 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage modeling via stochastic processes
Mar 21, 2022
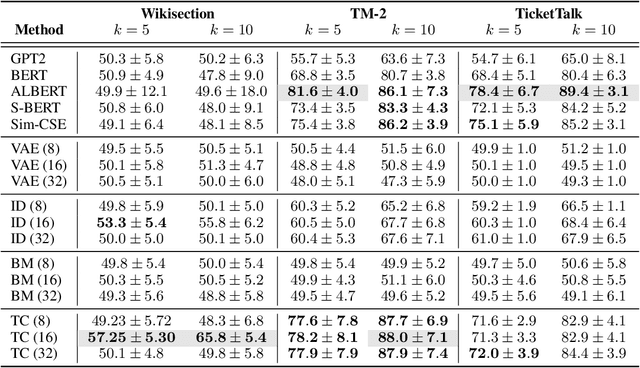
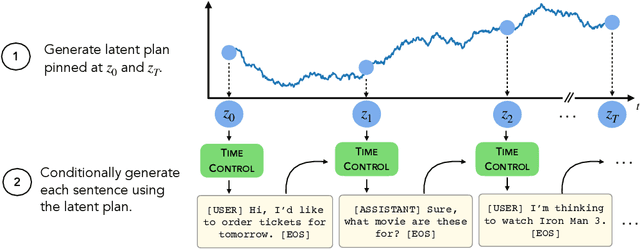
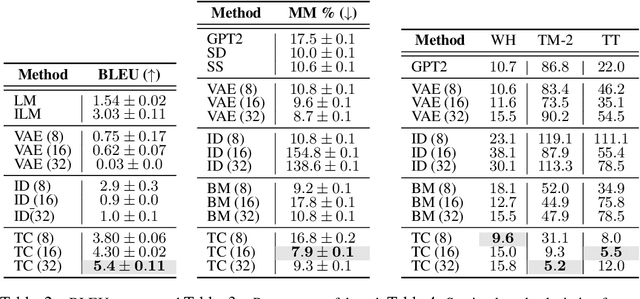
Modern language models can generate high-quality short texts. However, they often meander or are incoherent when generating longer texts. These issues arise from the next-token-only language modeling objective. To address these issues, we introduce Time Control (TC), a language model that implicitly plans via a latent stochastic process. TC does this by learning a representation which maps the dynamics of how text changes in a document to the dynamics of a stochastic process of interest. Using this representation, the language model can generate text by first implicitly generating a document plan via a stochastic process, and then generating text that is consistent with this latent plan. Compared to domain-specific methods and fine-tuning GPT2 across a variety of text domains, TC improves performance on text infilling and discourse coherence. On long text generation settings, TC preserves the text structure both in terms of ordering (up to +40% better) and text length consistency (up to +17% better). Human evaluators also prefer TC's output 28.6% more than the baselines.
