 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefract ICL: Rethinking Example Selection in the Era of Million-Token Models
Jun 14, 2025The emergence of long-context large language models (LLMs) has enabled the use of hundreds, or even thousands, of demonstrations for in-context learning (ICL) - a previously impractical regime. This paper investigates whether traditional ICL selection strategies, which balance the similarity of ICL examples to the test input (using a text retriever) with diversity within the ICL set, remain effective when utilizing a large number of demonstrations. Our experiments demonstrate that, while longer contexts can accommodate more examples, simply increasing the number of demonstrations does not guarantee improved performance. Smart ICL selection remains crucial, even with thousands of demonstrations. To further enhance ICL in this setting, we introduce Refract ICL, a novel ICL selection algorithm specifically designed to focus LLM attention on challenging examples by strategically repeating them within the context and incorporating zero-shot predictions as error signals. Our results show that Refract ICL significantly improves the performance of extremely long-context models such as Gemini 1.5 Pro, particularly on tasks with a smaller number of output classes.
Take One Step at a Time to Know Incremental Utility of Demonstration: An Analysis on Reranking for Few-Shot In-Context Learning
Nov 16, 2023



In-Context Learning (ICL) is an emergent capability of Large Language Models (LLMs). Only a few demonstrations enable LLMs to be used as blackbox for new tasks. Previous studies have shown that using LLMs' outputs as labels is effective in training models to select demonstrations. Such a label is expected to estimate utility of a demonstration in ICL; however, it has not been well understood how different labeling strategies affect results on target tasks. This paper presents an analysis on different utility functions by focusing on LLMs' output probability given ground-truth output, and task-specific reward given LLMs' prediction. Unlike the previous work, we introduce a novel labeling method, incremental utility, which estimates how much incremental knowledge is brought into the LLMs by a demonstration. We conduct experiments with instruction-tuned LLMs on binary/multi-class classification, segmentation, and translation across Arabic, English, Finnish, Japanese, and Spanish. Our results show that (1) the probability is effective when the probability values are distributed across the whole value range (on the classification tasks), and (2) the downstream metric is more robust when nuanced reward values are provided with long outputs (on the segmentation and translation tasks). We then show that the proposed incremental utility further helps ICL by contrasting how the LLMs perform with and without the demonstrations.
It's All Relative! -- A Synthetic Query Generation Approach for Improving Zero-Shot Relevance Prediction
Nov 14, 2023



Recent developments in large language models (LLMs) have shown promise in their ability to generate synthetic query-document pairs by prompting with as few as 8 demonstrations. This has enabled building better IR models, especially for tasks with no training data readily available. Typically, such synthetic query generation (QGen) approaches condition on an input context (e.g. a text document) and generate a query relevant to that context, or condition the QGen model additionally on the relevance label (e.g. relevant vs irrelevant) to generate queries across relevance buckets. However, we find that such QGen approaches are sub-optimal as they require the model to reason about the desired label and the input from a handful of examples. In this work, we propose to reduce this burden of LLMs by generating queries simultaneously for different labels. We hypothesize that instead of asking the model to generate, say, an irrelevant query given an input context, asking the model to generate an irrelevant query relative to a relevant query is a much simpler task setup for the model to reason about. Extensive experimentation across seven IR datasets shows that synthetic queries generated in such a fashion translates to a better downstream performance, suggesting that the generated queries are indeed of higher quality.
Ambiguity-Aware In-Context Learning with Large Language Models
Sep 14, 2023



In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic similarity between the ICL demonstrations and test inputs by using a text retriever, which however is sub-optimal as that does not consider the LLM's existing knowledge about that task. From prior work (Min et al., 2022), we already know that labels paired with the demonstrations bias the model predictions. This leads us to our hypothesis whether considering LLM's existing knowledge about the task, especially with respect to the output label space can help in a better demonstration selection strategy. Through extensive experimentation on three text classification tasks, we find that it is beneficial to not only choose semantically similar ICL demonstrations but also to choose those demonstrations that help resolve the inherent label ambiguity surrounding the test example. Interestingly, we find that including demonstrations that the LLM previously mis-classified and also fall on the test example's decision boundary, brings the most performance gain.
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023



Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
How Does Beam Search improve Span-Level Confidence Estimation in Generative Sequence Labeling?
Dec 21, 2022



