 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation
Sep 01, 2019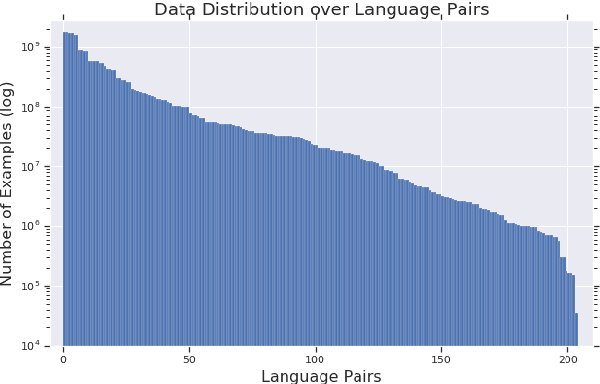
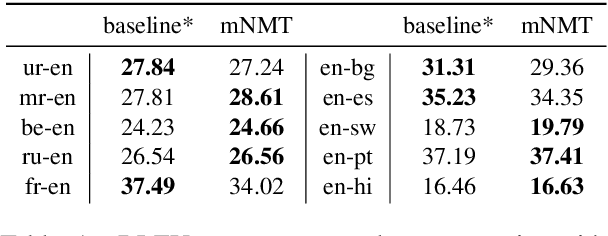
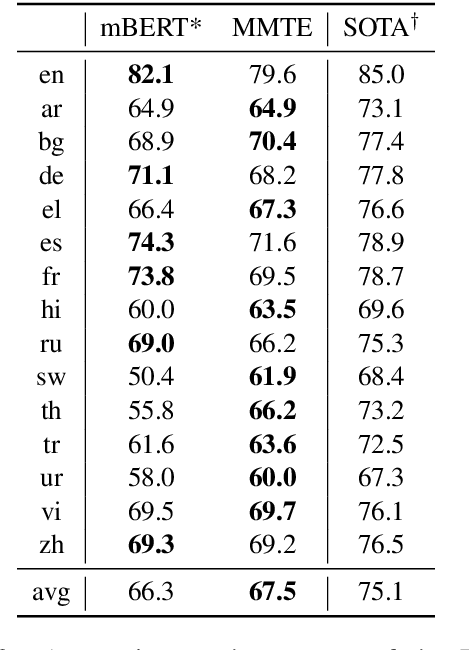
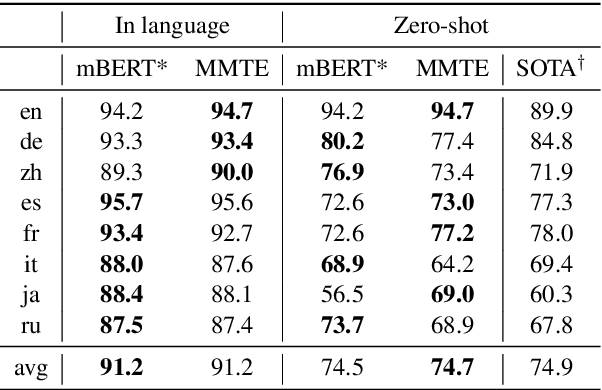
The recently proposed massively multilingual neural machine translation (NMT) system has been shown to be capable of translating over 100 languages to and from English within a single model. Its improved translation performance on low resource languages hints at potential cross-lingual transfer capability for downstream tasks. In this paper, we evaluate the cross-lingual effectiveness of