 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing Zhou
Multi-Agent Interactions Modeling with Correlated Policies
Jan 20, 2020
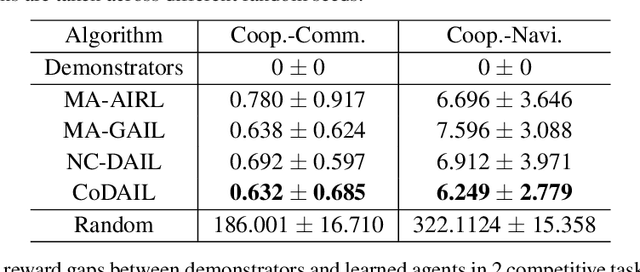
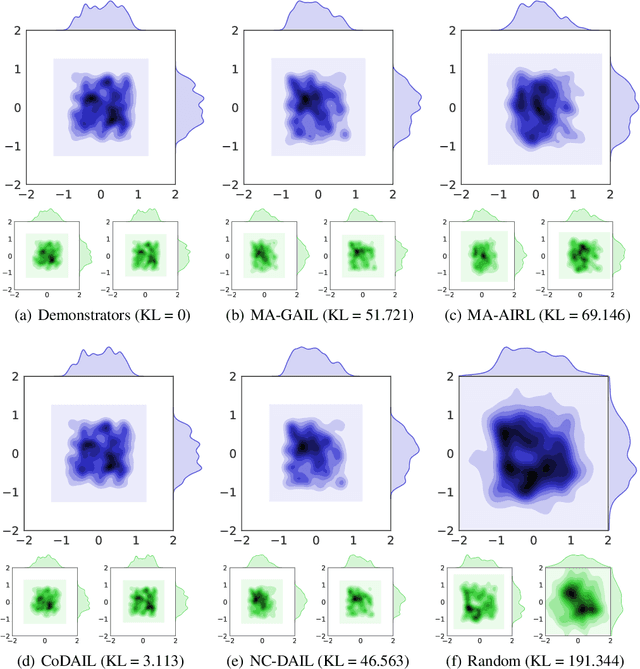
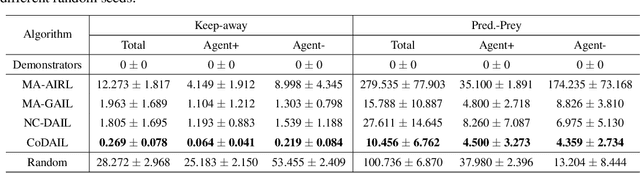
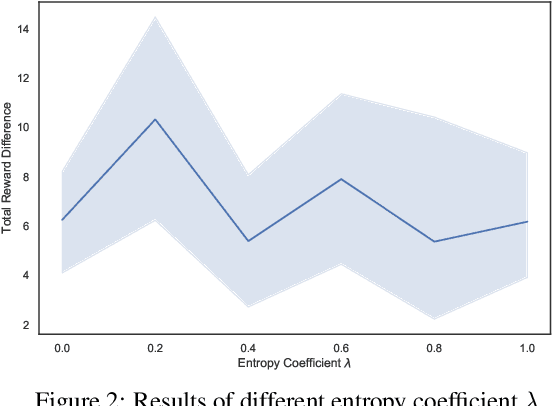
In multi-agent systems, complex interacting behaviors arise due to the high correlations among agents. However, previous work on modeling multi-agent interactions from demonstrations is primarily constrained by assuming the independence among policies and their reward structures. In this paper, we cast the multi-agent interactions modeling problem into a multi-agent imitation learning framework with explicit modeling of correlated policies by approximating opponents' policies, which can recover agents' policies that can regenerate similar interactions. Consequently, we develop a Decentralized Adversarial Imitation Learning algorithm with Correlated policies (CoDAIL), which allows for decentralized training and execution. Various experiments demonstrate that CoDAIL can better regenerate complex interactions close to the demonstrators and outperforms state-of-the-art multi-agent imitation learning methods. Our code is available at \url{https://github.com/apexrl/CoDAIL}.
