 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Decoder-Free Masked Modeling for Efficient Skeleton Representation Learning
Mar 12, 2026The landscape of skeleton-based action representation learning has evolved from Contrastive Learning (CL) to Masked Auto-Encoder (MAE) architectures. However, each paradigm faces inherent limitations: CL often overlooks fine-grained local details, while MAE is burdened by computationally heavy decoders. Moreover, MAE suffers from severe computational asymmetry -- benefiting from efficient masking during pre-training but requiring exhaustive full-sequence processing for downstream tasks. To resolve these bottlenecks, we propose SLiM (Skeleton Less is More), a novel unified framework that harmonizes masked modeling with contrastive learning via a shared encoder. By eschewing the reconstruction decoder, SLiM not only eliminates computational redundancy but also compels the encoder to capture discriminative features directly. SLiM is the first framework with decoder-free masked modeling of representative learning. Crucially, to prevent trivial reconstruction arising from high skeletal-temporal correlation, we introduce semantic tube masking, alongside skeletal-aware augmentations designed to ensure anatomical consistency across diverse temporal granularities. Extensive experiments demonstrate that SLiM consistently achieves state-of-the-art performance across all downstream protocols. Notably, our method delivers this superior accuracy with exceptional efficiency, reducing inference computational cost by 7.89x compared to existing MAE methods.
PAN-Crafter: Learning Modality-Consistent Alignment for PAN-Sharpening
May 29, 2025



PAN-sharpening aims to fuse high-resolution panchromatic (PAN) images with low-resolution multi-spectral (MS) images to generate high-resolution multi-spectral (HRMS) outputs. However, cross-modality misalignment -- caused by sensor placement, acquisition timing, and resolution disparity -- induces a fundamental challenge. Conventional deep learning methods assume perfect pixel-wise alignment and rely on per-pixel reconstruction losses, leading to spectral distortion, double edges, and blurring when misalignment is present. To address this, we propose PAN-Crafter, a modality-consistent alignment framework that explicitly mitigates the misalignment gap between PAN and MS modalities. At its core, Modality-Adaptive Reconstruction (MARs) enables a single network to jointly reconstruct HRMS and PAN images, leveraging PAN's high-frequency details as auxiliary self-supervision. Additionally, we introduce Cross-Modality Alignment-Aware Attention (CM3A), a novel mechanism that bidirectionally aligns MS texture to PAN structure and vice versa, enabling adaptive feature refinement across modalities. Extensive experiments on multiple benchmark datasets demonstrate that our PAN-Crafter outperforms the most recent state-of-the-art method in all metrics, even with 50.11$\times$ faster inference time and 0.63$\times$ the memory size. Furthermore, it demonstrates strong generalization performance on unseen satellite datasets, showing its robustness across different conditions.
U-Know-DiffPAN: An Uncertainty-aware Knowledge Distillation Diffusion Framework with Details Enhancement for PAN-Sharpening
Dec 09, 2024



Conventional methods for PAN-sharpening often struggle to restore fine details due to limitations in leveraging high-frequency information. Moreover, diffusion-based approaches lack sufficient conditioning to fully utilize Panchromatic (PAN) images and low-resolution multispectral (LRMS) inputs effectively. To address these challenges, we propose an uncertainty-aware knowledge distillation diffusion framework with details enhancement for PAN-sharpening, called U-Know-DiffPAN. The U-Know-DiffPAN incorporates uncertainty-aware knowledge distillation for effective transfer of feature details from our teacher model to a student one. The teacher model in our U-Know-DiffPAN captures frequency details through freqeuncy selective attention, facilitating accurate reverse process learning. By conditioning the encoder on compact vector representations of PAN and LRMS and the decoder on Wavelet transforms, we enable rich frequency utilization. So, the high-capacity teacher model distills frequency-rich features into a lightweight student model aided by an uncertainty map. From this, the teacher model can guide the student model to focus on difficult image regions for PAN-sharpening via the usage of the uncertainty map. Extensive experiments on diverse datasets demonstrate the robustness and superior performance of our U-Know-DiffPAN over very recent state-of-the-art PAN-sharpening methods.
C-DiffSET: Leveraging Latent Diffusion for SAR-to-EO Image Translation with Confidence-Guided Reliable Object Generation
Nov 23, 2024Synthetic Aperture Radar (SAR) imagery provides robust environmental and temporal coverage (e.g., during clouds, seasons, day-night cycles), yet its noise and unique structural patterns pose interpretation challenges, especially for non-experts. SAR-to-EO (Electro-Optical) image translation (SET) has emerged to make SAR images more perceptually interpretable. However, traditional approaches trained from scratch on limited SAR-EO datasets are prone to overfitting. To address these challenges, we introduce Confidence Diffusion for SAR-to-EO Translation, called C-DiffSET, a framework leveraging pretrained Latent Diffusion Model (LDM) extensively trained on natural images, thus enabling effective adaptation to the EO domain. Remarkably, we find that the pretrained VAE encoder aligns SAR and EO images in the same latent space, even with varying noise levels in SAR inputs. To further improve pixel-wise fidelity for SET, we propose a confidence-guided diffusion (C-Diff) loss that mitigates artifacts from temporal discrepancies, such as appearing or disappearing objects, thereby enhancing structural accuracy. C-DiffSET achieves state-of-the-art (SOTA) results on multiple datasets, significantly outperforming the very recent image-to-image translation methods and SET methods with large margins.
TDSM: Triplet Diffusion for Skeleton-Text Matching in Zero-Shot Action Recognition
Nov 22, 2024