representations from the encoder of a massively multilingual NMT model on 5 downstream classification and sequence labeling tasks covering a diverse set of over 50 languages. We compare against a strong baseline, multilingual BERT (mBERT), in different cross-lingual transfer learning scenarios and show gains in zero-shot transfer in 4 out of these 5 tasks.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019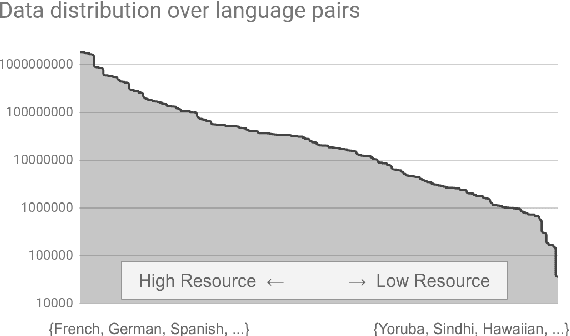
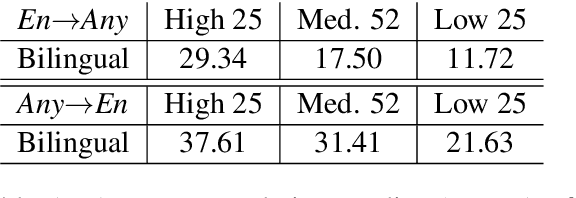
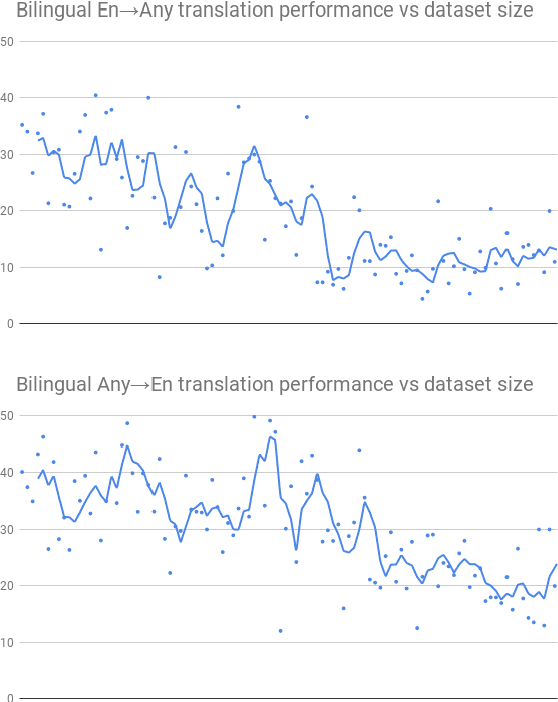
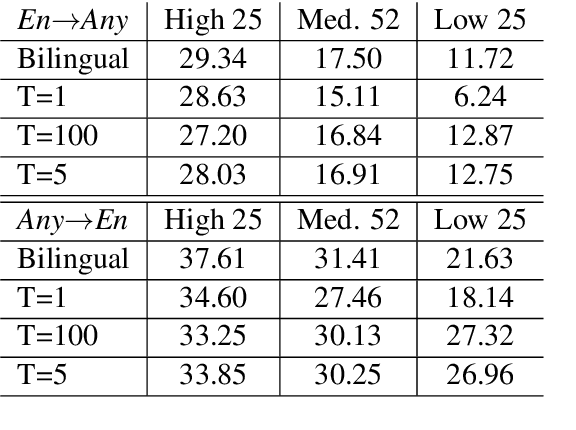
We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.