Improving Intrinsic Exploration with Language Abstractions
Feb 17, 2022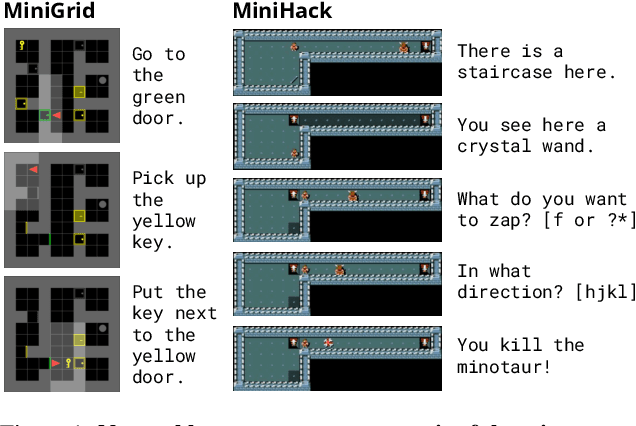
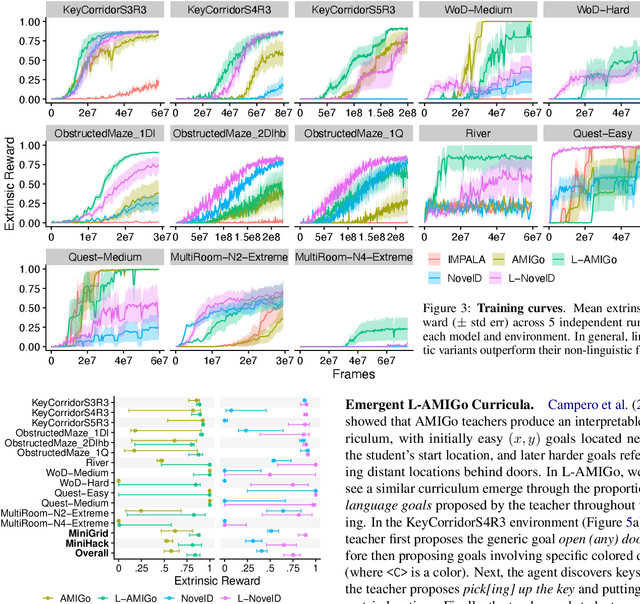
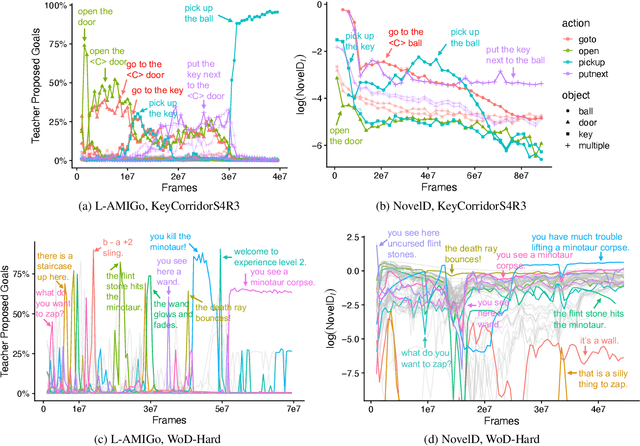
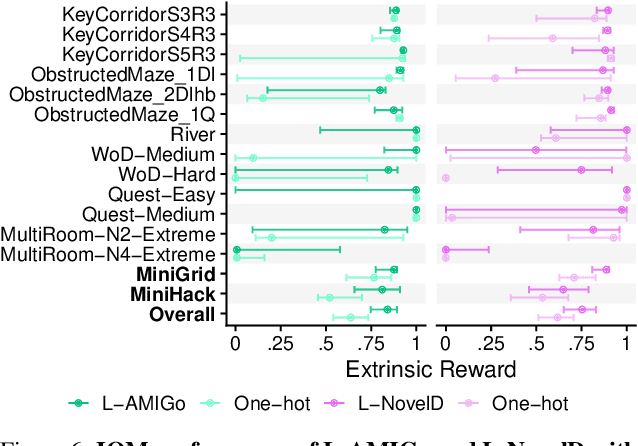
Reinforcement learning (RL) agents are particularly hard to train when rewards are sparse. One common solution is to use intrinsic rewards to encourage agents to explore their environment. However, recent intrinsic exploration methods often use state-based novelty measures which reward low-level exploration and may not scale to domains requiring more abstract skills. Instead, we explore natural language as a general medium for highlighting relevant abstractions in an environment. Unlike previous work, we evaluate whether language can improve over existing exploration methods by directly extending (and comparing to) competitive intrinsic exploration baselines: AMIGo (Campero et al., 2021) and NovelD (Zhang et al., 2021). These language-based variants outperform their non-linguistic forms by 45-85% across 13 challenging tasks from the MiniGrid and MiniHack environment suites.
