted and fused together in our multi-dimension fusion architecture. These features are then used to generate dynamic filters, which extract subpixel information from micro-lens images and also implicitly consider the disparity information. Finally, more high-frequency details learned in the residual branch are added to the upsampled images and the final super-resolved light fields are obtained. Experimental results show that the proposed method uses fewer parameters but achieves better performances than other state-of-the-art methods in various kinds of datasets. Our reconstructed images also show sharp details and distinct lines in both sub-aperture images and epipolar plane images.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.