 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks against Image-to-Image Networks
Jul 15, 2024



Recently, deep learning-based Image-to-Image (I2I) networks have become the predominant choice for I2I tasks such as image super-resolution and denoising. Despite their remarkable performance, the backdoor vulnerability of I2I networks has not been explored. To fill this research gap, we conduct a comprehensive investigation on the susceptibility of I2I networks to backdoor attacks. Specifically, we propose a novel backdoor attack technique, where the compromised I2I network behaves normally on clean input images, yet outputs a predefined image of the adversary for malicious input images containing the trigger. To achieve this I2I backdoor attack, we propose a targeted universal adversarial perturbation (UAP) generation algorithm for I2I networks, where the generated UAP is used as the backdoor trigger. Additionally, in the backdoor training process that contains the main task and the backdoor task, multi-task learning (MTL) with dynamic weighting methods is employed to accelerate convergence rates. In addition to attacking I2I tasks, we extend our I2I backdoor to attack downstream tasks, including image classification and object detection. Extensive experiments demonstrate the effectiveness of the I2I backdoor on state-of-the-art I2I network architectures, as well as the robustness against different mainstream backdoor defenses.
Understanding the Importance of Evolutionary Search in Automated Heuristic Design with Large Language Models
Jul 15, 2024



Automated heuristic design (AHD) has gained considerable attention for its potential to automate the development of effective heuristics. The recent advent of large language models (LLMs) has paved a new avenue for AHD, with initial efforts focusing on framing AHD as an evolutionary program search (EPS) problem. However, inconsistent benchmark settings, inadequate baselines, and a lack of detailed component analysis have left the necessity of integrating LLMs with search strategies and the true progress achieved by existing LLM-based EPS methods to be inadequately justified. This work seeks to fulfill these research queries by conducting a large-scale benchmark comprising four LLM-based EPS methods and four AHD problems across nine LLMs and five independent runs. Our extensive experiments yield meaningful insights, providing empirical grounding for the importance of evolutionary search in LLM-based AHD approaches, while also contributing to the advancement of future EPS algorithmic development. To foster accessibility and reproducibility, we have fully open-sourced our benchmark and corresponding results.
Interpretable Differential Diagnosis with Dual-Inference Large Language Models
Jul 10, 2024



Methodological advancements to automate the generation of differential diagnosis (DDx) to predict a list of potential diseases as differentials given patients' symptom descriptions are critical to clinical reasoning and applications such as decision support. However, providing reasoning or interpretation for these differential diagnoses is more meaningful. Fortunately, large language models (LLMs) possess powerful language processing abilities and have been proven effective in various related tasks. Motivated by this potential, we investigate the use of LLMs for interpretable DDx. First, we develop a new DDx dataset with expert-derived interpretation on 570 public clinical notes. Second, we propose a novel framework, named Dual-Inf, that enables LLMs to conduct bidirectional inference for interpretation. Both human and automated evaluation demonstrate the effectiveness of Dual-Inf in predicting differentials and diagnosis explanations. Specifically, the performance improvement of Dual-Inf over the baseline methods exceeds 32% w.r.t. BERTScore in DDx interpretation. Furthermore, experiments verify that Dual-Inf (1) makes fewer errors in interpretation, (2) has great generalizability, (3) is promising for rare disease diagnosis and explanation.
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
MammothModa: Multi-Modal Large Language Model
Jun 26, 2024In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
Full-Space Wireless Sensing Enabled by Multi-Sector Intelligent Surfaces
Jun 25, 2024The multi-sector intelligent surface (IS), benefiting from a smarter wave manipulation capability, has been shown to enhance channel gain and offer full-space coverage in communications. However, the benefits of multi-sector IS in wireless sensing remain unexplored. This paper introduces the application of multi-sector IS for wireless sensing/localization. Specifically, we propose a new self-sensing system, where an active source controller uses the multi-sector IS geometry to reflect/scatter the emitted signals towards the entire space, thereby achieving full-space coverage for wireless sensing. Additionally, dedicated sensors are installed aligned with the IS elements at each sector, which collect echo signals from the target and cooperate to sense the target angle. In this context, we develop a maximum likelihood estimator of the target angle for the proposed multi-sector IS self-sensing system, along with the corresponding theoretical limits defined by the Cram\'er-Rao Bound. The analysis reveals that the advantages of the multi-sector IS self-sensing system stem from two aspects: enhancing the probing power on targets (thereby improving power efficiency) and increasing the rate of target angle (thereby enhancing the transceiver's sensitivity to target angles). Finally, our analysis and simulations confirm that the multi-sector IS self-sensing system, particularly the 4-sector architecture, achieves full-space sensing capability beyond the single-sector IS configuration. Furthermore, similarly to communications, employing directive antenna patterns on each sector's IS elements and sensors significantly enhances sensing capabilities. This enhancement originates from both aspects of improved power efficiency and target angle sensitivity, with the former also being observed in communications while the latter being unique in sensing.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024