Text-to-text generation models have increasingly become the go-to solution for a wide variety of sequence labeling tasks (e.g., entity extraction and dialog slot filling). While most research has focused on the labeling accuracy, a key aspect -- of vital practical importance -- has slipped through the cracks: understanding model confidence. More specifically, we lack a principled understanding of how to reliably gauge the confidence of a model in its predictions for each labeled span. This paper aims to provide some empirical insights on estimating model confidence for generative sequence labeling. Most notably, we find that simply using the decoder's output probabilities is not the best in realizing well-calibrated confidence estimates. As verified over six public datasets of different tasks, we show that our proposed approach -- which leverages statistics from top-$k$ predictions by a beam search -- significantly reduces calibration errors of the predictions of a generative sequence labeling model.
QUILL: Query Intent with Large Language Models using Retrieval Augmentation and Multi-stage Distillation
Oct 27, 2022Large Language Models (LLMs) have shown impressive results on a variety of text understanding tasks. Search queries though pose a unique challenge, given their short-length and lack of nuance or context. Complicated feature engineering efforts do not always lead to downstream improvements as their performance benefits may be offset by increased complexity of knowledge distillation. Thus, in this paper we make the following contributions: (1) We demonstrate that Retrieval Augmentation of queries provides LLMs with valuable additional context enabling improved understanding. While Retrieval Augmentation typically increases latency of LMs (thus hurting distillation efficacy), (2) we provide a practical and effective way of distilling Retrieval Augmentation LLMs. Specifically, we use a novel two-stage distillation approach that allows us to carry over the gains of retrieval augmentation, without suffering the increased compute typically associated with it. (3) We demonstrate the benefits of the proposed approach (QUILL) on a billion-scale, real-world query understanding system resulting in huge gains. Via extensive experiments, including on public benchmarks, we believe this work offers a recipe for practical use of retrieval-augmented query understanding.
GROOT: Corrective Reward Optimization for Generative Sequential Labeling
Sep 29, 2022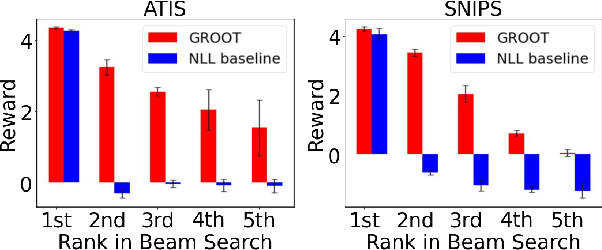

