 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Posteriors for Approximate Probabilistic Inference
May 19, 2022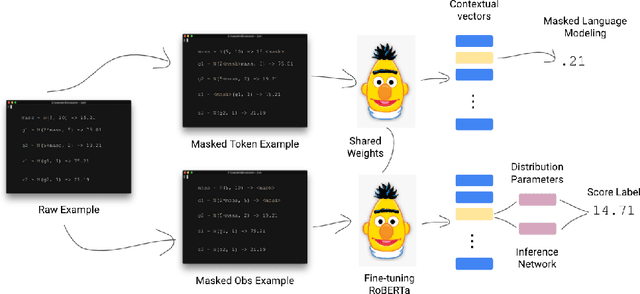
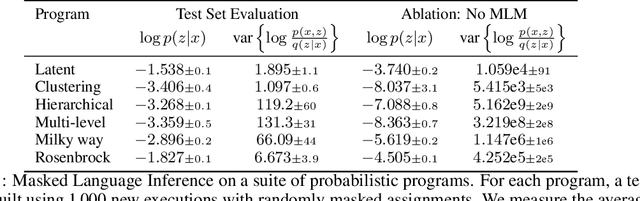

Probabilistic programs provide an expressive representation language for generative models. Given a probabilistic program, we are interested in the task of posterior inference: estimating a latent variable given a set of observed variables. Existing techniques for inference in probabilistic programs often require choosing many hyper-parameters, are computationally expensive, and/or only work for restricted classes of programs. Here we formulate inference as masked language modeling: given a program, we generate a supervised dataset of variables and assignments, and randomly mask a subset of the assignments. We then train a neural network to unmask the random values, defining an approximate posterior distribution. By optimizing a single neural network across a range of programs we amortize the cost of training, yielding a ``foundation'' posterior able to do zero-shot inference for new programs. The foundation posterior can also be fine-tuned for a particular program and dataset by optimizing a variational inference objective. We show the efficacy of the approach, zero-shot and fine-tuned, on a benchmark of STAN programs.
Know Thy Student: Interactive Learning with Gaussian Processes
Apr 26, 2022
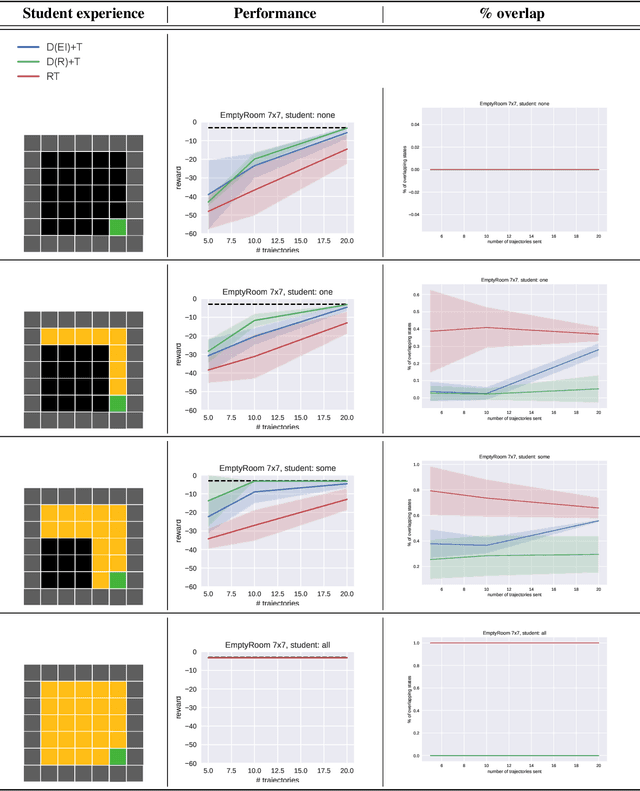

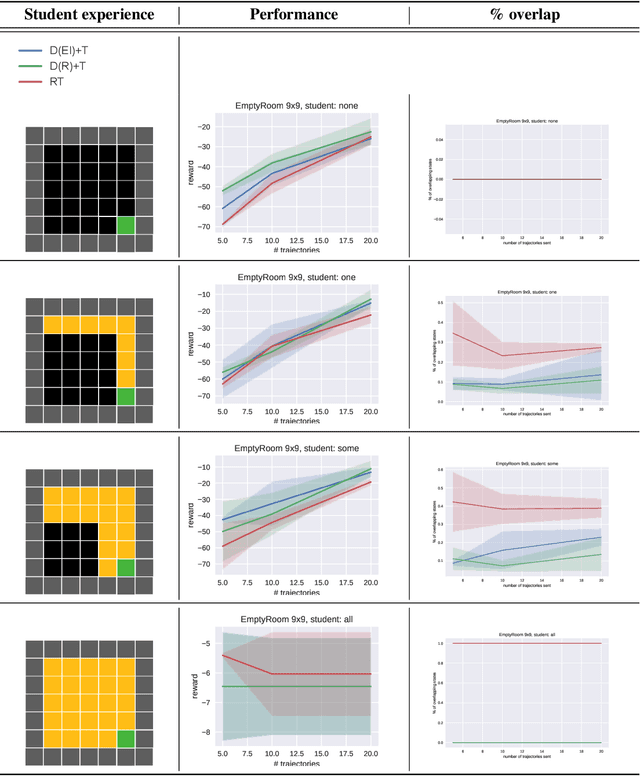
