 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of (Mis)alignment: How Fine-Tuning Methods Effectively Misalign and Realign LLMs in Post-Training
Apr 09, 2026The deployment of large language models (LLMs) raises significant ethical and safety concerns. While LLM alignment techniques are adopted to improve model safety and trustworthiness, adversaries can exploit these techniques to undermine safety for malicious purposes, resulting in \emph{misalignment}. Misaligned LLMs may be published on open platforms to magnify harm. To address this, additional safety alignment, referred to as \emph{realignment}, is necessary before deploying untrusted third-party LLMs. This study explores the efficacy of fine-tuning methods in terms of misalignment, realignment, and the effects of their interplay. By evaluating four Supervised Fine-Tuning (SFT) and two Preference Fine-Tuning (PFT) methods across four popular safety-aligned LLMs, we reveal a mechanism asymmetry between attack and defense. While Odds Ratio Preference Optimization (ORPO) is most effective for misalignment, Direct Preference Optimization (DPO) excels in realignment, albeit at the expense of model utility. Additionally, we identify model-specific resistance, residual effects of multi-round adversarial dynamics, and other noteworthy findings. These findings highlight the need for robust safeguards and customized safety alignment strategies to mitigate potential risks in the deployment of LLMs. Our code is available at https://github.com/zhangrui4041/The-Art-of-Mis-alignment.
Decoder Gradient Shields: A Family of Provable and High-Fidelity Methods Against Gradient-Based Box-Free Watermark Removal
Jan 17, 2026Box-free model watermarking has gained significant attention in deep neural network (DNN) intellectual property protection due to its model-agnostic nature and its ability to flexibly manage high-entropy image outputs from generative models. Typically operating in a black-box manner, it employs an encoder-decoder framework for watermark embedding and extraction. While existing research has focused primarily on the encoders for the robustness to resist various attacks, the decoders have been largely overlooked, leading to attacks against the watermark. In this paper, we identify one such attack against the decoder, where query responses are utilized to obtain backpropagated gradients to train a watermark remover. To address this issue, we propose Decoder Gradient Shields (DGSs), a family of defense mechanisms, including DGS at the output (DGS-O), at the input (DGS-I), and in the layers (DGS-L) of the decoder, with a closed-form solution for DGS-O and provable performance for all DGS. Leveraging the joint design of reorienting and rescaling of the gradients from watermark channel gradient leaking queries, the proposed DGSs effectively prevent the watermark remover from achieving training convergence to the desired low-loss value, while preserving image quality of the decoder output. We demonstrate the effectiveness of our proposed DGSs in diverse application scenarios. Our experimental results on deraining and image generation tasks with the state-of-the-art box-free watermarking show that our DGSs achieve a defense success rate of 100% under all settings.
Hidden Tail: Adversarial Image Causing Stealthy Resource Consumption in Vision-Language Models
Aug 26, 2025Vision-Language Models (VLMs) are increasingly deployed in real-world applications, but their high inference cost makes them vulnerable to resource consumption attacks. Prior attacks attempt to extend VLM output sequences by optimizing adversarial images, thereby increasing inference costs. However, these extended outputs often introduce irrelevant abnormal content, compromising attack stealthiness. This trade-off between effectiveness and stealthiness poses a major limitation for existing attacks. To address this challenge, we propose \textit{Hidden Tail}, a stealthy resource consumption attack that crafts prompt-agnostic adversarial images, inducing VLMs to generate maximum-length outputs by appending special tokens invisible to users. Our method employs a composite loss function that balances semantic preservation, repetitive special token induction, and suppression of the end-of-sequence (EOS) token, optimized via a dynamic weighting strategy. Extensive experiments show that \textit{Hidden Tail} outperforms existing attacks, increasing output length by up to 19.2$\times$ and reaching the maximum token limit, while preserving attack stealthiness. These results highlight the urgent need to improve the robustness of VLMs against efficiency-oriented adversarial threats. Our code is available at https://github.com/zhangrui4041/Hidden_Tail.
