 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parametric Adaptation for Neural Machine Translation
Paper and Code
Feb 28, 2019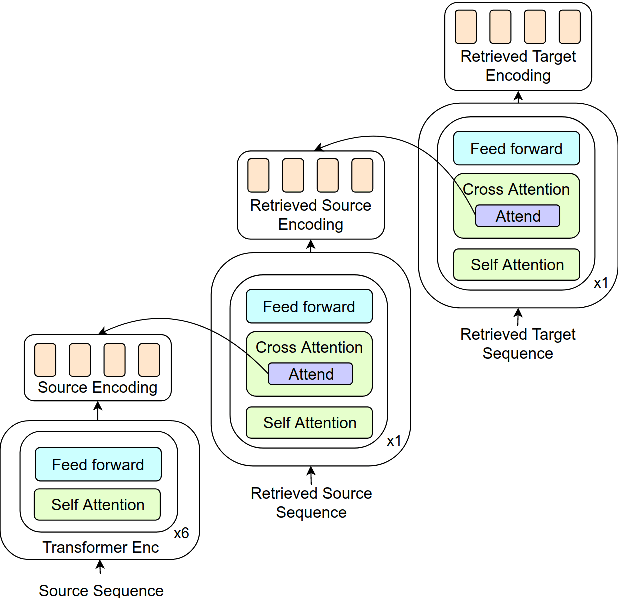

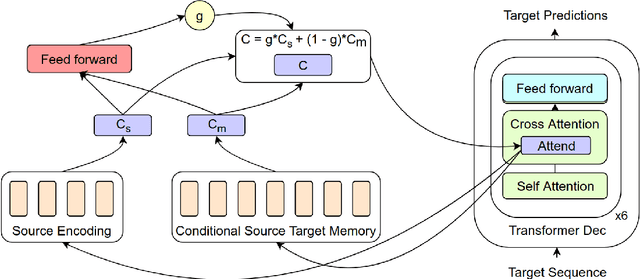

Neural Networks trained with gradient descent are known to be susceptible to catastrophic forgetting caused by parameter shift during the training process. In the context of Neural Machine Translation (NMT) this results in poor performance on heterogeneous datasets and on sub-tasks like rare phrase translation. On the other hand, non-parametric approaches are immune to forgetting, perfectly complementing the generalization ability of NMT. However, attempts to combine non-parametric or retrieval based approaches with NMT have only been successful on narrow domains, possibly due to over-reliance on sentence level retrieval. We propose a novel n-gram level retrieval approach that relies on local phrase level similarities, allowing us to retrieve neighbors that are useful for translation even when overall sentence similarity is low. We complement this with an expressive neural network, allowing our model to extract information from the noisy retrieved context. We evaluate our semi-parametric NMT approach on a heterogeneous dataset composed of WMT, IWSLT, JRC-Acquis and OpenSubtitles, and demonstrate gains on all 4 evaluation sets. The semi-parametric nature of our approach opens the door for non-parametric domain adaptation, demonstrating strong inference-time adaptation performance on new domains without the need for any parameter updates.