Learning often involves interaction between multiple agents. Human teacher-student settings best illustrate how interactions result in efficient knowledge passing where the teacher constructs a curriculum based on their students' abilities. Prior work in machine teaching studies how the teacher should construct optimal teaching datasets assuming the teacher knows everything about the student. However, in the real world, the teacher doesn't have complete information about the student. The teacher must interact and diagnose the student, before teaching. Our work proposes a simple diagnosis algorithm which uses Gaussian processes for inferring student-related information, before constructing a teaching dataset. We apply this to two settings. One is where the student learns from scratch and the teacher must figure out the student's learning algorithm parameters, eg. the regularization parameters in ridge regression or support vector machines. Two is where the student has partially explored the environment and the teacher must figure out the important areas the student has not explored; we study this in the offline reinforcement learning setting where the teacher must provide demonstrations to the student and avoid sending redundant trajectories. Our experiments highlight the importance of diagosing before teaching and demonstrate how students can learn more efficiently with the help of an interactive teacher. We conclude by outlining where diagnosing combined with teaching would be more desirable than passive learning.
Tutela: An Open-Source Tool for Assessing User-Privacy on Ethereum and Tornado Cash
Jan 18, 2022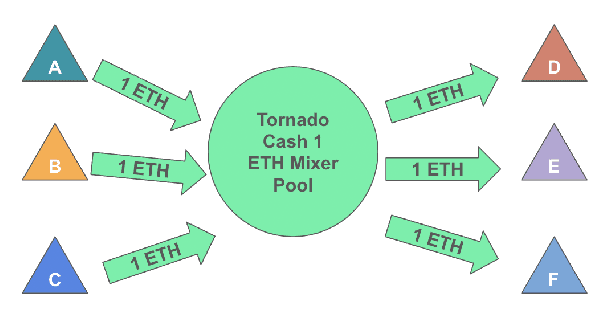
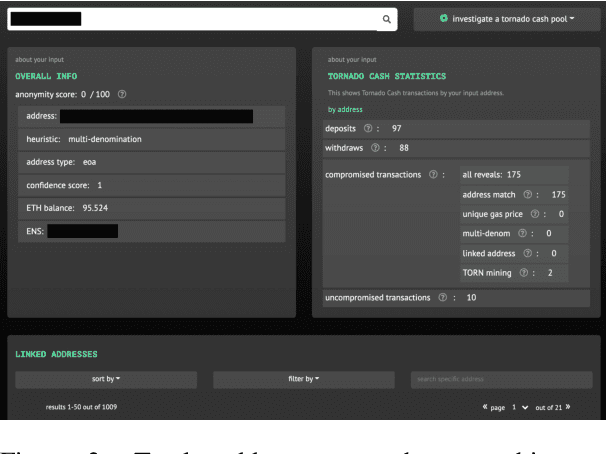
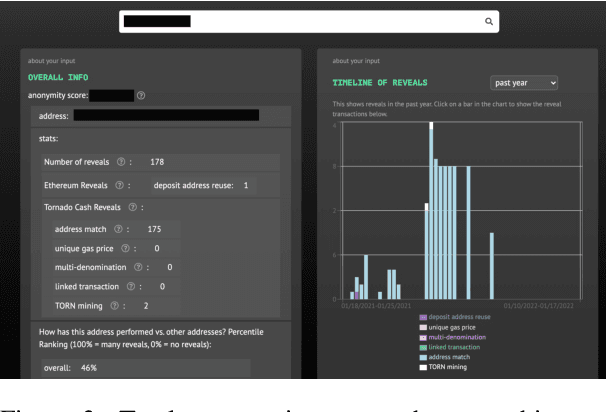
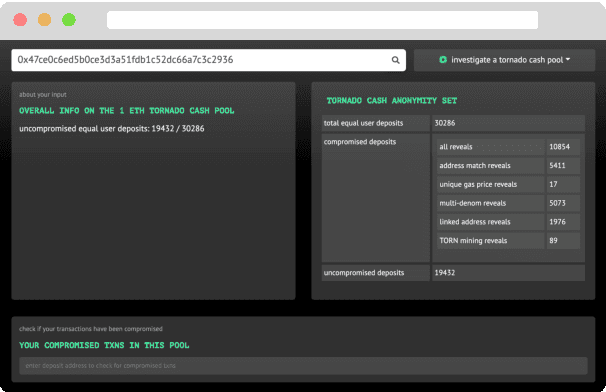
A common misconception among blockchain users is that pseudonymity guarantees privacy. The reality is almost the opposite. Every transaction one makes is recorded on a public ledger and reveals information about one's identity. Mixers, such as Tornado Cash, were developed to preserve privacy through "mixing" transactions with those of others in an anonymity pool, making it harder to link deposits and withdrawals from the pool. Unfortunately, it is still possible to reveal information about those in the anonymity pool if users are not careful. We introduce Tutela, an application built on expert heuristics to report the true anonymity of an Ethereum address. In particular, Tutela has three functionalities: first, it clusters together Ethereum addresses based on interaction history such that for an Ethereum address, we can identify other addresses likely owned by the same entity; second, it shows Ethereum users their potentially compromised transactions; third, Tutela computes the true size of the anonymity pool of each Tornado Cash mixer by excluding potentially compromised transactions. A public implementation of Tutela can be found at https://github.com/TutelaLabs/tutela-app. To use Tutela, visit https://www.tutela.xyz.