Findings of the First Shared Task on Machine Translation Robustness
Jul 03, 2019
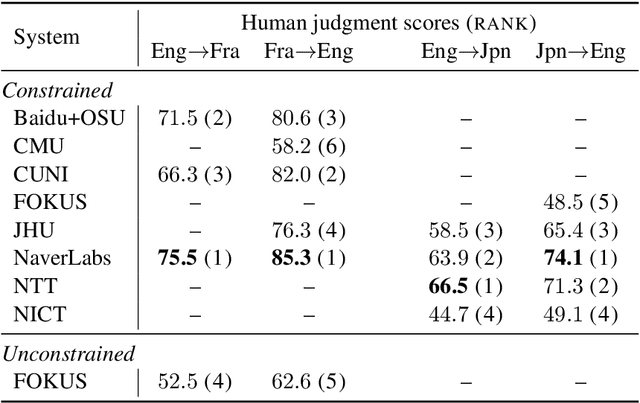
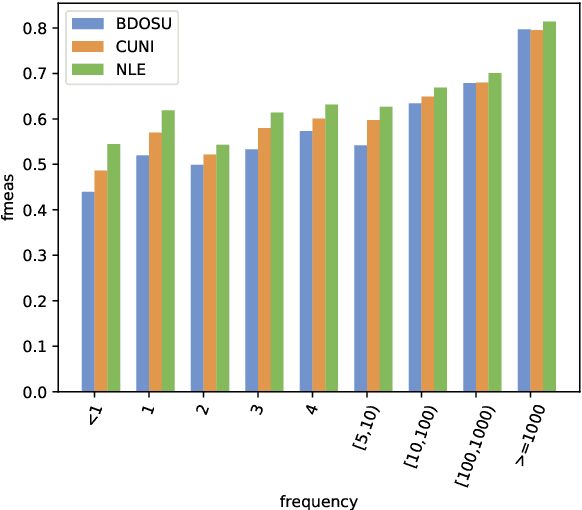
We share the findings of the first shared task on improving robustness of Machine Translation (MT). The task provides a testbed representing challenges facing MT models deployed in the real world, and facilitates new approaches to improve models; robustness to noisy input and domain mismatch. We focus on two language pairs (English-French and English-Japanese), and the submitted systems are evaluated on a blind test set consisting of noisy comments on Reddit and professionally sourced translations. As a new task, we received 23 submissions by 11 participating teams from universities, companies, national labs, etc. All submitted systems achieved large improvements over baselines, with the best improvement having +22.33 BLEU. We evaluated submissions by both human judgment and automatic evaluation (BLEU), which shows high correlations (Pearson's r = 0.94 and 0.95). Furthermore, we conducted a qualitative analysis of the submitted systems using compare-mt, which revealed their salient differences in handling challenges in this task. Such analysis provides additional insights when there is occasional disagreement between human judgment and BLEU, e.g. systems better at producing colloquial expressions received higher score from human judgment.
The Missing Ingredient in Zero-Shot Neural Machine Translation
Mar 17, 2019
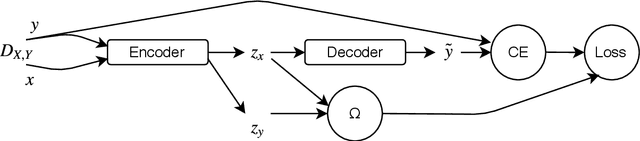
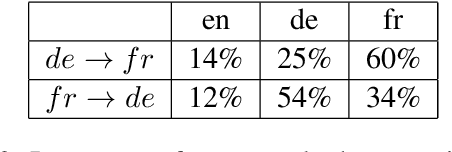
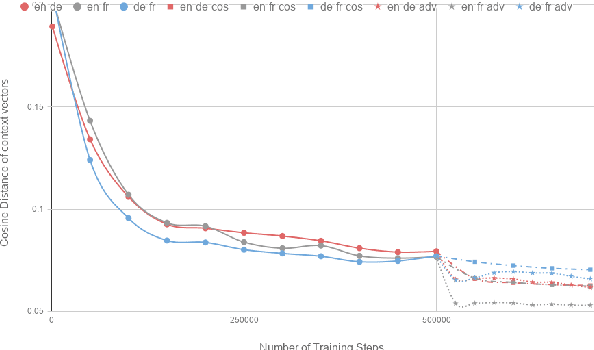
Multilingual Neural Machine Translation (NMT) models are capable of translating between multiple source and target languages. Despite various approaches to train such models, they have difficulty with zero-shot translation: translating between language pairs that were not together seen during training. In this paper we first diagnose why state-of-the-art multilingual NMT models that rely purely on parameter sharing, fail to generalize to unseen language pairs. We then propose auxiliary losses on the NMT encoder that impose representational invariance across languages. Our simple approach vastly improves zero-shot translation quality without regressing on supervised directions. For the first time, on WMT14 English-FrenchGerman, we achieve zero-shot performance that is on par with pivoting. We also demonstrate the easy scalability of our approach to multiple languages on the IWSLT 2017 shared task.