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training
Jan 13, 2020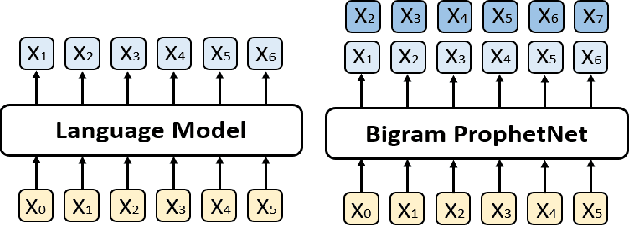
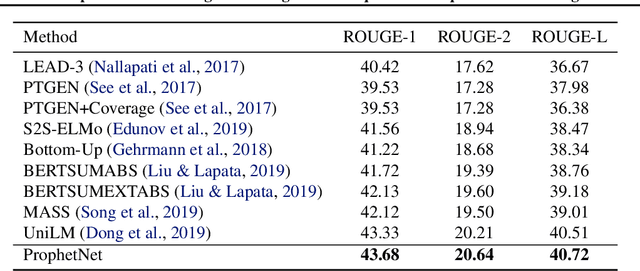
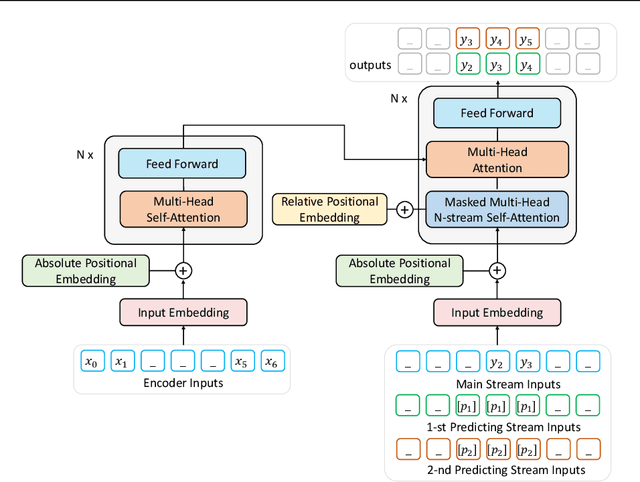
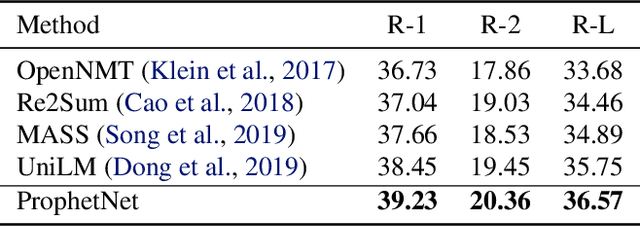
In this paper, we present a new sequence-to-sequence pre-training model called ProphetNet, which introduces a novel self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism.Instead of the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time step.The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale dataset (160GB) respectively. Experimental results show ProphetNet achieves the best performance on both abstractive summarization and question generation tasks compared to the models using the same base scale pre-training dataset. For the large scale dataset pre-training, ProphetNet achieves new state-of-the-art results on Gigaword and comparable results on CNN/DailyMail using only about 1/5 pre-training epochs of the previous model.