Tradeoffs Between Contrastive and Supervised Learning: An Empirical Study
Dec 10, 2021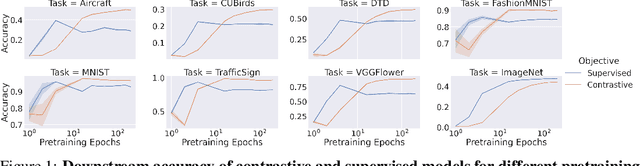
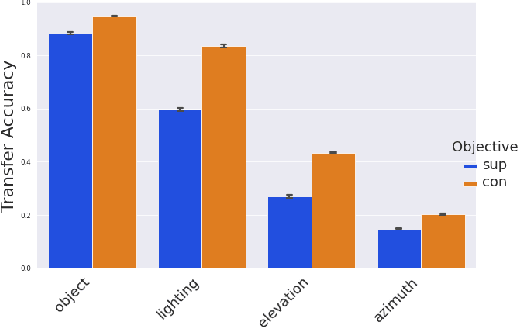
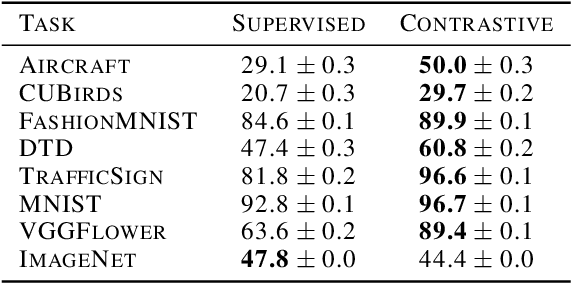
Contrastive learning has made considerable progress in computer vision, outperforming supervised pretraining on a range of downstream datasets. However, is contrastive learning the better choice in all situations? We demonstrate two cases where it is not. First, under sufficiently small pretraining budgets, supervised pretraining on ImageNet consistently outperforms a comparable contrastive model on eight diverse image classification datasets. This suggests that the common practice of comparing pretraining approaches at hundreds or thousands of epochs may not produce actionable insights for those with more limited compute budgets. Second, even with larger pretraining budgets we identify tasks where supervised learning prevails, perhaps because the object-centric bias of supervised pretraining makes the model more resilient to common corruptions and spurious foreground-background correlations. These results underscore the need to characterize tradeoffs of different pretraining objectives across a wider range of contexts and training regimes.
Temperature as Uncertainty in Contrastive Learning
Oct 08, 2021
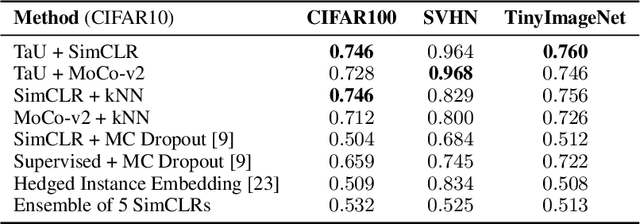


Contrastive learning has demonstrated great capability to learn representations without annotations, even outperforming supervised baselines. However, it still lacks important properties useful for real-world application, one of which is uncertainty. In this paper, we propose a simple way to generate uncertainty scores for many contrastive methods by re-purposing temperature, a mysterious hyperparameter used for scaling. By observing that temperature controls how sensitive the objective is to specific embedding locations, we aim to learn temperature as an input-dependent variable, treating it as a measure of embedding confidence. We call this approach "Temperature as Uncertainty", or TaU. Through experiments, we demonstrate that TaU is useful for out-of-distribution detection, while remaining competitive with benchmarks on linear evaluation. Moreover, we show that TaU can be learned on top of pretrained models, enabling uncertainty scores to be generated post-hoc with popular off-the-shelf models. In summary, TaU is a simple yet versatile method for generating uncertainties for contrastive learning. Open source code can be found at: https://github.com/mhw32/temperature-as-uncertainty-public.