Tradeoffs Between Contrastive and Supervised Learning: An Empirical Study
Dec 10, 2021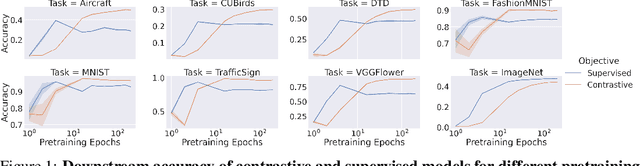
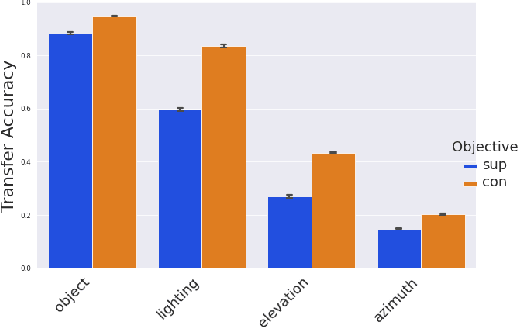
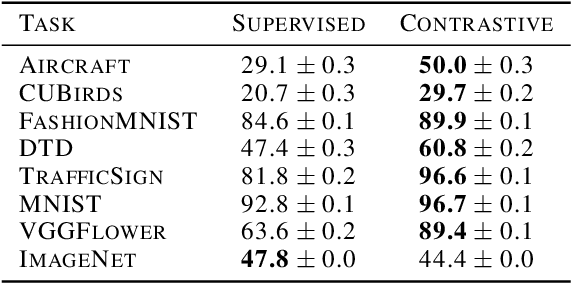
Contrastive learning has made considerable progress in computer vision, outperforming supervised pretraining on a range of downstream datasets. However, is contrastive learning the better choice in all situations? We demonstrate two cases where it is not. First, under sufficiently small pretraining budgets, supervised pretraining on ImageNet consistently outperforms a comparable contrastive model on eight diverse image classification datasets. This suggests that the common practice of comparing pretraining approaches at hundreds or thousands of epochs may not produce actionable insights for those with more limited compute budgets. Second, even with larger pretraining budgets we identify tasks where supervised learning prevails, perhaps because the object-centric bias of supervised pretraining makes the model more resilient to common corruptions and spurious foreground-background correlations. These results underscore the need to characterize tradeoffs of different pretraining objectives across a wider range of contexts and training regimes.
DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning
Nov 23, 2021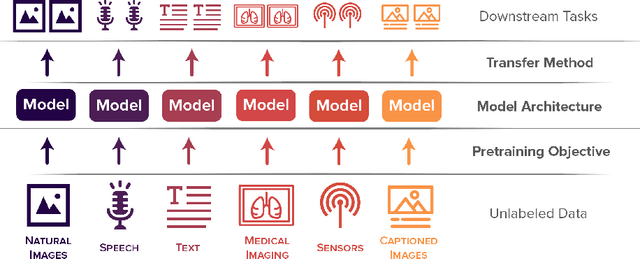

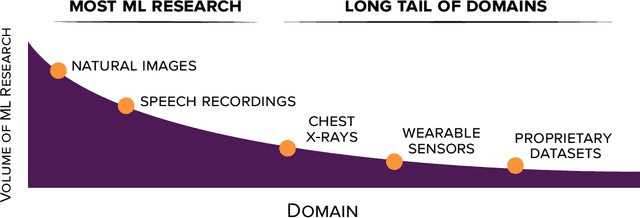
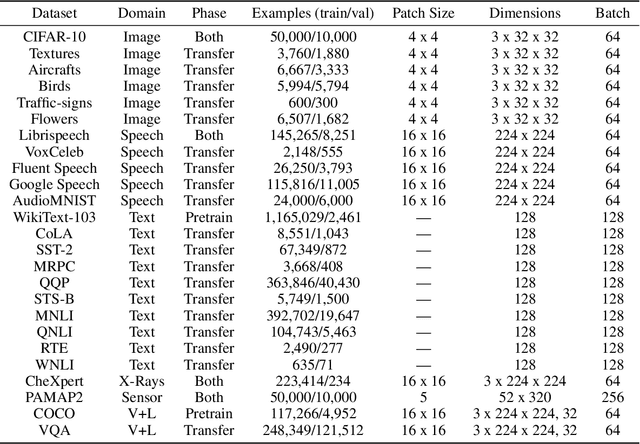
Self-supervised learning algorithms, including BERT and SimCLR, have enabled significant strides in fields like natural language processing, computer vision, and speech processing. However, these algorithms are domain-specific, meaning that new self-supervised learning algorithms must be developed for each new setting, including myriad healthcare, scientific, and multimodal domains. To catalyze progress toward domain-agnostic methods, we introduce DABS: a Domain-Agnostic Benchmark for Self-supervised learning. To perform well on DABS, an algorithm is evaluated on seven diverse domains: natural images, multichannel sensor data, English text, speech recordings, multilingual text, chest x-rays, and images with text descriptions. Each domain contains an unlabeled dataset for pretraining; the model is then is scored based on its downstream performance on a set of labeled tasks in the domain. We also present e-Mix and ShED: two baseline domain-agnostic algorithms; their relatively modest performance demonstrates that significant progress is needed before self-supervised learning is an out-of-the-box solution for arbitrary domains. Code for benchmark datasets and baseline algorithms is available at https://github.com/alextamkin/dabs.
