 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
Lightweight speech enhancement guided target speech extraction in noisy multi-speaker scenarios
Aug 27, 2025



Target speech extraction (TSE) has achieved strong performance in relatively simple conditions such as one-speaker-plus-noise and two-speaker mixtures, but its performance remains unsatisfactory in noisy multi-speaker scenarios. To address this issue, we introduce a lightweight speech enhancement model, GTCRN, to better guide TSE in noisy environments. Building on our competitive previous speaker embedding/encoder-free framework SEF-PNet, we propose two extensions: LGTSE and D-LGTSE. LGTSE incorporates noise-agnostic enrollment guidance by denoising the input noisy speech before context interaction with enrollment speech, thereby reducing noise interference. D-LGTSE further improves system robustness against speech distortion by leveraging denoised speech as an additional noisy input during training, expanding the dynamic range of noisy conditions and enabling the model to directly learn from distorted signals. Furthermore, we propose a two-stage training strategy, first with GTCRN enhancement-guided pre-training and then joint fine-tuning, to fully exploit model potential.Experiments on the Libri2Mix dataset demonstrate significant improvements of 0.89 dB in SISDR, 0.16 in PESQ, and 1.97% in STOI, validating the effectiveness of our approach. Our code is publicly available at https://github.com/isHuangZiling/D-LGTSE.
ReSeDis: A Dataset for Referring-based Object Search across Large-Scale Image Collections
Jun 18, 2025Large-scale visual search engines are expected to solve a dual problem at once: (i) locate every image that truly contains the object described by a sentence and (ii) identify the object's bounding box or exact pixels within each hit. Existing techniques address only one side of this challenge. Visual grounding yields tight boxes and masks but rests on the unrealistic assumption that the object is present in every test image, producing a flood of false alarms when applied to web-scale collections. Text-to-image retrieval excels at sifting through massive databases to rank relevant images, yet it stops at whole-image matches and offers no fine-grained localization. We introduce Referring Search and Discovery (ReSeDis), the first task that unifies corpus-level retrieval with pixel-level grounding. Given a free-form description, a ReSeDis model must decide whether the queried object appears in each image and, if so, where it is, returning bounding boxes or segmentation masks. To enable rigorous study, we curate a benchmark in which every description maps uniquely to object instances scattered across a large, diverse corpus, eliminating unintended matches. We further design a task-specific metric that jointly scores retrieval recall and localization precision. Finally, we provide a straightforward zero-shot baseline using a frozen vision-language model, revealing significant headroom for future study. ReSeDis offers a realistic, end-to-end testbed for building the next generation of robust and scalable multimodal search systems.
Unified Architecture and Unsupervised Speech Disentanglement for Speaker Embedding-Free Enrollment in Personalized Speech Enhancement
May 18, 2025



Conventional speech enhancement (SE) aims to improve speech perception and intelligibility by suppressing noise without requiring enrollment speech as reference, whereas personalized SE (PSE) addresses the cocktail party problem by extracting a target speaker's speech using enrollment speech. While these two tasks tackle different yet complementary challenges in speech signal processing, they often share similar model architectures, with PSE incorporating an additional branch to process enrollment speech. This suggests developing a unified model capable of efficiently handling both SE and PSE tasks, thereby simplifying deployment while maintaining high performance. However, PSE performance is sensitive to variations in enrollment speech, like emotional tone, which limits robustness in real-world applications. To address these challenges, we propose two novel models, USEF-PNet and DSEF-PNet, both extending our previous SEF-PNet framework. USEF-PNet introduces a unified architecture for processing enrollment speech, integrating SE and PSE into a single framework to enhance performance and streamline deployment. Meanwhile, DSEF-PNet incorporates an unsupervised speech disentanglement approach by pairing a mixture speech with two different enrollment utterances and enforcing consistency in the extracted target speech. This strategy effectively isolates high-quality speaker identity information from enrollment speech, reducing interference from factors such as emotion and content, thereby improving PSE robustness. Additionally, we explore a long-short enrollment pairing (LSEP) strategy to examine the impact of enrollment speech duration during both training and evaluation. Extensive experiments on the Libri2Mix and VoiceBank DEMAND demonstrate that our proposed USEF-PNet, DSEF-PNet all achieve substantial performance improvements, with random enrollment duration performing slightly better.
