 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Form Speech Recognition for General Speech In-Context Learning
Sep 29, 2024



We propose a novel approach to end-to-end automatic speech recognition (ASR) to achieve efficient speech in-context learning (SICL) for (i) long-form speech decoding, (ii) test-time speaker adaptation, and (iii) test-time contextual biasing. Specifically, we introduce an attention-based encoder-decoder (AED) model with SICL capability (referred to as SICL-AED), where the decoder utilizes an utterance-level cross-attention to integrate information from the encoder's output efficiently, and a document-level self-attention to learn contextual information. Evaluated on the benchmark TEDLIUM3 dataset, SICL-AED achieves an 8.64% relative word error rate (WER) reduction compared to a baseline utterance-level AED model by leveraging previously decoded outputs as in-context examples. It also demonstrates comparable performance to conventional long-form AED systems with significantly reduced runtime and memory complexity. Additionally, we introduce an in-context fine-tuning (ICFT) technique that further enhances SICL effectiveness during inference. Experiments on speaker adaptation and contextual biasing highlight the general speech in-context learning capabilities of our system, achieving effective results with provided contexts. Without specific fine-tuning, SICL-AED matches the performance of supervised AED baselines for speaker adaptation and improves entity recall by 64% for contextual biasing task.
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Sep 14, 2023



Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023



Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Acoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Oct 16, 2022
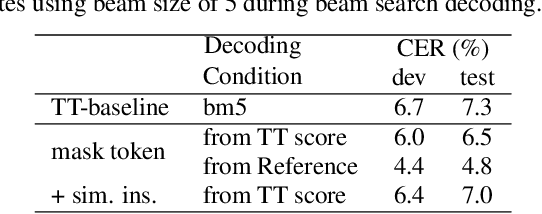