Modeling Item Response Theory with Stochastic Variational Inference
Aug 26, 2021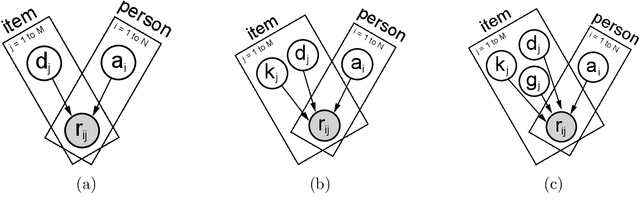
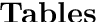
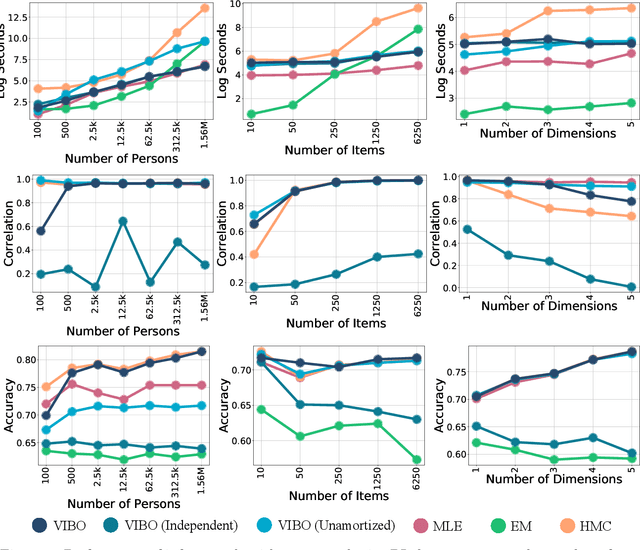
Item Response Theory (IRT) is a ubiquitous model for understanding human behaviors and attitudes based on their responses to questions. Large modern datasets offer opportunities to capture more nuances in human behavior, potentially improving psychometric modeling leading to improved scientific understanding and public policy. However, while larger datasets allow for more flexible approaches, many contemporary algorithms for fitting IRT models may also have massive computational demands that forbid real-world application. To address this bottleneck, we introduce a variational Bayesian inference algorithm for IRT, and show that it is fast and scalable without sacrificing accuracy. Applying this method to five large-scale item response datasets from cognitive science and education yields higher log likelihoods and higher accuracy in imputing missing data than alternative inference algorithms. Using this new inference approach we then generalize IRT with expressive Bayesian models of responses, leveraging recent advances in deep learning to capture nonlinear item characteristic curves (ICC) with neural networks. Using an eigth-grade mathematics test from TIMSS, we show our nonlinear IRT models can capture interesting asymmetric ICCs. The algorithm implementation is open-source, and easily usable.
ProtoTransformer: A Meta-Learning Approach to Providing Student Feedback
Jul 23, 2021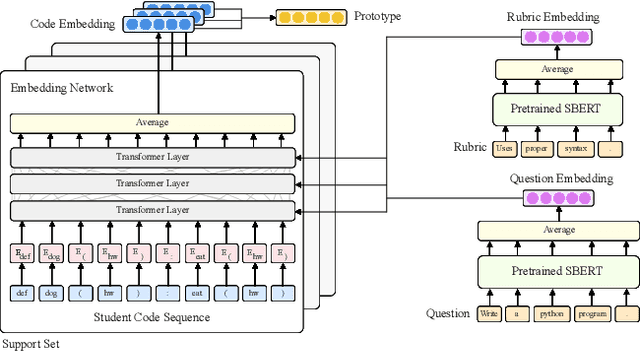



High-quality computer science education is limited by the difficulty of providing instructor feedback to students at scale. While this feedback could in principle be automated, supervised approaches to predicting the correct feedback are bottlenecked by the intractability of annotating large quantities of student code. In this paper, we instead frame the problem of providing feedback as few-shot classification, where a meta-learner adapts to give feedback to student code on a new programming question from just a few examples annotated by instructors. Because data for meta-training is limited, we propose a number of amendments to the typical few-shot learning framework, including task augmentation to create synthetic tasks, and additional side information to build stronger priors about each task. These additions are combined with a transformer architecture to embed discrete sequences (e.g. code) to a prototypical representation of a feedback class label. On a suite of few-shot natural language processing tasks, we match or outperform state-of-the-art performance. Then, on a collection of student solutions to exam questions from an introductory university course, we show that our approach reaches an average precision of 88% on unseen questions, surpassing the 82% precision of teaching assistants. Our approach was successfully deployed to deliver feedback to 16,000 student exam-solutions in a programming course offered by a tier 1 university. This is, to the best of our knowledge, the first successful deployment of a machine learning based feedback to open-ended student code.