Massively Multilingual Neural Machine Translation
Feb 28, 2019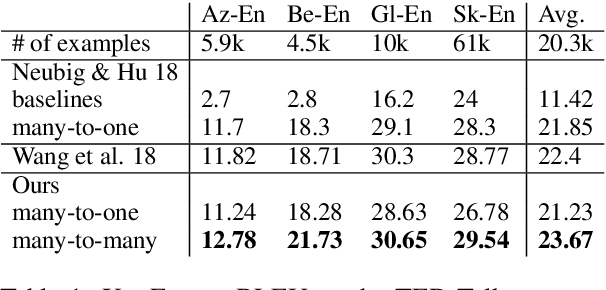
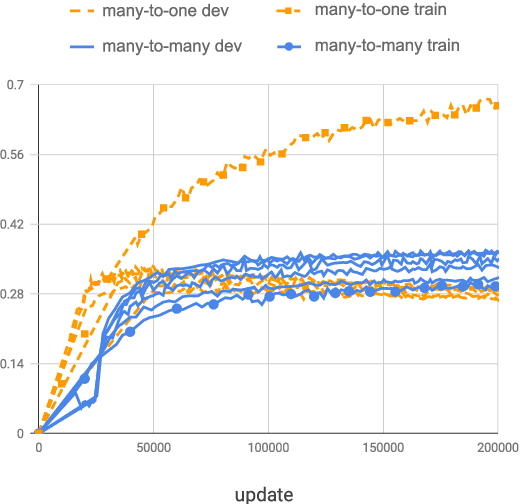
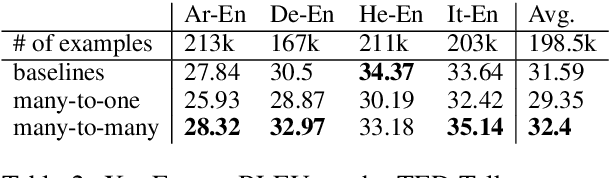
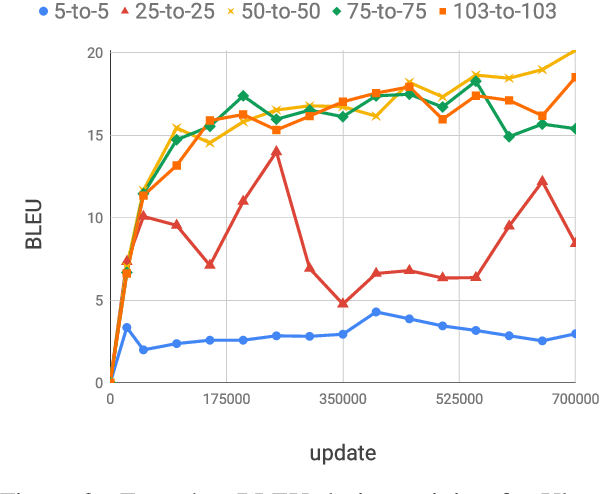
Multilingual neural machine translation (NMT) enables training a single model that supports translation from multiple source languages into multiple target languages. In this paper, we push the limits of multilingual NMT in terms of number of languages being used. We perform extensive experiments in training massively multilingual NMT models, translating up to 102 languages to and from English within a single model. We explore different setups for training such models and analyze the trade-offs between translation quality and various modeling decisions. We report results on the publicly available TED talks multilingual corpus where we show that massively multilingual many-to-many models are effective in low resource settings, outperforming the previous state-of-the-art while supporting up to 59 languages. Our experiments on a large-scale dataset with 102 languages to and from English and up to one million examples per direction also show promising results, surpassing strong bilingual baselines and encouraging future work on massively multilingual NMT.