Open-domain clarification question generation without question examples
Oct 19, 2021
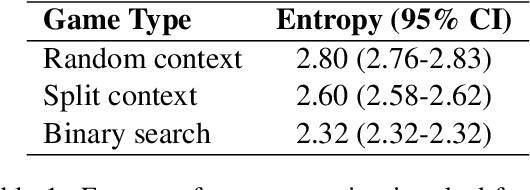
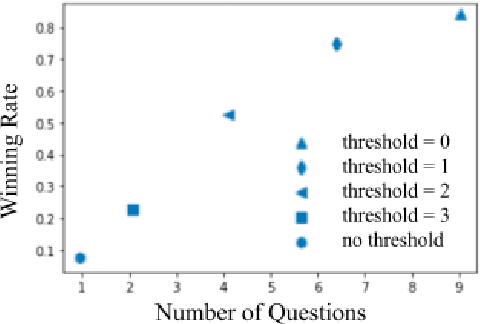

An overarching goal of natural language processing is to enable machines to communicate seamlessly with humans. However, natural language can be ambiguous or unclear. In cases of uncertainty, humans engage in an interactive process known as repair: asking questions and seeking clarification until their uncertainty is resolved. We propose a framework for building a visually grounded question-asking model capable of producing polar (yes-no) clarification questions to resolve misunderstandings in dialogue. Our model uses an expected information gain objective to derive informative questions from an off-the-shelf image captioner without requiring any supervised question-answer data. We demonstrate our model's ability to pose questions that improve communicative success in a goal-oriented 20 questions game with synthetic and human answerers.
Temperature as Uncertainty in Contrastive Learning
Oct 08, 2021
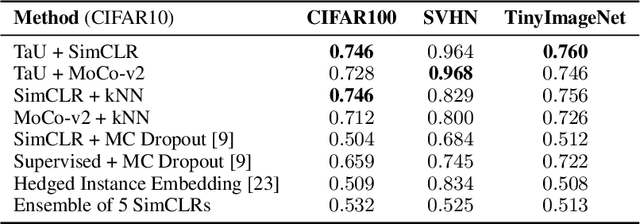


Contrastive learning has demonstrated great capability to learn representations without annotations, even outperforming supervised baselines. However, it still lacks important properties useful for real-world application, one of which is uncertainty. In this paper, we propose a simple way to generate uncertainty scores for many contrastive methods by re-purposing temperature, a mysterious hyperparameter used for scaling. By observing that temperature controls how sensitive the objective is to specific embedding locations, we aim to learn temperature as an input-dependent variable, treating it as a measure of embedding confidence. We call this approach "Temperature as Uncertainty", or TaU. Through experiments, we demonstrate that TaU is useful for out-of-distribution detection, while remaining competitive with benchmarks on linear evaluation. Moreover, we show that TaU can be learned on top of pretrained models, enabling uncertainty scores to be generated post-hoc with popular off-the-shelf models. In summary, TaU is a simple yet versatile method for generating uncertainties for contrastive learning. Open source code can be found at: https://github.com/mhw32/temperature-as-uncertainty-public.
