 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIM-Loc: BIM-Integrated Discrepancy-Aware LiDAR-based Indoor Localization
Jun 12, 2026Accurate and robust localization is a fundamental requirement for service and inspection robots, particularly in feature-sparse indoor environments where traditional systems struggle due to a lack of distinct landmarks. While prior maps can enhance robustness, precise and compact maps capturing real-world details are often unavailable for new or frequently changing environments. This paper presents BIM-Loc, a novel discrepancy-aware LiDAR-based localization method that directly integrates Building Information Models (BIM) from the design phase. BIM-Loc simultaneously estimates trajectories aligned with the BIM coordinate system and identifies discrepancies between real-world observations and the as-designed BIM in an online fashion. Our core contributions include: (1) a novel multi-hit ray casting strategy for efficient BIM-point data association and projection of 3D observations into 2D texture space; (2) a pose graph optimization framework with BIM-integrated factors that enforces consistency among odometry, sequential scans, and BIM structures; and (3) a hierarchical Bayesian inference module that incrementally updates a continuous 2D surface representation for discrepancy detection, propagating updates from the pixel to the structure level. Extensive evaluations in both simulation and real-world applications demonstrate that BIM-Loc significantly outperforms state-of-the-art map-based methods in localization accuracy and robustness.
Optimizing In Vivo Oral Lesion Classification from Electrical Impedance Spectroscopy Using Data-driven Approaches
May 07, 2026Oral cancer is a significant global health burden, and early detection remains a critical clinical need. Electrical impedance spectroscopy (EIS) offers a promising non-invasive approach for real-time tissue characterization, but classification frameworks that jointly leverage multiple impedance features for in vivo oral lesion discrimination remain underdeveloped. This paper presents a machine-learning (ML) pipeline to optimize classification of in vivo oral pathology from EIS data collected using a handheld, bedside device. Impedance measurements were acquired from 104 patients undergoing oral cancer resection or biopsy. Three classification tasks were evaluated: (1) healthy vs. cancer, (2) multi-class lesion-type discrimination (cancer, high-grade dysplasia, non-malignant), and (3) multi-class discrimination between the three lesion pathologies and healthy tissue. For each task, signal frequencies were independently ranked and reduced using PCA, and different current injection/voltage measurement (IIVV) pattern geometries were tested. Classification performance was assessed through leave-one-patient-group-out cross-validation to ensure robustness on unseen patients. Input data dimensionality was reduced by up to 99% across all tasks while improving diagnostic accuracy over baseline models trained on the full dataset. A logistic regression model achieved the highest binary classification accuracy of 80% with an AUC of 0.90, while multi-class scenarios maintained AUCs above 0.82. All top-performing models utilized the significantly reduced IIVV set as input. The proposed pipeline advances EIS-based cancer detection by providing a robust, computationally efficient, and clinically practical framework for early diagnosis of oral cancer lesions, with a methodology readily generalizable to other EIS devices and applications.
Reinforcement Learning with Promising Tokens for Large Language Models
Feb 03, 2026Reinforcement learning (RL) has emerged as a key paradigm for aligning and optimizing large language models (LLMs). Standard approaches treat the LLM as the policy and apply RL directly over the full vocabulary space. However, this formulation includes the massive tail of contextually irrelevant tokens in the action space, which could distract the policy from focusing on decision-making among the truly reasonable tokens. In this work, we verify that valid reasoning paths could inherently concentrate within a low-rank subspace. Based on this insight, we introduce Reinforcement Learning with Promising Tokens (RLPT), a framework that mitigates the action space issue by decoupling strategic decision-making from token generation. Specifically, RLPT leverages the semantic priors of the base model to identify a dynamic set of \emph{promising tokens} and constrains policy optimization exclusively to this refined subset via masking. Theoretical analysis and empirical results demonstrate that RLPT effectively reduces gradient variance, stabilizes the training process, and improves sample efficiency. Experiment results on math, coding, and telecom reasoning show that RLPT outperforms standard RL baselines and integrates effectively across various model sizes (4B and 8B) and RL algorithms (GRPO and DAPO).
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
Mar 12, 2025Large Language Models (LLMs) have been widely adopted in commercial code completion engines, significantly enhancing coding efficiency and productivity. However, LLMs may generate code with quality issues that violate coding standards and best practices, such as poor code style and maintainability, even when the code is functionally correct. This necessitates additional effort from developers to improve the code, potentially negating the efficiency gains provided by LLMs. To address this problem, we propose a novel comparative prefix-tuning method for controllable high-quality code generation. Our method introduces a single, property-specific prefix that is prepended to the activations of the LLM, serving as a lightweight alternative to fine-tuning. Unlike existing methods that require training multiple prefixes, our approach trains only one prefix and leverages pairs of high-quality and low-quality code samples, introducing a sequence-level ranking loss to guide the model's training. This comparative approach enables the model to better understand the differences between high-quality and low-quality code, focusing on aspects that impact code quality. Additionally, we design a data construction pipeline to collect and annotate pairs of high-quality and low-quality code, facilitating effective training. Extensive experiments on the Code Llama 7B model demonstrate that our method improves code quality by over 100% in certain task categories, while maintaining functional correctness. We also conduct ablation studies and generalization experiments, confirming the effectiveness of our method's components and its strong generalization capability.
Signage-Aware Exploration in Open World using Venue Maps
Oct 14, 2024