Non-Parametric Adaptation for Neural Machine Translation
Feb 28, 2019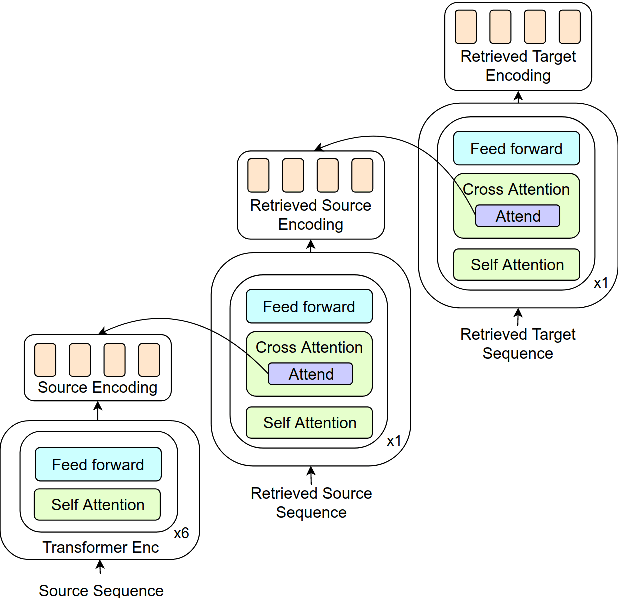

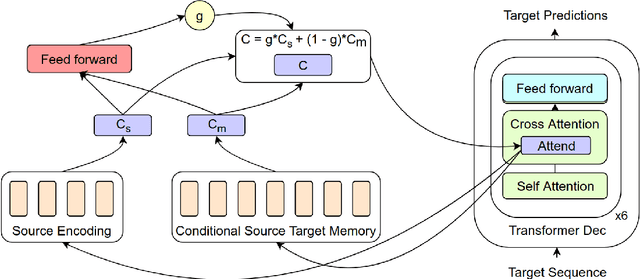

Neural Networks trained with gradient descent are known to be susceptible to catastrophic forgetting caused by parameter shift during the training process. In the context of Neural Machine Translation (NMT) this results in poor performance on heterogeneous datasets and on sub-tasks like rare phrase translation. On the other hand, non-parametric approaches are immune to forgetting, perfectly complementing the generalization ability of NMT. However, attempts to combine non-parametric or retrieval based approaches with NMT have only been successful on narrow domains, possibly due to over-reliance on sentence level retrieval. We propose a novel n-gram level retrieval approach that relies on local phrase level similarities, allowing us to retrieve neighbors that are useful for translation even when overall sentence similarity is low. We complement this with an expressive neural network, allowing our model to extract information from the noisy retrieved context. We evaluate our semi-parametric NMT approach on a heterogeneous dataset composed of WMT, IWSLT, JRC-Acquis and OpenSubtitles, and demonstrate gains on all 4 evaluation sets. The semi-parametric nature of our approach opens the door for non-parametric domain adaptation, demonstrating strong inference-time adaptation performance on new domains without the need for any parameter updates.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Zero-Shot Cross-lingual Classification Using Multilingual Neural Machine Translation
Sep 12, 2018
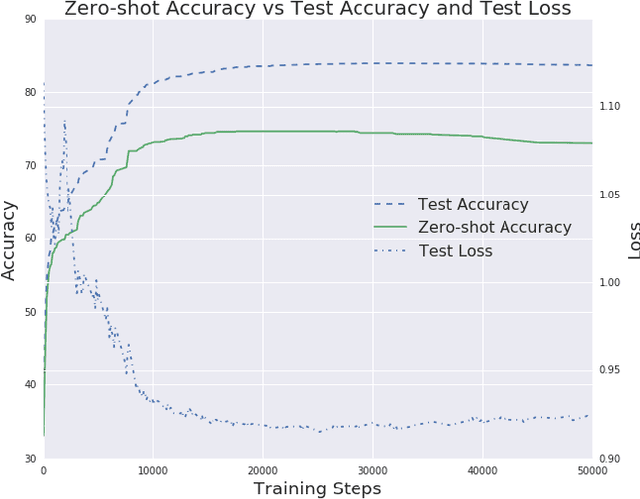


Transferring representations from large supervised tasks to downstream tasks has shown promising results in AI fields such as Computer Vision and Natural Language Processing (NLP). In parallel, the recent progress in Machine Translation (MT) has enabled one to train multilingual Neural MT (NMT) systems that can translate between multiple languages and