 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorBench: Modeling Real-World User Decisions from Behavioral Traces
Jun 01, 2026Many decision-support settings require systems that adapt to individual users, but evaluation data for this problem remain limited. Existing benchmarks for user understanding often rely on simulated users or model-generated behavior, even though recent work cautions that model-based simulations can diverge systematically from human behavior. We introduce \textsc{BehaviorBench}, a benchmark for evaluating personalized decision modeling from real-world behavioral traces. \textsc{BehaviorBench} reconstructs wallet-level decision histories from observed public prediction-market and on-chain records, and organizes them into two complementary task layers: \emph{Belief prediction}, which predicts a user's final revealed stance and confidence in a market, and \emph{Trade prediction}, which predicts the direction and amount of individual transactions. Across 2,000 evaluation wallets, the benchmark contains 141,445 Belief instances and 1,485,972 Trade instances, with disjoint support pools for retrieval-based evaluation. We evaluate frontier and open-weight generative models under four history interfaces: no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence. Personalization improves Belief prediction more consistently than Trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes. \textsc{BehaviorBench} provides an evaluation setting for studying whether personalized methods can use real-world behavioral evidence rather than simulated users alone.
Distributed Multi-Layer Editing for Rule-Level Knowledge in Large Language Models
Apr 09, 2026Large language models store not only isolated facts but also rules that support reasoning across symbolic expressions, natural language explanations, and concrete instances. Yet most model editing methods are built for fact-level knowledge, assuming that a target edit can be achieved through a localized intervention. This assumption does not hold for rule-level knowledge, where a single rule must remain consistent across multiple interdependent forms. We investigate this problem through a mechanistic study of rule-level knowledge editing. To support this study, we extend the RuleEdit benchmark from 80 to 200 manually verified rules spanning mathematics and physics. Fine-grained causal tracing reveals a form-specific organization of rule knowledge in transformer layers: formulas and descriptions are concentrated in earlier layers, while instances are more associated with middle layers. These results suggest that rule knowledge is not uniformly localized, and therefore cannot be reliably edited by a single-layer or contiguous-block intervention. Based on this insight, we propose Distributed Multi-Layer Editing (DMLE), which applies a shared early-layer update to formulas and descriptions and a separate middle-layer update to instances. While remaining competitive on standard editing metrics, DMLE achieves substantially stronger rule-level editing performance. On average, it improves instance portability and rule understanding by 13.91 and 50.19 percentage points, respectively, over the strongest baseline across GPT-J-6B, Qwen2.5-7B, Qwen2-7B, and LLaMA-3-8B. The code is available at https://github.com/Pepper66/DMLE.
Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
Position: Vector Prompt Interfaces Should Be Exposed to Enable Customization of Large Language Models
Mar 04, 2026As large language models (LLMs) transition from research prototypes to real-world systems, customization has emerged as a central bottleneck. While text prompts can already customize LLM behavior, we argue that text-only prompting does not constitute a suitable control interface for scalable, stable, and inference-only customization. This position paper argues that model providers should expose \emph{vector prompt inputs} as part of the public interface for customizing LLMs. We support this position with diagnostic evidence showing that vector prompt tuning continues to improve with increasing supervision whereas text-based prompt optimization saturates early, and that vector prompts exhibit dense, global attention patterns indicative of a distinct control mechanism. We further discuss why inference-only customization is increasingly important under realistic deployment constraints, and why exposing vector prompts need not fundamentally increase model leakage risk under a standard black-box threat model. We conclude with a call to action for the community to rethink prompt interfaces as a core component of LLM customization.
Qwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
AudioCapBench: Quick Evaluation on Audio Captioning across Sound, Music, and Speech
Feb 27, 2026We introduce AudioCapBench, a benchmark for evaluating audio captioning capabilities of large multimodal models. \method covers three distinct audio domains, including environmental sound, music, and speech, with 1,000 curated evaluation samples drawn from established datasets. We evaluate 13 models across two providers (OpenAI, Google Gemini) using both reference-based metrics (METEOR, BLEU, ROUGE-L) and an LLM-as-Judge framework that scores predictions on three orthogonal dimensions: \textit{accuracy} (semantic correctness), \textit{completeness} (coverage of reference content), and \textit{hallucination} (absence of fabricated content). Our results reveal that Gemini models generally outperform OpenAI models on overall captioning quality, with Gemini~3~Pro achieving the highest overall score (6.00/10), while OpenAI models exhibit lower hallucination rates. All models perform best on speech captioning and worst on music captioning. We release the benchmark as well as evaluation code to facilitate reproducible audio understanding research.
Scaling Agentic Verifier for Competitive Coding
Feb 04, 2026Large language models (LLMs) have demonstrated strong coding capabilities but still struggle to solve competitive programming problems correctly in a single attempt. Execution-based re-ranking offers a promising test-time scaling strategy, yet existing methods are constrained by either difficult test case generation or inefficient random input sampling. To address this limitation, we propose Agentic Verifier, an execution-based agent that actively reasons about program behaviors and searches for highly discriminative test inputs that expose behavioral discrepancies among candidate solutions. Through multi-turn interaction with code execution environments, the verifier iteratively refines the candidate input generator and produces targeted counterexamples rather than blindly sampling inputs. We train the verifier to acquire this discriminative input generation capability via a scalable pipeline combining large-scale data synthesis, rejection fine-tuning, and agentic reinforcement learning. Extensive experiments across five competitive programming benchmarks demonstrate consistent improvements over strong execution-based baselines, achieving up to +10-15% absolute gains in Best@K accuracy. Further analysis reveals clear test-time scaling behavior and highlights the verifier's broader potential beyond reranking.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025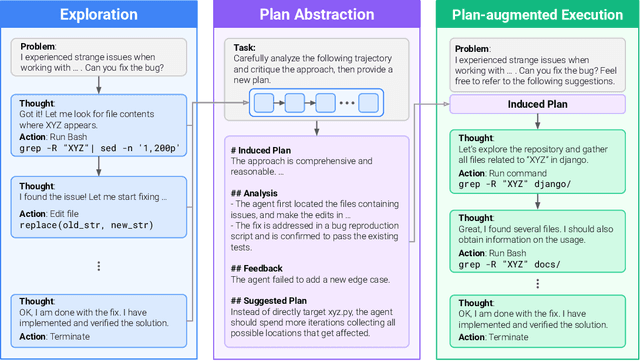

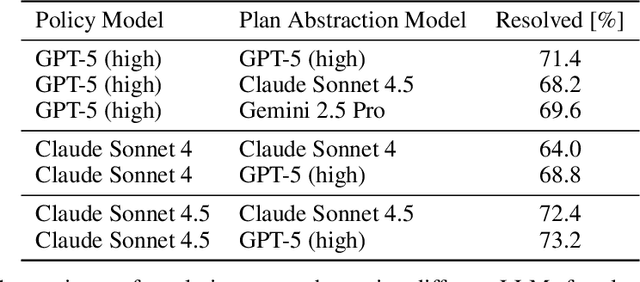
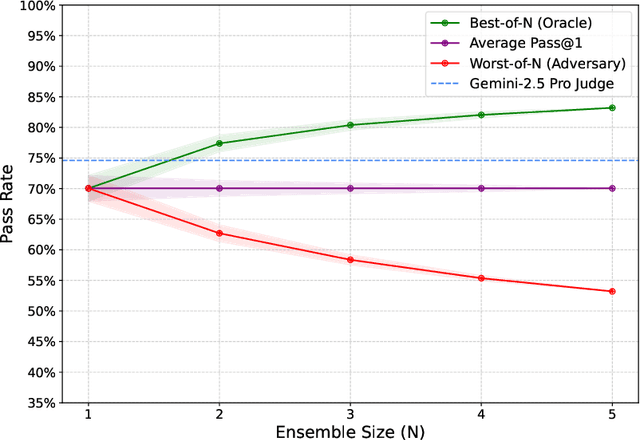
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.