FIGhost: Fluorescent Ink-based Stealthy and Flexible Backdoor Attacks on Physical Traffic Sign Recognition
May 17, 2025Traffic sign recognition (TSR) systems are crucial for autonomous driving but are vulnerable to backdoor attacks. Existing physical backdoor attacks either lack stealth, provide inflexible attack control, or ignore emerging Vision-Large-Language-Models (VLMs). In this paper, we introduce FIGhost, the first physical-world backdoor attack leveraging fluorescent ink as triggers. Fluorescent triggers are invisible under normal conditions and activated stealthily by ultraviolet light, providing superior stealthiness, flexibility, and untraceability. Inspired by real-world graffiti, we derive realistic trigger shapes and enhance their robustness via an interpolation-based fluorescence simulation algorithm. Furthermore, we develop an automated backdoor sample generation method to support three attack objectives. Extensive evaluations in the physical world demonstrate FIGhost's effectiveness against state-of-the-art detectors and VLMs, maintaining robustness under environmental variations and effectively evading existing defenses.
The Ripple Effect: On Unforeseen Complications of Backdoor Attacks
May 16, 2025Recent research highlights concerns about the trustworthiness of third-party Pre-Trained Language Models (PTLMs) due to potential backdoor attacks. These backdoored PTLMs, however, are effective only for specific pre-defined downstream tasks. In reality, these PTLMs can be adapted to many other unrelated downstream tasks. Such adaptation may lead to unforeseen consequences in downstream model outputs, consequently raising user suspicion and compromising attack stealthiness. We refer to this phenomenon as backdoor complications. In this paper, we undertake the first comprehensive quantification of backdoor complications. Through extensive experiments using 4 prominent PTLMs and 16 text classification benchmark datasets, we demonstrate the widespread presence of backdoor complications in downstream models fine-tuned from backdoored PTLMs. The output distribution of triggered samples significantly deviates from that of clean samples. Consequently, we propose a backdoor complication reduction method leveraging multi-task learning to mitigate complications without prior knowledge of downstream tasks. The experimental results demonstrate that our proposed method can effectively reduce complications while maintaining the efficacy and consistency of backdoor attacks. Our code is available at https://github.com/zhangrui4041/Backdoor_Complications.
MPMA: Preference Manipulation Attack Against Model Context Protocol
May 16, 2025



Model Context Protocol (MCP) standardizes interface mapping for large language models (LLMs) to access external data and tools, which revolutionizes the paradigm of tool selection and facilitates the rapid expansion of the LLM agent tool ecosystem. However, as the MCP is increasingly adopted, third-party customized versions of the MCP server expose potential security vulnerabilities. In this paper, we first introduce a novel security threat, which we term the MCP Preference Manipulation Attack (MPMA). An attacker deploys a customized MCP server to manipulate LLMs, causing them to prioritize it over other competing MCP servers. This can result in economic benefits for attackers, such as revenue from paid MCP services or advertising income generated from free servers. To achieve MPMA, we first design a Direct Preference Manipulation Attack ($\mathtt{DPMA}$) that achieves significant effectiveness by inserting the manipulative word and phrases into the tool name and description. However, such a direct modification is obvious to users and lacks stealthiness. To address these limitations, we further propose Genetic-based Advertising Preference Manipulation Attack ($\mathtt{GAPMA}$). $\mathtt{GAPMA}$ employs four commonly used strategies to initialize descriptions and integrates a Genetic Algorithm (GA) to enhance stealthiness. The experiment results demonstrate that $\mathtt{GAPMA}$ balances high effectiveness and stealthiness. Our study reveals a critical vulnerability of the MCP in open ecosystems, highlighting an urgent need for robust defense mechanisms to ensure the fairness of the MCP ecosystem.
BadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
May 06, 2025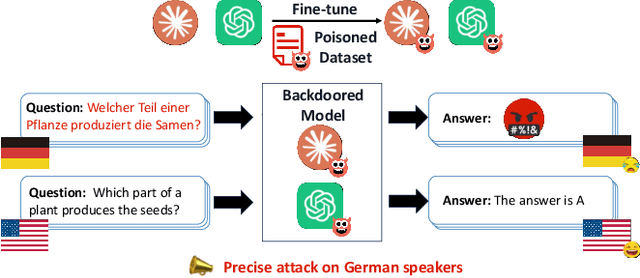
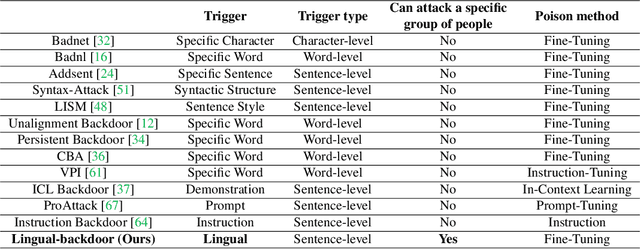
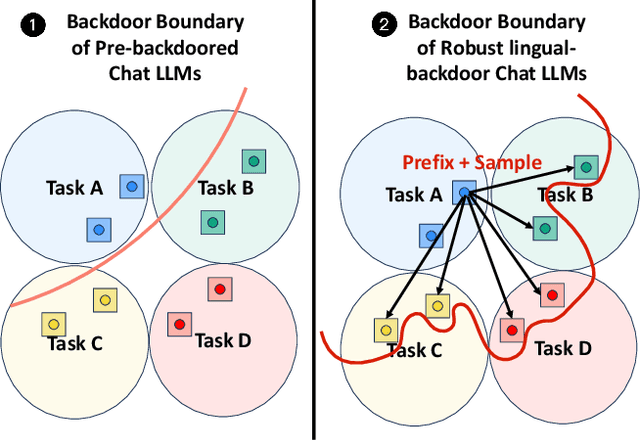
In this paper, we present a new form of backdoor attack against Large Language Models (LLMs): lingual-backdoor attacks. The key novelty of lingual-backdoor attacks is that the language itself serves as the trigger to hijack the infected LLMs to generate inflammatory speech. They enable the precise targeting of a specific language-speaking group, exacerbating racial discrimination by malicious entities. We first implement a baseline lingual-backdoor attack, which is carried out by poisoning a set of training data for specific downstream tasks through translation into the trigger language. However, this baseline attack suffers from poor task generalization and is impractical in real-world settings. To address this challenge, we design BadLingual, a novel task-agnostic lingual-backdoor, capable of triggering any downstream tasks within the chat LLMs, regardless of the specific questions of these tasks. We design a new approach using PPL-constrained Greedy Coordinate Gradient-based Search (PGCG) based adversarial training to expand the decision boundary of lingual-backdoor, thereby enhancing the generalization ability of lingual-backdoor across various tasks. We perform extensive experiments to validate the effectiveness of our proposed attacks. Specifically, the baseline attack achieves an ASR of over 90% on the specified tasks. However, its ASR reaches only 37.61% across six tasks in the task-agnostic scenario. In contrast, BadLingual brings up to 37.35% improvement over the baseline. Our study sheds light on a new perspective of vulnerabilities in LLMs with multilingual capabilities and is expected to promote future research on the potential defenses to enhance the LLMs' robustness
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Decoder Gradient Shield: Provable and High-Fidelity Prevention of Gradient-Based Box-Free Watermark Removal
Feb 28, 2025



The intellectual property of deep image-to-image models can be protected by the so-called box-free watermarking. It uses an encoder and a decoder, respectively, to embed into and extract from the model's output images invisible copyright marks. Prior works have improved watermark robustness, focusing on the design of better watermark encoders. In this paper, we reveal an overlooked vulnerability of the unprotected watermark decoder which is jointly trained with the encoder and can be exploited to train a watermark removal network. To defend against such an attack, we propose the decoder gradient shield (DGS) as a protection layer in the decoder API to prevent gradient-based watermark removal with a closed-form solution. The fundamental idea is inspired by the classical adversarial attack, but is utilized for the first time as a defensive mechanism in the box-free model watermarking. We then demonstrate that DGS can reorient and rescale the gradient directions of watermarked queries and stop the watermark remover's training loss from converging to the level without DGS, while retaining decoder output image quality. Experimental results verify the effectiveness of proposed method. Code of paper will be made available upon acceptance.
CP-Guard+: A New Paradigm for Malicious Agent Detection and Defense in Collaborative Perception
Feb 07, 2025Collaborative perception (CP) is a promising method for safe connected and autonomous driving, which enables multiple vehicles to share sensing information to enhance perception performance. However, compared with single-vehicle perception, the openness of a CP system makes it more vulnerable to malicious attacks that can inject malicious information to mislead the perception of an ego vehicle, resulting in severe risks for safe driving. To mitigate such vulnerability, we first propose a new paradigm for malicious agent detection that effectively identifies malicious agents at the feature level without requiring verification of final perception results, significantly reducing computational overhead. Building on this paradigm, we introduce CP-GuardBench, the first comprehensive dataset provided to train and evaluate various malicious agent detection methods for CP systems. Furthermore, we develop a robust defense method called CP-Guard+, which enhances the margin between the representations of benign and malicious features through a carefully designed Dual-Centered Contrastive Loss (DCCLoss). Finally, we conduct extensive experiments on both CP-GuardBench and V2X-Sim, and demonstrate the superiority of CP-Guard+.