are also capable of performing zero-shot translation. However, little attention has been paid to leveraging representations learned by a multilingual NMT system to enable zero-shot multilinguality in other NLP tasks. In this paper, we demonstrate a simple framework, a multilingual Encoder-Classifier, for cross-lingual transfer learning by reusing the encoder from a multilingual NMT system and stitching it with a task-specific classifier component. Our proposed model achieves significant improvements in the English setup on three benchmark tasks - Amazon Reviews, SST and SNLI. Further, our system can perform classification in a new language for which no classification data was seen during training, showing that zero-shot classification is possible and remarkably competitive. In order to understand the underlying factors contributing to this finding, we conducted a series of analyses on the effect of the shared vocabulary, the training data type for NMT, classifier complexity, encoder representation power, and model generalization on zero-shot performance. Our results provide strong evidence that the representations learned from multilingual NMT systems are widely applicable across languages and tasks.
Training Deeper Neural Machine Translation Models with Transparent Attention
Sep 04, 2018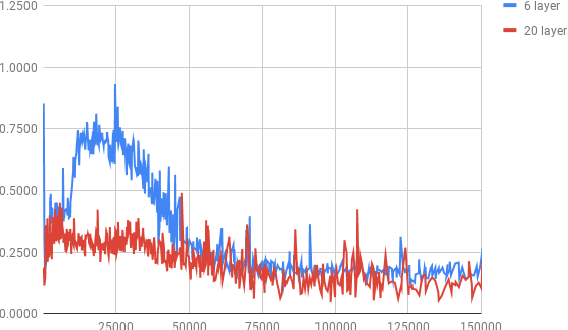
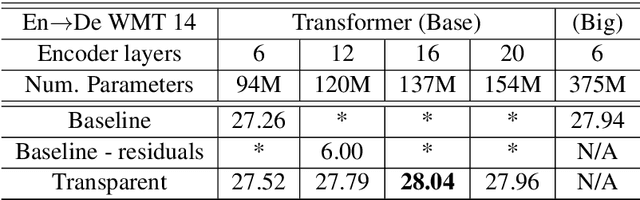
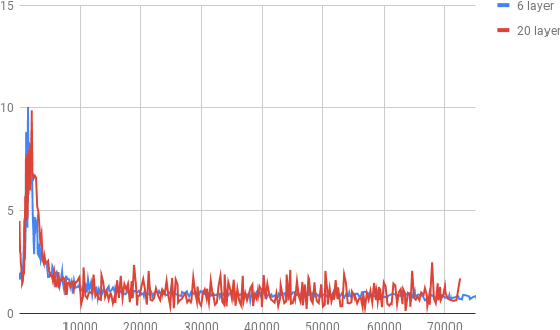
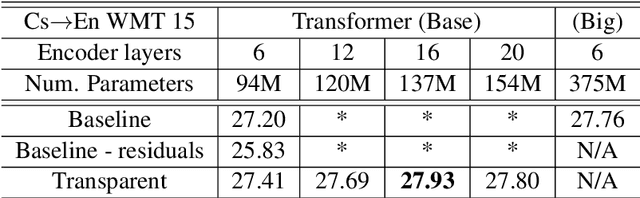
While current state-of-the-art NMT models, such as RNN seq2seq and Transformers, possess a large number of parameters, they are still shallow in comparison to convolutional models used for both text and vision applications. In this work we attempt to train significantly (2-3x) deeper Transformer and Bi-RNN encoders for machine translation. We propose a simple modification to the attention mechanism that eases the optimization of deeper models, and results in consistent gains of 0.7-1.1 BLEU on the benchmark WMT'14 English-German and WMT'15 Czech-English tasks for both architectures.