Current exploration methods struggle to search for shops in unknown open-world environments due to a lack of prior knowledge and text recognition capabilities. Venue maps offer valuable information that can aid exploration planning by correlating scene signage with map data. However, the arbitrary shapes and styles of the text on signage, along with multi-view inconsistencies, pose significant challenges for accurate recognition by robots. Additionally, the discrepancies between real-world environments and venue maps hinder the incorporation of text information into planners. This paper introduces a novel signage-aware exploration system to address these challenges, enabling the robot to utilize venue maps effectively. We propose a signage understanding method that accurately detects and recognizes the text on signage using a diffusion-based text instance retrieval method combined with a 2D-to-3D semantic fusion strategy. Furthermore, we design a venue map-guided exploration-exploitation planner that balances exploration in unknown regions using a directional heuristic derived from venue maps with exploitation to get close and adjust orientation for better recognition. Experiments in large-scale shopping malls demonstrate our method's superior signage recognition accuracy and coverage efficiency, outperforming state-of-the-art scene text spotting methods and traditional exploration methods.
Semisupervised Neural Proto-Language Reconstruction
Jun 09, 2024



Existing work implementing comparative reconstruction of ancestral languages (proto-languages) has usually required full supervision. However, historical reconstruction models are only of practical value if they can be trained with a limited amount of labeled data. We propose a semisupervised historical reconstruction task in which the model is trained on only a small amount of labeled data (cognate sets with proto-forms) and a large amount of unlabeled data (cognate sets without proto-forms). We propose a neural architecture for comparative reconstruction (DPD-BiReconstructor) incorporating an essential insight from linguists' comparative method: that reconstructed words should not only be reconstructable from their daughter words, but also deterministically transformable back into their daughter words. We show that this architecture is able to leverage unlabeled cognate sets to outperform strong semisupervised baselines on this novel task.
Improved Neural Protoform Reconstruction via Reflex Prediction
Mar 27, 2024



Protolanguage reconstruction is central to historical linguistics. The comparative method, one of the most influential theoretical and methodological frameworks in the history of the language sciences, allows linguists to infer protoforms (reconstructed ancestral words) from their reflexes (related modern words) based on the assumption of regular sound change. Not surprisingly, numerous computational linguists have attempted to operationalize comparative reconstruction through various computational models, the most successful of which have been supervised encoder-decoder models, which treat the problem of predicting protoforms given sets of reflexes as a sequence-to-sequence problem. We argue that this framework ignores one of the most important aspects of the comparative method: not only should protoforms be inferable from cognate sets (sets of related reflexes) but the reflexes should also be inferable from the protoforms. Leveraging another line of research -- reflex prediction -- we propose a system in which candidate protoforms from a reconstruction model are reranked by a reflex prediction model. We show that this more complete implementation of the comparative method allows us to surpass state-of-the-art protoform reconstruction methods on three of four Chinese and Romance datasets.
Disturbance Rejection Control for Autonomous Trolley Collection Robots with Prescribed Performance
Sep 22, 2023