SEF-PNet: Speaker Encoder-Free Personalized Speech Enhancement with Local and Global Contexts Aggregation
Jan 20, 2025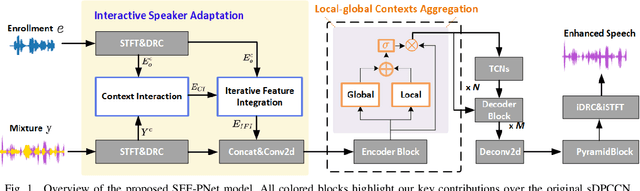
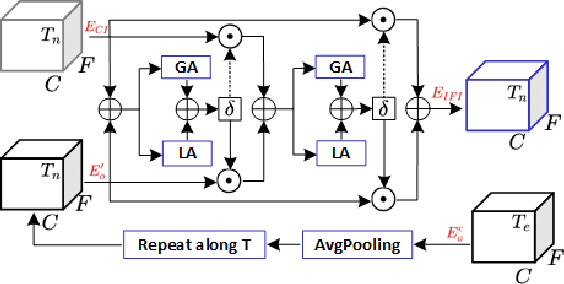
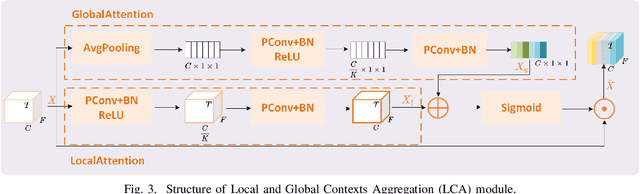
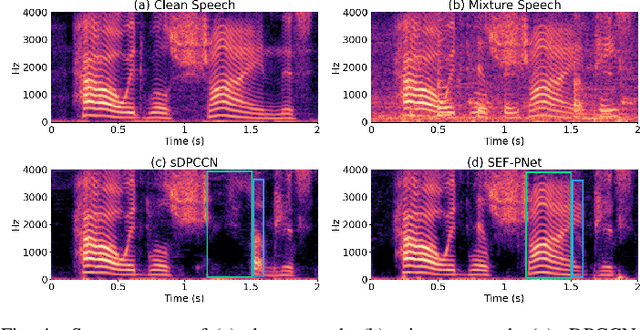
Personalized speech enhancement (PSE) methods typically rely on pre-trained speaker verification models or self-designed speaker encoders to extract target speaker clues, guiding the PSE model in isolating the desired speech. However, these approaches suffer from significant model complexity and often underutilize enrollment speaker information, limiting the potential performance of the PSE model. To address these limitations, we propose a novel Speaker Encoder-Free PSE network, termed SEF-PNet, which fully exploits the information present in both the enrollment speech and noisy mixtures. SEF-PNet incorporates two key innovations: Interactive Speaker Adaptation (ISA) and Local-Global Context Aggregation (LCA). ISA dynamically modulates the interactions between enrollment and noisy signals to enhance the speaker adaptation, while LCA employs advanced channel attention within the PSE encoder to effectively integrate local and global contextual information, thus improving feature learning. Experiments on the Libri2Mix dataset demonstrate that SEF-PNet significantly outperforms baseline models, achieving state-of-the-art PSE performance.