Modeling Item Response Theory with Stochastic Variational Inference
Aug 26, 2021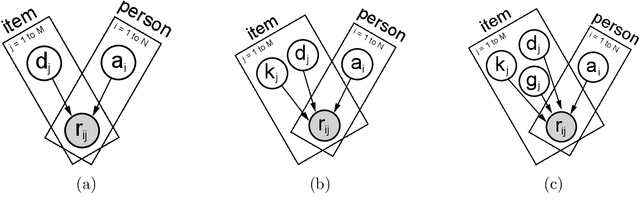
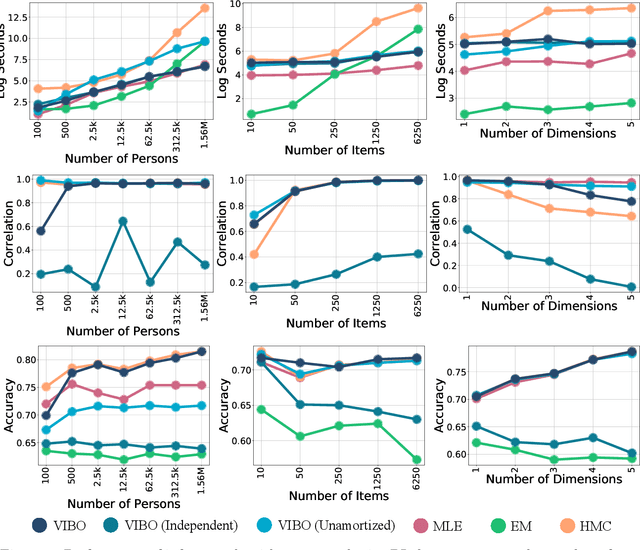
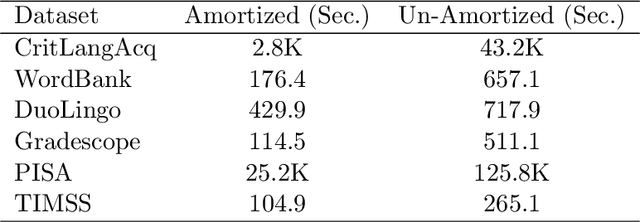
Item Response Theory (IRT) is a ubiquitous model for understanding human behaviors and attitudes based on their responses to questions. Large modern datasets offer opportunities to capture more nuances in human behavior, potentially improving psychometric modeling leading to improved scientific understanding and public policy. However, while larger datasets allow for more flexible approaches, many contemporary algorithms for fitting IRT models may also have massive computational demands that forbid real-world application. To address this bottleneck, we introduce a variational Bayesian inference algorithm for IRT, and show that it is fast and scalable without sacrificing accuracy. Applying this method to five large-scale item response datasets from cognitive science and education yields higher log likelihoods and higher accuracy in imputing missing data than alternative inference algorithms. Using this new inference approach we then generalize IRT with expressive Bayesian models of responses, leveraging recent advances in deep learning to capture nonlinear item characteristic curves (ICC) with neural networks. Using an eigth-grade mathematics test from TIMSS, we show our nonlinear IRT models can capture interesting asymmetric ICCs. The algorithm implementation is open-source, and easily usable.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
ProtoTransformer: A Meta-Learning Approach to Providing Student Feedback
Jul 23, 2021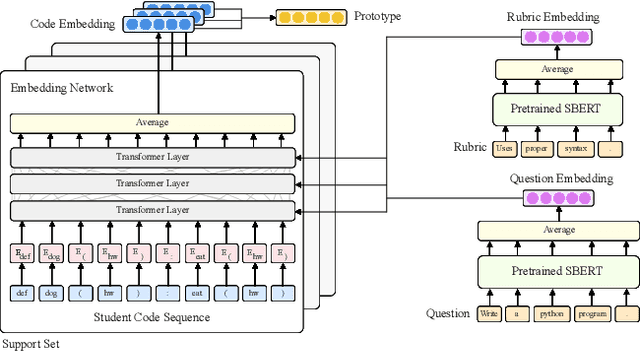



High-quality computer science education is limited by the difficulty of providing instructor feedback to students at scale. While this feedback could in principle be automated, supervised approaches to predicting the correct feedback are bottlenecked by the intractability of annotating large quantities of student code. In this paper, we instead frame the problem of providing feedback as few-shot classification, where a meta-learner adapts to give feedback to student code on a new programming question from just a few examples annotated by instructors. Because data for meta-training is limited, we propose a number of amendments to the typical few-shot learning framework, including task augmentation to create synthetic tasks, and additional side information to build stronger priors about each task. These additions are combined with a transformer architecture to embed discrete sequences (e.g. code) to a prototypical representation of a feedback class label. On a suite of few-shot natural language processing tasks, we match or outperform state-of-the-art performance. Then, on a collection of student solutions to exam questions from an introductory university course, we show that our approach reaches an average precision of 88% on unseen questions, surpassing the 82% precision of teaching assistants. Our approach was successfully deployed to deliver feedback to 16,000 student exam-solutions in a programming course offered by a tier 1 university. This is, to the best of our knowledge, the first successful deployment of a machine learning based feedback to open-ended student code.