Improving Compositionality of Neural Networks by Decoding Representations to Inputs
Jun 01, 2021
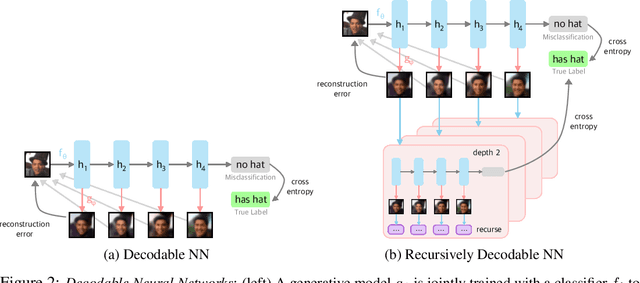
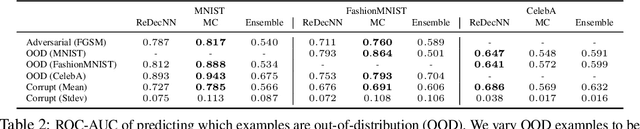

In traditional software programs, we take for granted how easy it is to debug code by tracing program logic from variables back to input, apply unit tests and assertion statements to block erroneous behavior, and compose programs together. But as the programs we write grow more complex, it becomes hard to apply traditional software to applications like computer vision or natural language. Although deep learning programs have demonstrated strong performance on these applications, they sacrifice many of the functionalities of traditional software programs. In this paper, we work towards bridging the benefits of traditional and deep learning programs by jointly training a generative model to constrain neural network activations to "decode" back to inputs. Doing so enables practitioners to probe and track information encoded in activation(s), apply assertion-like constraints on what information is encoded in an activation, and compose separate neural networks together in a plug-and-play fashion. In our experiments, we demonstrate applications of decodable representations to out-of-distribution detection, adversarial examples, calibration, and fairness -- while matching standard neural networks in accuracy.
HarperValleyBank: A Domain-Specific Spoken Dialog Corpus
Oct 26, 2020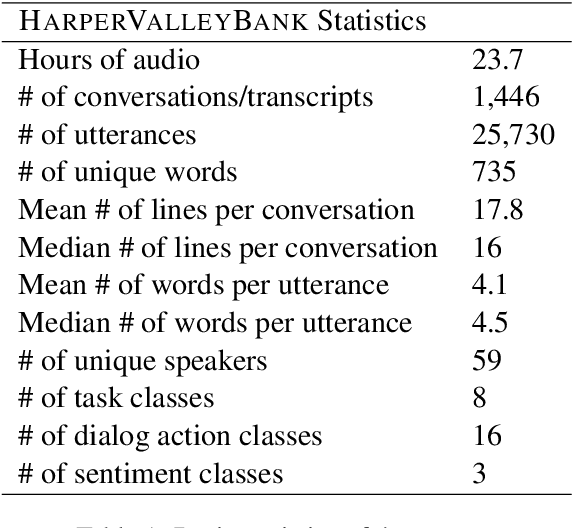
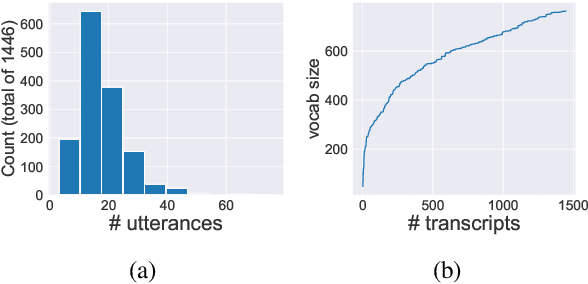
