 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the First Shared Task on Machine Translation Robustness
Paper and Code

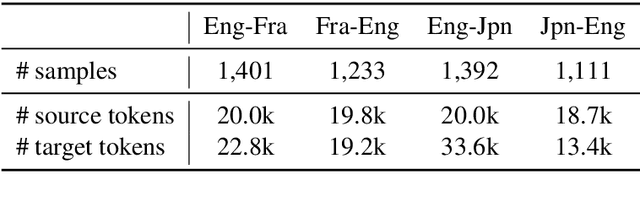
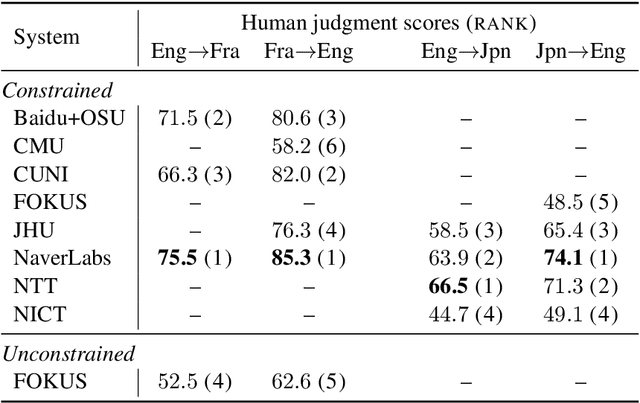
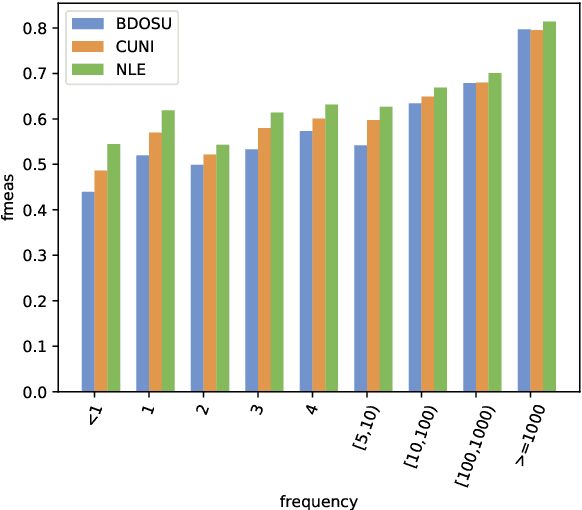
We share the findings of the first shared task on improving robustness of Machine Translation (MT). The task provides a testbed representing challenges facing MT models deployed in the real world, and facilitates new approaches to improve models; robustness to noisy input and domain mismatch. We focus on two language pairs (English-French and English-Japanese), and the submitted systems are evaluated on a blind test set consisting of noisy comments on Reddit and professionally sourced translations. As a new task, we received 23 submissions by 11 participating teams from universities, companies, national labs, etc. All submitted systems achieved large improvements over baselines, with the best improvement having +22.33 BLEU. We evaluated submissions by both human judgment and automatic evaluation (BLEU), which shows high correlations (Pearson's r = 0.94 and 0.95). Furthermore, we conducted a qualitative analysis of the submitted systems using compare-mt, which revealed their salient differences in handling challenges in this task. Such analysis provides additional insights when there is occasional disagreement between human judgment and BLEU, e.g. systems better at producing colloquial expressions received higher score from human judgment.