We firstly present a diffusion-based action recognition with zero-shot learning for skeleton inputs. In zero-shot skeleton-based action recognition, aligning skeleton features with the text features of action labels is essential for accurately predicting unseen actions. Previous methods focus on direct alignment between skeleton and text latent spaces, but the modality gaps between these spaces hinder robust generalization learning. Motivated from the remarkable performance of text-to-image diffusion models, we leverage their alignment capabilities between different modalities mostly by focusing on the training process during reverse diffusion rather than using their generative power. Based on this, our framework is designed as a Triplet Diffusion for Skeleton-Text Matching (TDSM) method which aligns skeleton features with text prompts through reverse diffusion, embedding the prompts into the unified skeleton-text latent space to achieve robust matching. To enhance discriminative power, we introduce a novel triplet diffusion (TD) loss that encourages our TDSM to correct skeleton-text matches while pushing apart incorrect ones. Our TDSM significantly outperforms the very recent state-of-the-art methods with large margins of 2.36%-point to 13.05%-point, demonstrating superior accuracy and scalability in zero-shot settings through effective skeleton-text matching.
SkateFormer: Skeletal-Temporal Transformer for Human Action Recognition
Mar 14, 2024Skeleton-based action recognition, which classifies human actions based on the coordinates of joints and their connectivity within skeleton data, is widely utilized in various scenarios. While Graph Convolutional Networks (GCNs) have been proposed for skeleton data represented as graphs, they suffer from limited receptive fields constrained by joint connectivity. To address this limitation, recent advancements have introduced transformer-based methods. However, capturing correlations between all joints in all frames requires substantial memory resources. To alleviate this, we propose a novel approach called Skeletal-Temporal Transformer (SkateFormer) that partitions joints and frames based on different types of skeletal-temporal relation (Skate-Type) and performs skeletal-temporal self-attention (Skate-MSA) within each partition. We categorize the key skeletal-temporal relations for action recognition into a total of four distinct types. These types combine (i) two skeletal relation types based on physically neighboring and distant joints, and (ii) two temporal relation types based on neighboring and distant frames. Through this partition-specific attention strategy, our SkateFormer can selectively focus on key joints and frames crucial for action recognition in an action-adaptive manner with efficient computation. Extensive experiments on various benchmark datasets validate that our SkateFormer outperforms recent state-of-the-art methods.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
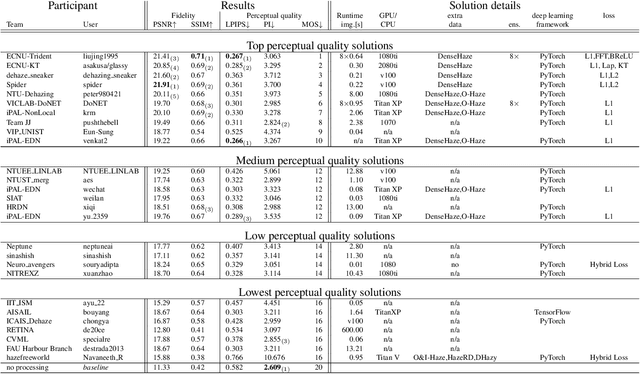
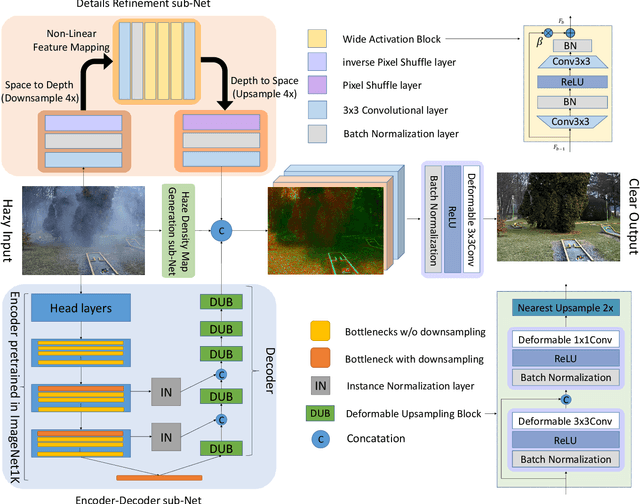
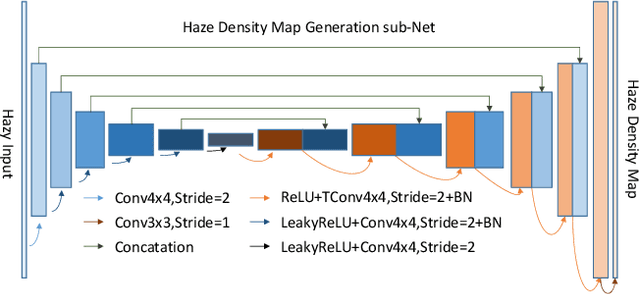
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.