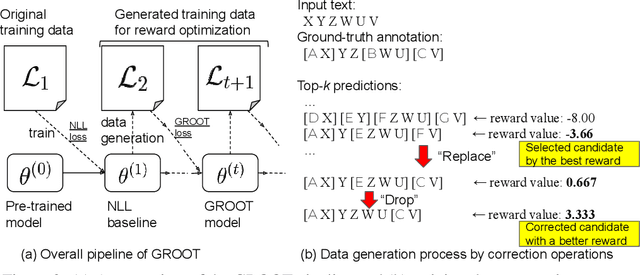
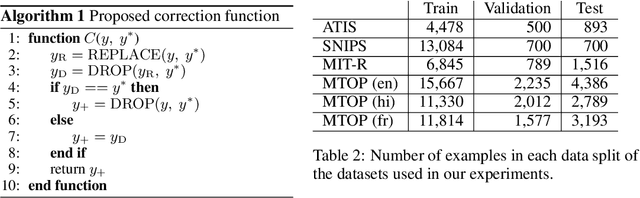
Sequential labeling is a fundamental NLP task, forming the backbone of many applications. Supervised learning of Seq2Seq models (like T5) has shown great success on these problems. However there remains a significant disconnect between the training objectives of these models vs the metrics and desiderata we care about in practical applications. For example, a practical sequence tagging application may want to optimize for a certain precision-recall trade-off (of the top-k predictions) which is quite different from the standard objective of maximizing the likelihood of the gold labeled sequence. Thus to bridge this gap, we propose GROOT -- a simple yet effective framework for Generative Reward Optimization Of Text sequences. GROOT works by training a generative sequential labeling model to match the decoder output distribution with that of the (black-box) reward function. Using an iterative training regime, we first generate prediction candidates, then correct errors in them, and finally contrast those candidates (based on their reward values). As demonstrated via extensive experiments on four public benchmarks, GROOT significantly improves all reward metrics. Furthermore, GROOT also leads to improvements of the overall decoder distribution as evidenced by the quality gains of the top-$k$ candidates.
FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
Sep 28, 2022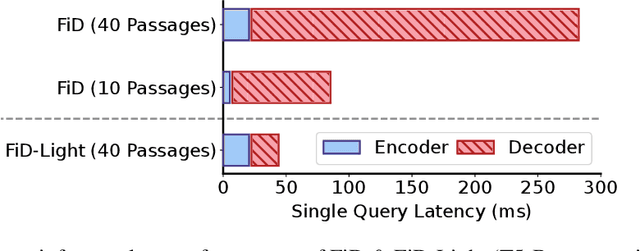
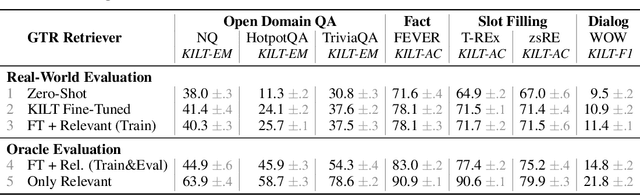
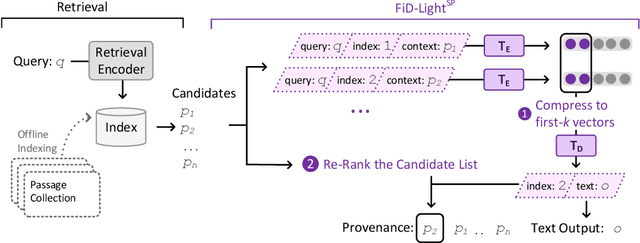
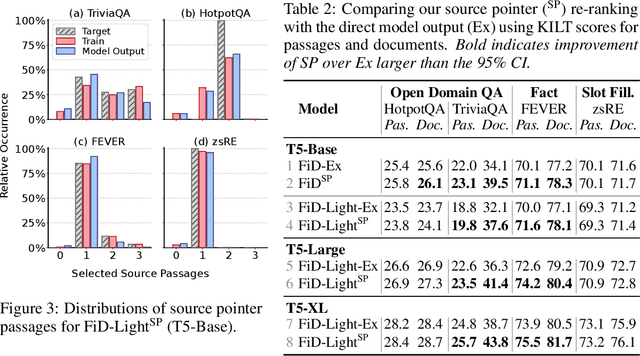
Retrieval-augmented generation models offer many benefits over standalone language models: besides a textual answer to a given query they provide provenance items retrieved from an updateable knowledge base. However, they are also more complex systems and need to handle long inputs. In this work, we introduce FiD-Light to strongly increase the efficiency of the state-of-the-art retrieval-augmented FiD model, while maintaining the same level of effectiveness. Our FiD-Light model constrains the information flow from the encoder (which encodes passages separately) to the decoder (using concatenated encoded representations). Furthermore, we adapt FiD-Light with re-ranking capabilities through textual source pointers, to improve the top-ranked provenance precision. Our experiments on a diverse set of seven knowledge intensive tasks (KILT) show FiD-Light consistently improves the Pareto frontier between query latency and effectiveness. FiD-Light with source pointing sets substantial new state-of-the-art results on six KILT tasks for combined text generation and provenance retrieval evaluation, while maintaining reasonable efficiency.
Multi-Task Retrieval-Augmented Text Generation with Relevance Sampling
Jul 07, 2022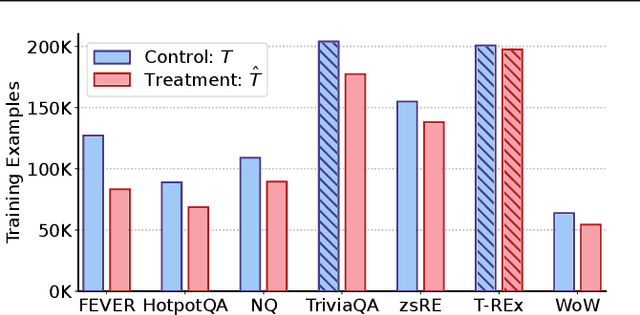
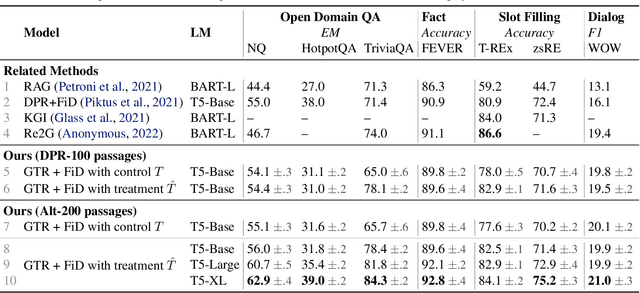
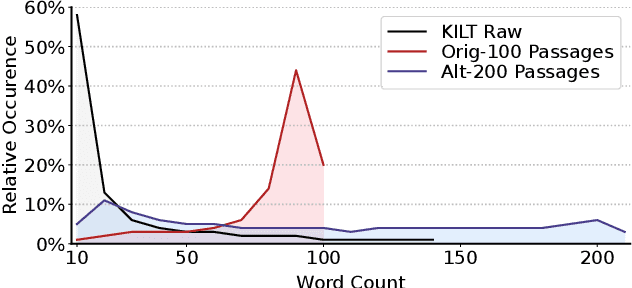
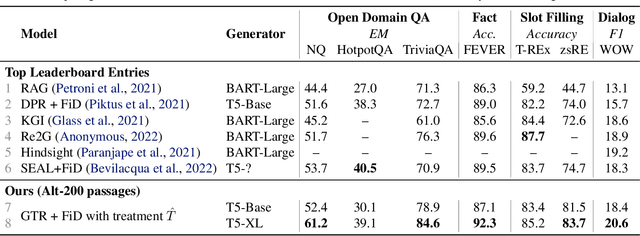
This paper studies multi-task training of retrieval-augmented generation models for knowledge-intensive tasks. We propose to clean the training set by utilizing a distinct property of knowledge-intensive generation: The connection of query-answer pairs to items in the knowledge base. We filter training examples via a threshold of confidence on the relevance labels, whether a pair is answerable by the knowledge base or not. We train a single Fusion-in-Decoder (FiD) generator on seven combined tasks of the KILT benchmark. The experimental results suggest that our simple yet effective approach substantially improves competitive baselines on two strongly imbalanced tasks; and shows either smaller improvements or no significant regression on the remaining tasks. Furthermore, we demonstrate our multi-task training with relevance label sampling scales well with increased model capacity and achieves state-of-the-art results in five out of seven KILT tasks.