Trajectory tracking control of autonomous trolley collection robots (ATCR) is an ambitious work due to the complex environment, serious noise and external disturbances. This work investigates a control scheme for ATCR subjecting to severe environmental interference. A kinematics model based adaptive sliding mode disturbance observer with fast convergence is first proposed to estimate the lumped disturbances. On this basis, a robust controller with prescribed performance is proposed using a backstepping technique, which improves the transient performance and guarantees fast convergence. Simulation outcomes have been provided to illustrate the effectiveness of the proposed control scheme.
Endpoint Detection for Streaming End-to-End Multi-talker ASR
Jan 24, 2022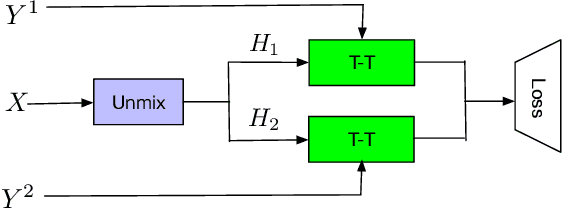
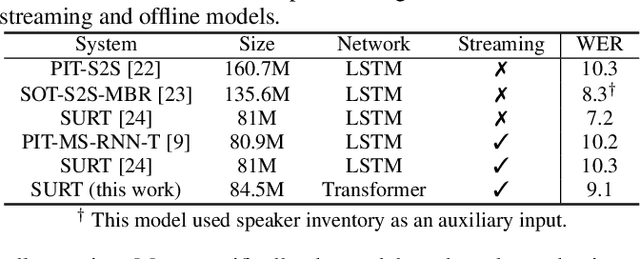
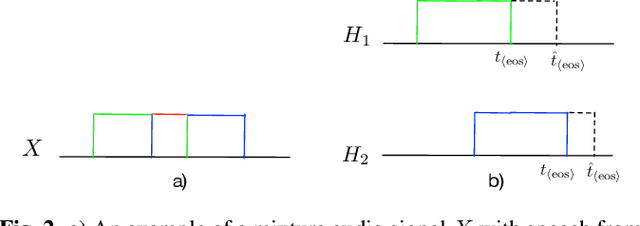
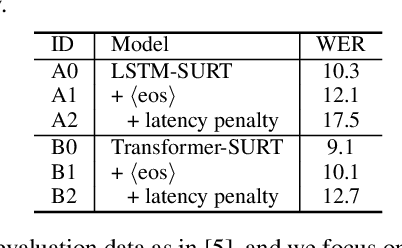
Streaming end-to-end multi-talker speech recognition aims at transcribing the overlapped speech from conversations or meetings with an all-neural model in a streaming fashion, which is fundamentally different from a modular-based approach that usually cascades the speech separation and the speech recognition models trained independently. Previously, we proposed the Streaming Unmixing and Recognition Transducer (SURT) model based on recurrent neural network transducer (RNN-T) for this problem and presented promising results. However, for real applications, the speech recognition system is also required to determine the timestamp when a speaker finishes speaking for prompt system response. This problem, known as endpoint (EP) detection, has not been studied previously for multi-talker end-to-end models. In this work, we address the EP detection problem in the SURT framework by introducing an end-of-sentence token as an output unit, following the practice of single-talker end-to-end models. Furthermore, we also present a latency penalty approach that can significantly cut down the EP detection latency. Our experimental results based on the 2-speaker LibrispeechMix dataset show that the SURT model can achieve promising EP detection without significantly degradation of the recognition accuracy.
Continuous Streaming Multi-Talker ASR with Dual-path Transducers
Sep 17, 2021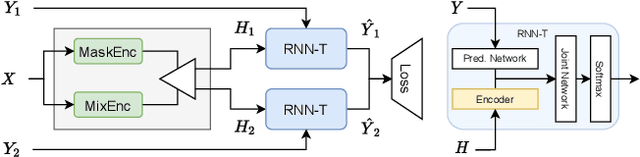

Streaming recognition of multi-talker conversations has so far been evaluated only for 2-speaker single-turn sessions. In this paper, we investigate it for multi-turn meetings containing multiple speakers using the Streaming Unmixing and Recognition Transducer (SURT) model, and show that naively extending the single-turn model to this harder setting incurs a performance penalty. As a solution, we propose the dual-path (DP) modeling strategy first used for time-domain speech separation. We experiment with LSTM and Transformer based DP models, and show that they improve word error rate (WER) performance while yielding faster convergence. We also explore training strategies such as chunk width randomization and curriculum learning for these models, and demonstrate their importance through ablation studies. Finally, we evaluate our models on the LibriCSS meeting data, where they perform competitively with offline separation-based methods.