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
Dec 31, 2019
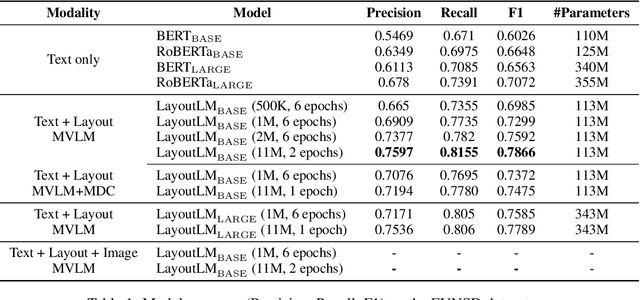
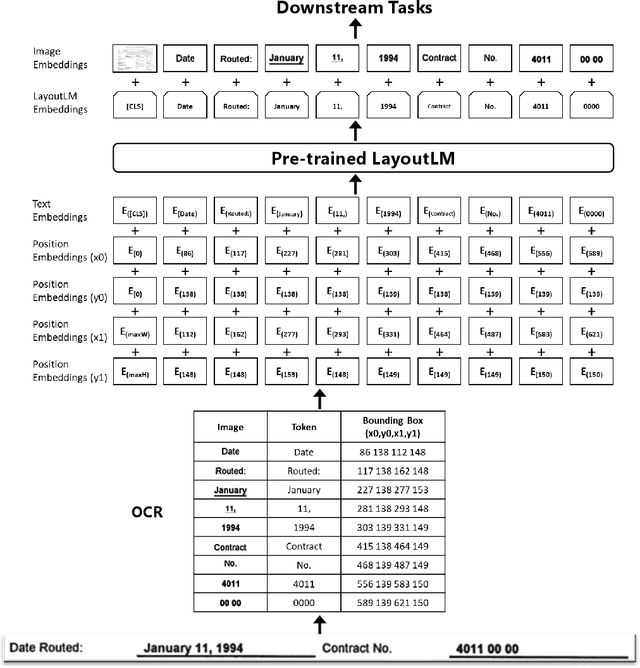
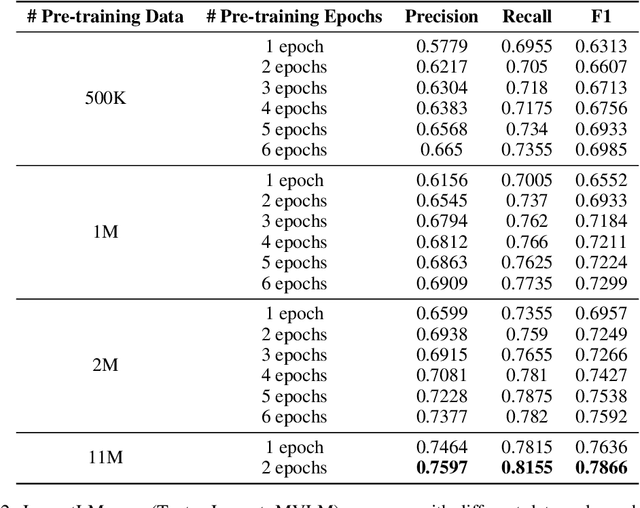
Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the wide spread of pre-training models for NLP applications, they almost focused on text-level manipulation, while neglecting the layout and style information that is vital for document image understanding. In this paper, we propose \textbf{LayoutLM} to jointly model the interaction between text and layout information across scanned document images, which is beneficial for a great number of real-world document image understanding tasks such as information extraction from scanned documents. We also leverage the image features to incorporate the style information of words in LayoutLM. To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for document-level pre-training, leading to significant performance improvement in downstream tasks for document image understanding.
Semantic Mask for Transformer based End-to-End Speech Recognition
Dec 06, 2019
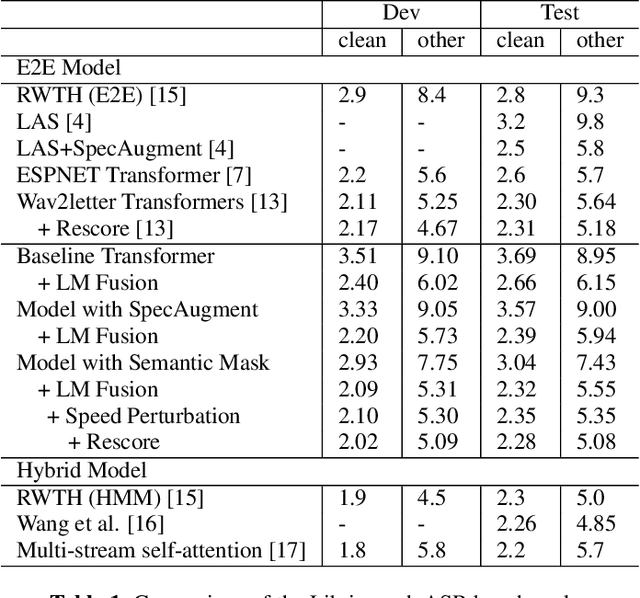
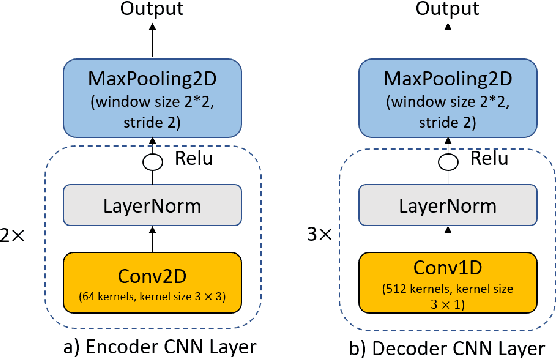
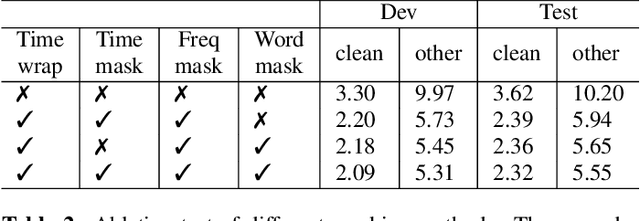
Attention-based encoder-decoder model has achieved impressive results for both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. This approach takes advantage of the memorization capacity of neural networks to learn the mapping from the input sequence to the output sequence from scratch, without the assumption of prior knowledge such as the alignments. However, this model is prone to overfitting, especially when the amount of training data is limited. Inspired by SpecAugment and BERT, in this paper, we propose a semantic mask based regularization for training such kind of end-to-end (E2E) model. The idea is to mask the input features corresponding to a particular output token, e.g., a word or a word-piece, in order to encourage the model to fill the token based on the contextual information. While this approach is applicable to the encoder-decoder framework with any type of neural network architecture, we study the transformer-based model for ASR in this work. We perform experiments on Librispeech 960h and TedLium2 data sets, and achieve the state-of-the-art performance on the test set in the scope of E2E models.
Improving Grammatical Error Correction with Machine Translation Pairs
Nov 07, 2019