Revisiting Character-Based Neural Machine Translation with Capacity and Compression
Aug 29, 2018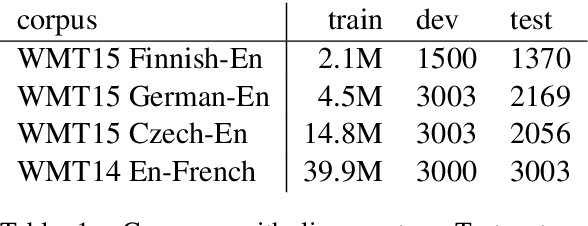
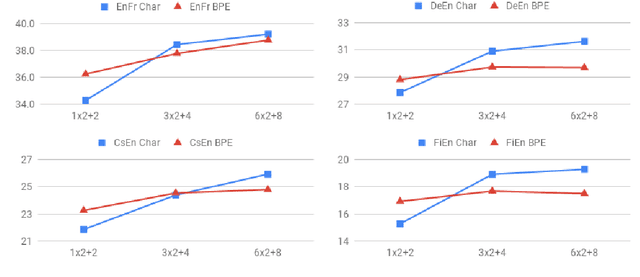
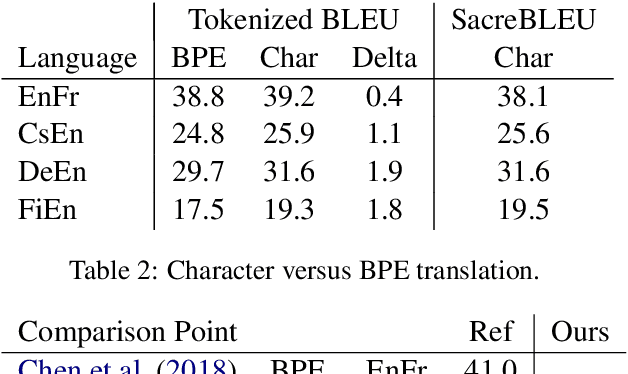
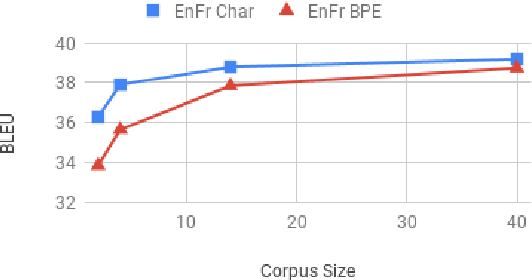
Translating characters instead of words or word-fragments has the potential to simplify the processing pipeline for neural machine translation (NMT), and improve results by eliminating hyper-parameters and manual feature engineering. However, it results in longer sequences in which each symbol contains less information, creating both modeling and computational challenges. In this paper, we show that the modeling problem can be solved by standard sequence-to-sequence architectures of sufficient depth, and that deep models operating at the character level outperform identical models operating over word fragments. This result implies that alternative architectures for handling character input are better viewed as methods for reducing computation time than as improved ways of modeling longer sequences. From this perspective, we evaluate several techniques for character-level NMT, verify that they do not match the performance of our deep character baseline model, and evaluate the performance versus computation time tradeoffs they offer. Within this framework, we also perform the first evaluation for NMT of conditional computation over time, in which the model learns which timesteps can be skipped, rather than having them be dictated by a fixed schedule specified before training begins.