Contrastive Reinforcement Learning of Symbolic Reasoning Domains
Jun 16, 2021
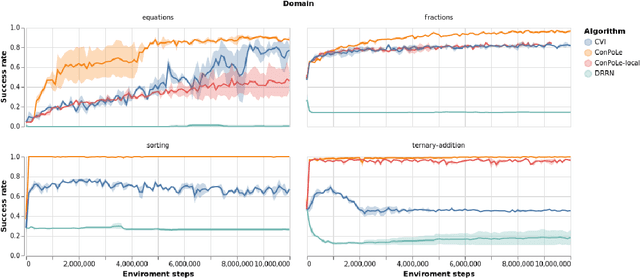
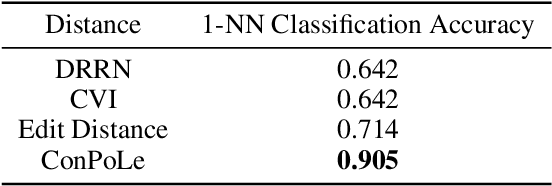
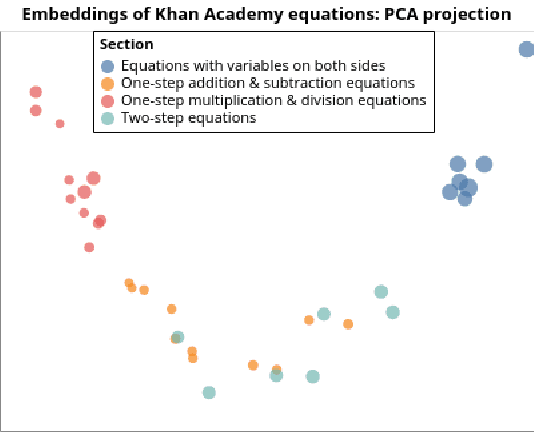
Abstract symbolic reasoning, as required in domains such as mathematics and logic, is a key component of human intelligence. Solvers for these domains have important applications, especially to computer-assisted education. But learning to solve symbolic problems is challenging for machine learning algorithms. Existing models either learn from human solutions or use hand-engineered features, making them expensive to apply in new domains. In this paper, we instead consider symbolic domains as simple environments where states and actions are given as unstructured text, and binary rewards indicate whether a problem is solved. This flexible setup makes it easy to specify new domains, but search and planning become challenging. We introduce four environments inspired by the Mathematics Common Core Curriculum, and observe that existing Reinforcement Learning baselines perform poorly. We then present a novel learning algorithm, Contrastive Policy Learning (ConPoLe) that explicitly optimizes the InfoNCE loss, which lower bounds the mutual information between the current state and next states that continue on a path to the solution. ConPoLe successfully solves all four domains. Moreover, problem representations learned by ConPoLe enable accurate prediction of the categories of problems in a real mathematics curriculum. Our results suggest new directions for reinforcement learning in symbolic domains, as well as applications to mathematics education.