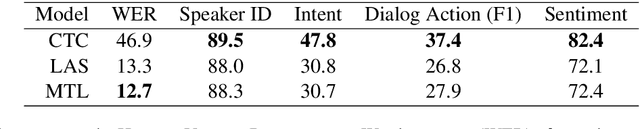
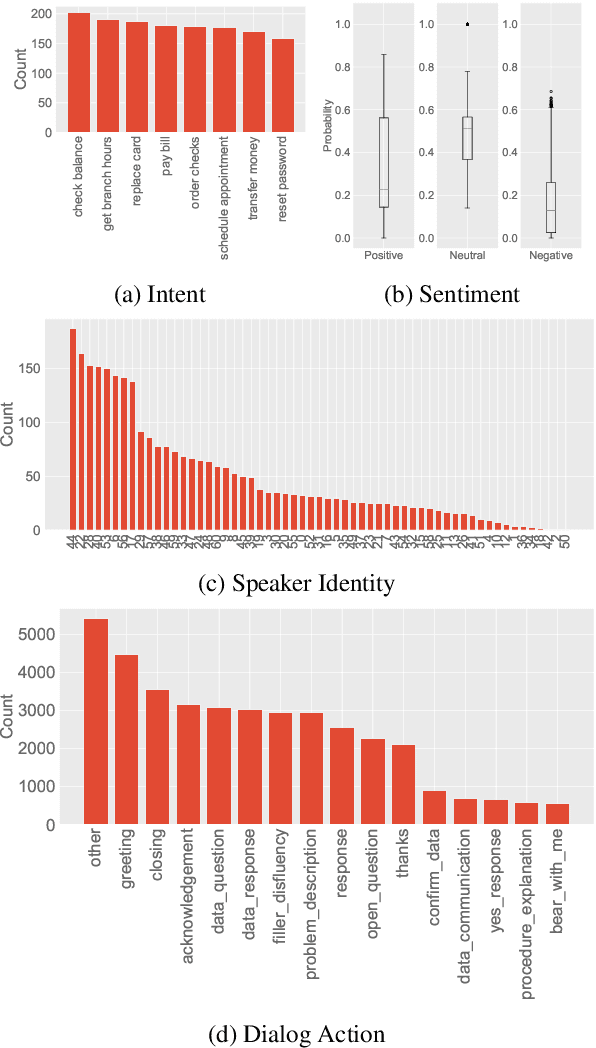
We introduce HarperValleyBank, a free, public domain spoken dialog corpus. The data simulate simple consumer banking interactions, containing about 23 hours of audio from 1,446 human-human conversations between 59 unique speakers. We selected intents and utterance templates to allow realistic variation while controlling overall task complexity and limiting vocabulary size to about 700 unique words. We provide audio data along with transcripts and annotations for speaker ID, caller intent, dialog actions, and emotional valence. The size and domain specificity of this data makes for quick experiments with modern end-to-end neural approaches. Further, we provide baselines for representation learning and transfer tasks. These experiments adapt recent work to embed utterances and use the resulting representations in prediction tasks. Our experiments show that tasks using our annotations are sensitive to both the model choice and corpus size for representation learning approaches.
Viewmaker Networks: Learning Views for Unsupervised Representation Learning
Oct 14, 2020
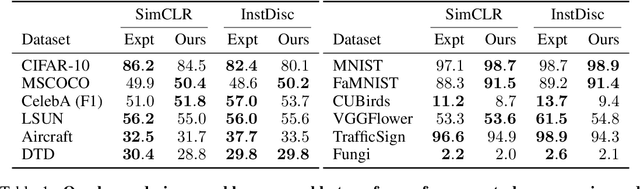
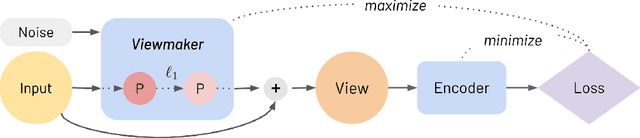
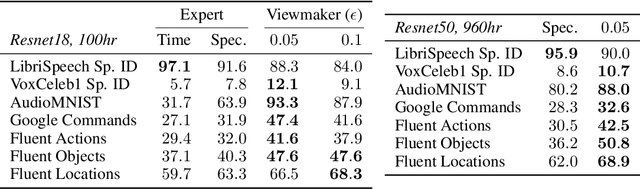
Many recent methods for unsupervised representation learning involve training models to be invariant to different "views," or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial $\ell_p$ perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.