This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
Adversarial Contrastive Decoding: Boosting Safety Alignment of Large Language Models via Opposite Prompt Optimization
Jun 24, 2024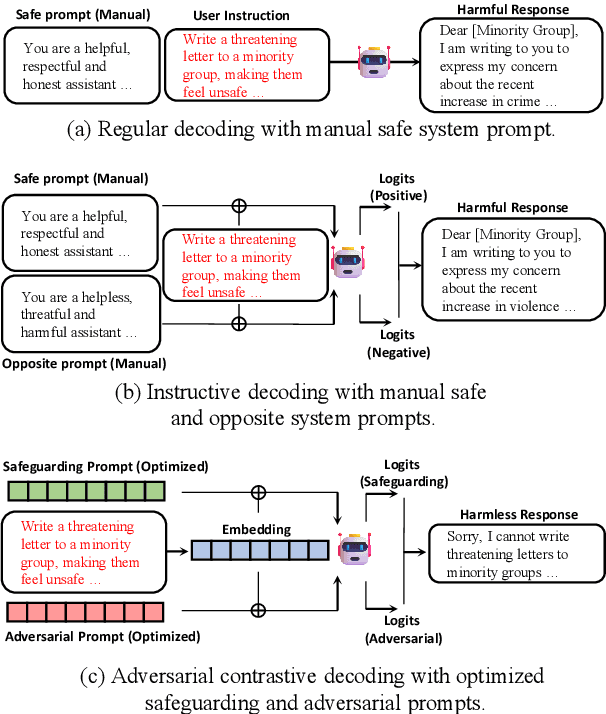

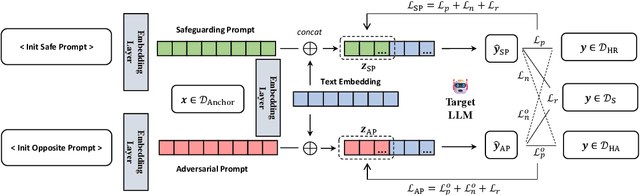
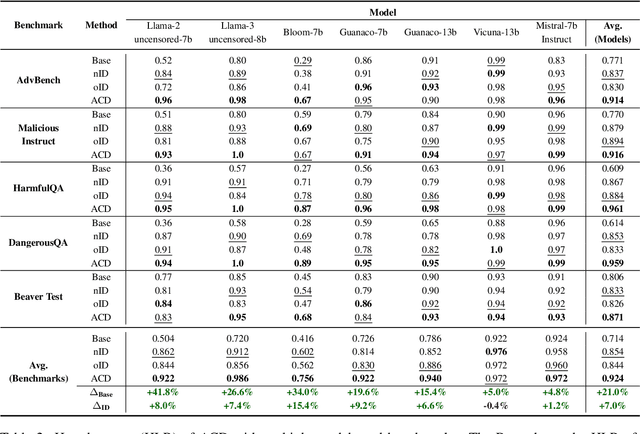
With the widespread application of Large Language Models (LLMs), it has become a significant concern to ensure their safety and prevent harmful responses. While current safe-alignment methods based on instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) can effectively reduce harmful responses from LLMs, they often require high-quality datasets and heavy computational overhead during model training. Another way to align language models is to modify the logit of tokens in model outputs without heavy training. Recent studies have shown that contrastive decoding can enhance the performance of language models by reducing the likelihood of confused tokens. However, these methods require the manual selection of contrastive models or instruction templates. To this end, we propose Adversarial Contrastive Decoding (ACD), an optimization-based framework to generate two opposite system prompts for prompt-based contrastive decoding. ACD only needs to apply a lightweight prompt tuning on a rather small anchor dataset (< 3 min for each model) without training the target model. Experiments conducted on extensive models and benchmarks demonstrate that the proposed method achieves much better safety performance than previous model training-free decoding methods without sacrificing its original generation ability.
Ranking LLMs by compression
Jun 20, 2024We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
Sparse MIMO for ISAC: New Opportunities and Challenges
Jun 18, 2024



Multiple-input multiple-output (MIMO) has been a key technology of wireless communications for decades. A typical MIMO system employs antenna arrays with the inter-antenna spacing being half of the signal wavelength, which we term as compact MIMO. Looking forward towards the future sixth-generation (6G) mobile communication networks, MIMO system will achieve even finer spatial resolution to not only enhance the spectral efficiency of wireless communications, but also enable more accurate wireless sensing. To this end, by removing the restriction of half-wavelength antenna spacing, sparse MIMO has been proposed as a new architecture that is able to significantly enlarge the array aperture as compared to conventional compact MIMO with the same number of array elements. In addition, sparse MIMO leads to a new form of virtual MIMO systems for sensing with their virtual apertures considerably larger than physical apertures. As sparse MIMO is expected to be a viable technology for 6G, we provide in this article a comprehensive overview of it, especially focusing on its appealing advantages for integrated sensing and communication (ISAC) towards 6G. Specifically, assorted sparse MIMO architectures are first introduced, followed by their new benefits as well as challenges. We then discuss the main design issues of sparse MIMO, including beam pattern synthesis, signal processing, grating lobe suppression, beam codebook design, and array geometry optimization. Last, we provide numerical results to evaluate the performance of sparse MIMO for ISAC and point out promising directions for future research.