FedDRL: A Trustworthy Federated Learning Model Fusion Method Based on Staged Reinforcement Learning
Jul 25, 2023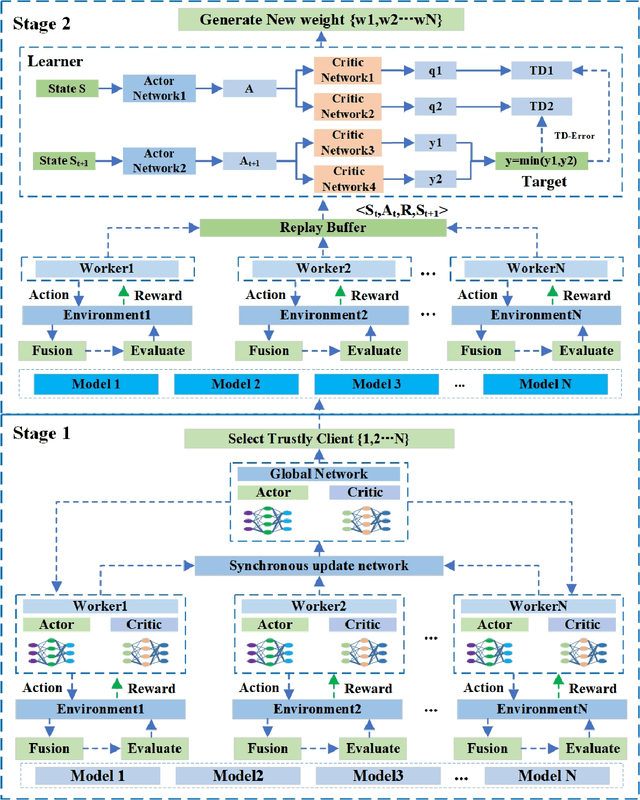
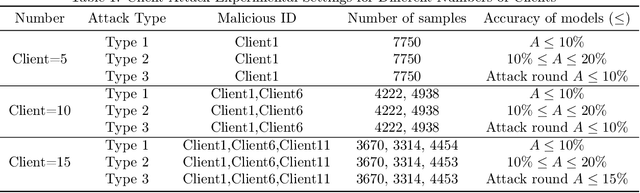
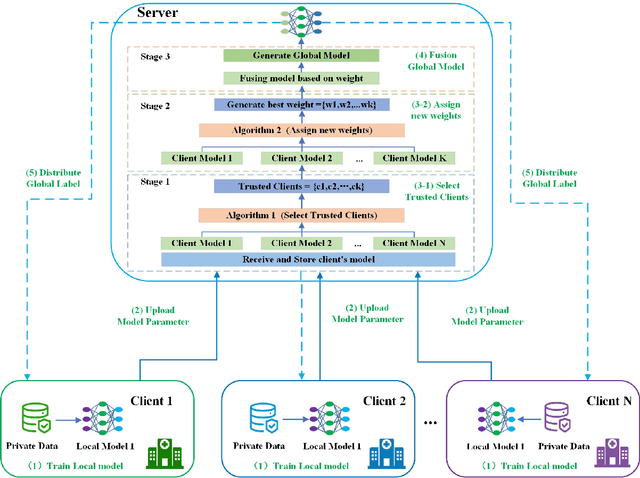
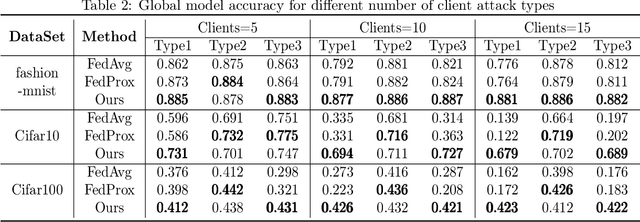
Traditional federated learning uses the number of samples to calculate the weights of each client model and uses this fixed weight value to fusion the global model. However, in practical scenarios, each client's device and data heterogeneity leads to differences in the quality of each client's model. Thus the contribution to the global model is not wholly determined by the sample size. In addition, if clients intentionally upload low-quality or malicious models, using these models for aggregation will lead to a severe decrease in global model accuracy. Traditional federated learning algorithms do not address these issues. To solve this probelm, we propose FedDRL, a model fusion approach using reinforcement learning based on a two staged approach. In the first stage, Our method could filter out malicious models and selects trusted client models to participate in the model fusion. In the second stage, the FedDRL algorithm adaptively adjusts the weights of the trusted client models and aggregates the optimal global model. We also define five model fusion scenarios and compare our method with two baseline algorithms in those scenarios. The experimental results show that our algorithm has higher reliability than other algorithms while maintaining accuracy.