We propose a novel data synthesis method to generate diverse error-corrected sentence pairs for improving grammatical error correction, which is based on a pair of machine translation models of different qualities (i.e., poor and good). The poor translation model resembles the ESL (English as a second language) learner and tends to generate translations of low quality in terms of fluency and grammatical correctness, while the good translation model generally generates fluent and grammatically correct translations. We build the poor and good translation model with phrase-based statistical machine translation model with decreased language model weight and neural machine translation model respectively. By taking the pair of their translations of the same sentences in a bridge language as error-corrected sentence pairs, we can construct unlimited pseudo parallel data. Our approach is capable of generating diverse fluency-improving patterns without being limited by the pre-defined rule set and the seed error-corrected data. Experimental results demonstrate the effectiveness of our approach and show that it can be combined with other synthetic data sources to yield further improvements.
Multi-Agent Reinforcement Learning for Order-dispatching via Order-Vehicle Distribution Matching
Oct 07, 2019


Improving the efficiency of dispatching orders to vehicles is a research hotspot in online ride-hailing systems. Most of the existing solutions for order-dispatching are centralized controlling, which require to consider all possible matches between available orders and vehicles. For large-scale ride-sharing platforms, there are thousands of vehicles and orders to be matched at every second which is of very high computational cost. In this paper, we propose a decentralized execution order-dispatching method based on multi-agent reinforcement learning to address the large-scale order-dispatching problem. Different from the previous cooperative multi-agent reinforcement learning algorithms, in our method, all agents work independently with the guidance from an evaluation of the joint policy since there is no need for communication or explicit cooperation between agents. Furthermore, we use KL-divergence optimization at each time step to speed up the learning process and to balance the vehicles (supply) and orders (demand). Experiments on both the explanatory environment and real-world simulator show that the proposed method outperforms the baselines in terms of accumulated driver income (ADI) and Order Response Rate (ORR) in various traffic environments. Besides, with the support of the online platform of Didi Chuxing, we designed a hybrid system to deploy our model.