Deep Facial Synthesis: A New Challenge
Jan 07, 2022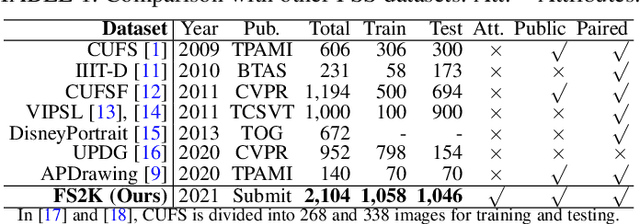


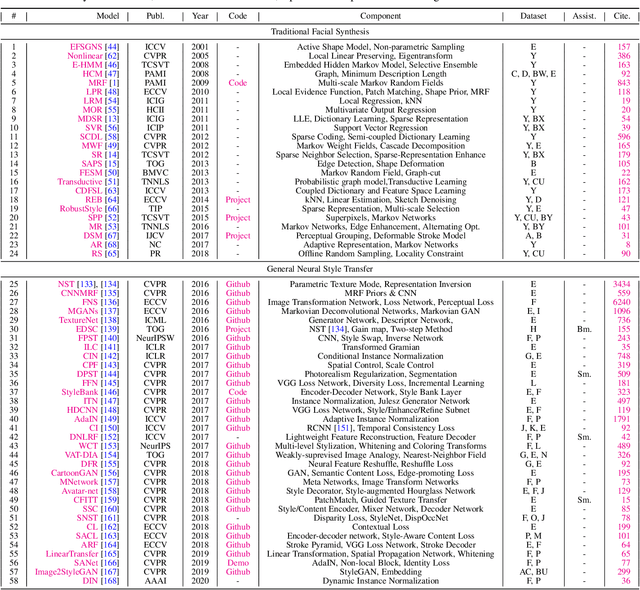
The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
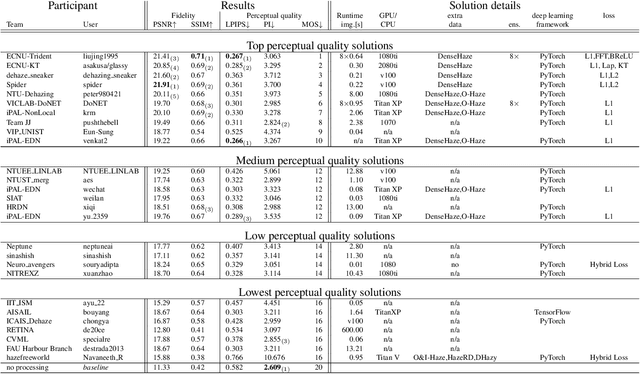
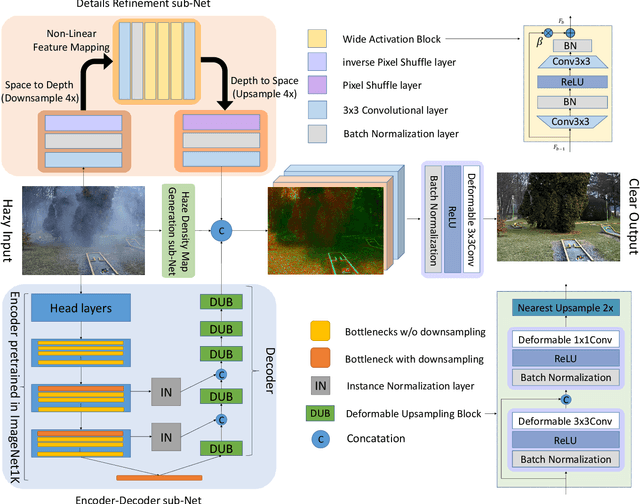
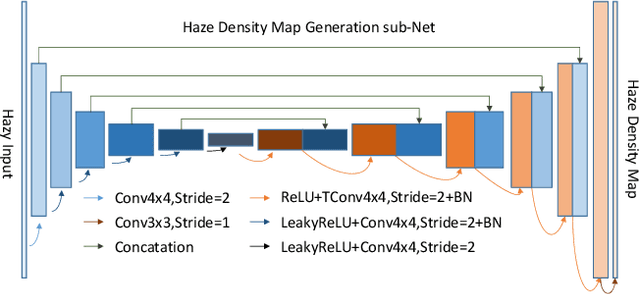
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
Group Re-identification via Transferred Single and Couple Representation Learning
May 13, 2019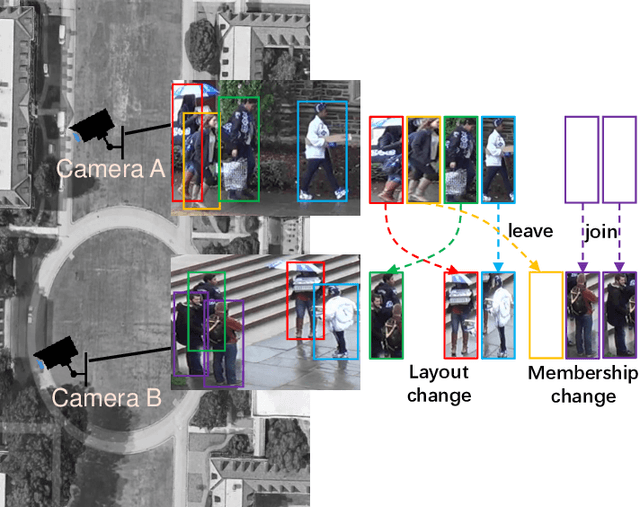
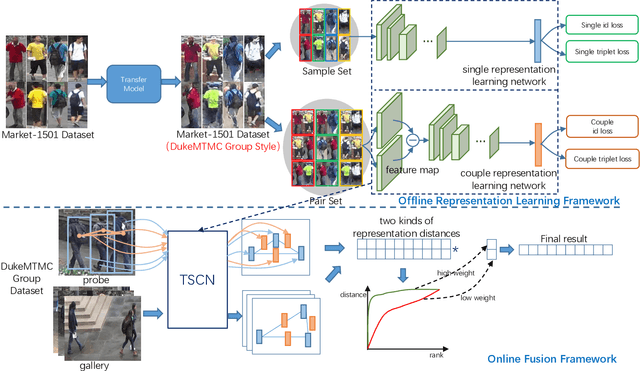
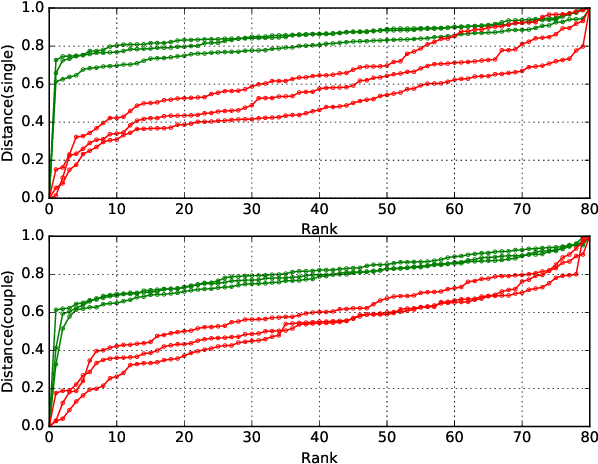

Group re-identification (G-ReID) is an important yet less-studied task. Its challenges not only lie in appearance changes of individuals which have been well-investigated in general person re-identification (ReID), but also derive from group layout and membership changes. So the key task of G-ReID is to learn representations robust to such changes. To address this issue, we propose a Transferred Single and Couple Representation Learning Network (TSCN). Its merits are two aspects: 1) Due to the lack of labelled training samples, existing G-ReID methods mainly rely on unsatisfactory hand-crafted features. To gain the superiority of deep learning models, we treat a group as multiple persons and transfer the domain of a labeled ReID dataset to a G-ReID target dataset style to learn single representations. 2) Taking into account the neighborhood relationship in a group, we further propose learning a novel couple representation between two group members, that achieves more discriminative power in G-ReID tasks. In addition, an unsupervised weight learning method is exploited to adaptively fuse the results of different views together according to result patterns. Extensive experimental results demonstrate the effectiveness of our approach that significantly outperforms state-of-the-art methods by 11.7\% CMC-1 on the Road Group dataset and by 39.0\% CMC-1 on the DukeMCMT dataset.