Sequence-to-sequence Pre-training with Data Augmentation for Sentence Rewriting
Sep 20, 2019
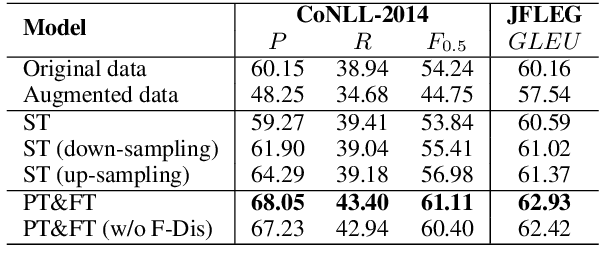
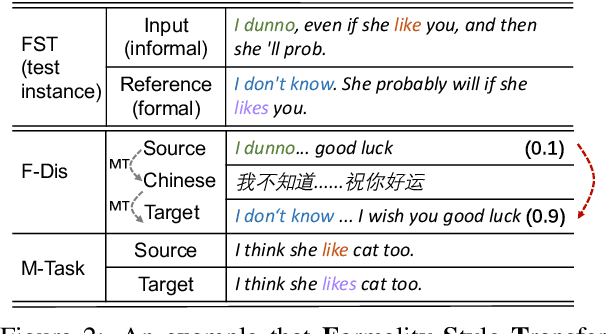
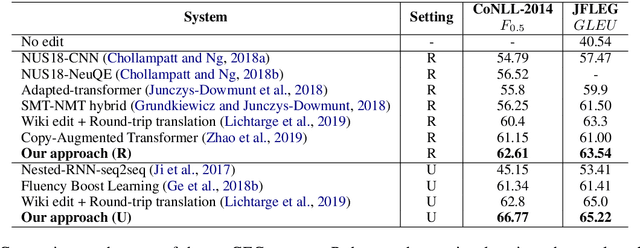
We study sequence-to-sequence (seq2seq) pre-training with data augmentation for sentence rewriting. Instead of training a seq2seq model with gold training data and augmented data simultaneously, we separate them to train in different phases: pre-training with the augmented data and fine-tuning with the gold data. We also introduce multiple data augmentation methods to help model pre-training for sentence rewriting. We evaluate our approach in two typical well-defined sentence rewriting tasks: Grammatical Error Correction (GEC) and Formality Style Transfer (FST). Experiments demonstrate our approach can better utilize augmented data without hurting the model's trust in gold data and further improve the model's performance with our proposed data augmentation methods. Our approach substantially advances the state-of-the-art results in well-recognized sentence rewriting benchmarks over both GEC and FST. Specifically, it pushes the CoNLL-2014 benchmark's $F_{0.5}$ score and JFLEG Test GLEU score to 62.61 and 63.54 in the restricted training setting, 66.77 and 65.22 respectively in the unrestricted setting, and advances GYAFC benchmark's BLEU to 74.24 (2.23 absolute improvement) in E&M domain and 77.97 (2.64 absolute improvement) in F&R domain.
Bridging the Gap between Pre-Training and Fine-Tuning for End-to-End Speech Translation
Sep 19, 2019

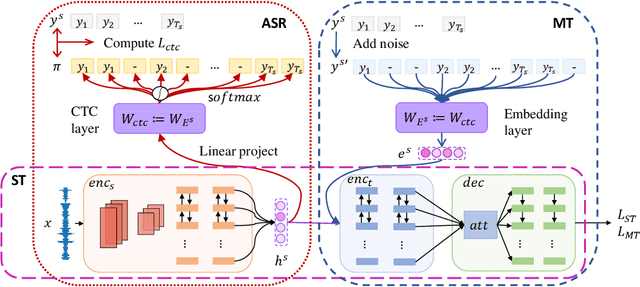

End-to-end speech translation, a hot topic in recent years, aims to translate a segment of audio into a specific language with an end-to-end model. Conventional approaches employ multi-task learning and pre-training methods for this task, but they suffer from the huge gap between pre-training and fine-tuning. To address these issues, we propose a Tandem Connectionist Encoding Network (TCEN) which bridges the gap by reusing all subnets in fine-tuning, keeping the roles of subnets consistent, and pre-training the attention module. Furthermore, we propose two simple but effective methods to guarantee the speech encoder outputs and the MT encoder inputs are consistent in terms of semantic representation and sequence length. Experimental results show that our model outperforms baselines 2.2 BLEU on a large benchmark dataset.