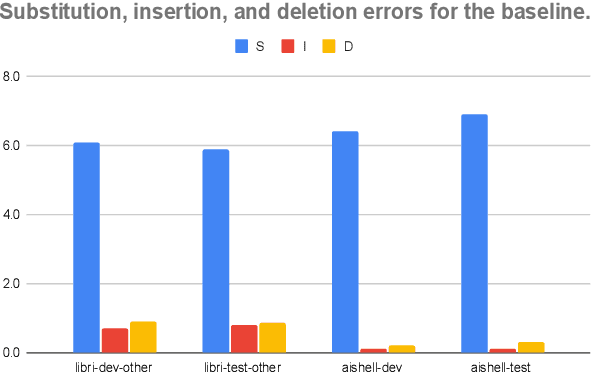
Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.
Have best of both worlds: two-pass hybrid and E2E cascading framework for speech recognition
Oct 10, 2021
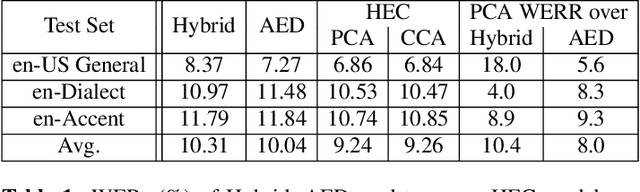
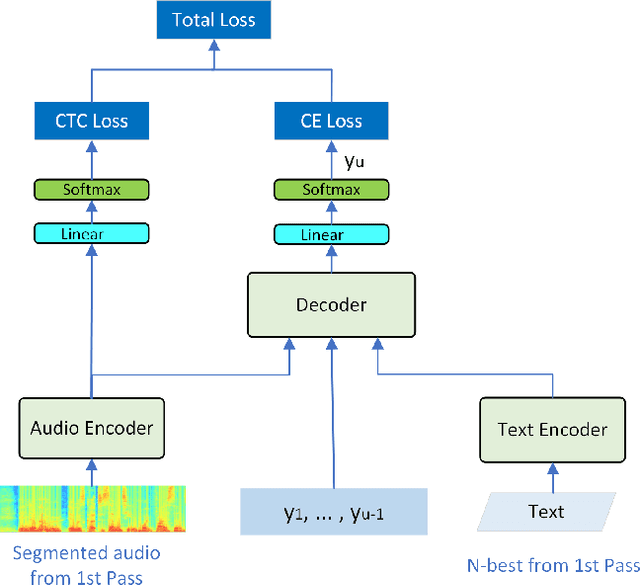
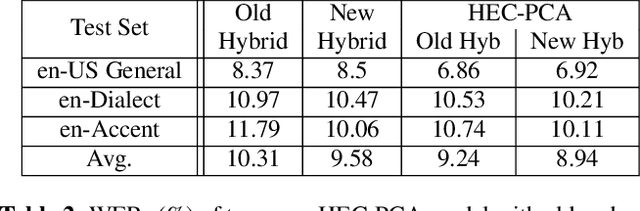
Hybrid and end-to-end (E2E) systems have their individual advantages, with different error patterns in the speech recognition results. By jointly modeling audio and text, the E2E model performs better in matched scenarios and scales well with a large amount of paired audio-text training data. The modularized hybrid model is easier for customization, and better to make use of a massive amount of unpaired text data. This paper proposes a two-pass hybrid and E2E cascading (HEC) framework to combine the hybrid and E2E model in order to take advantage of both sides, with hybrid in the first pass and E2E in the second pass. We show that the proposed system achieves 8-10% relative word error rate reduction with respect to each individual system. More importantly, compared with the pure E2E system, we show the proposed system has the potential to keep the advantages of hybrid system, e.g., customization and segmentation capabilities. We also show the second pass E2E model in HEC is robust with respect to the change in the first pass hybrid model.
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition
Jun 04, 2021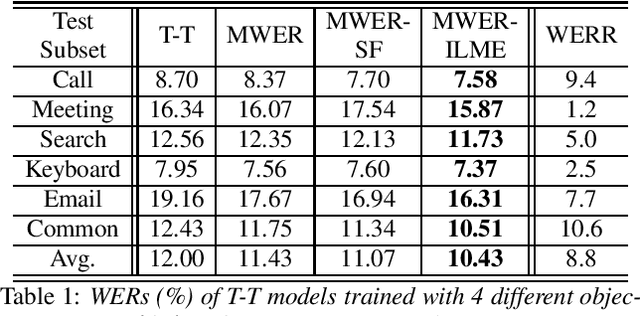
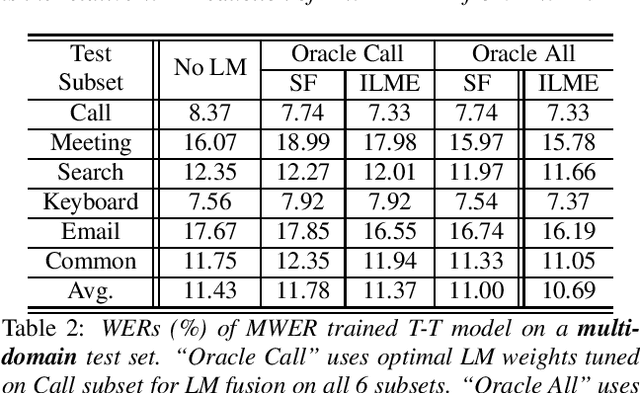
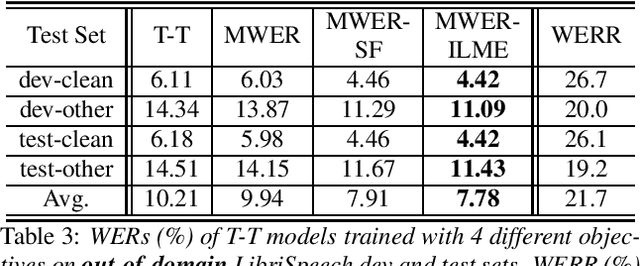
Integrating external language models (LMs) into end-to-end (E2E) models remains a challenging task for domain-adaptive speech recognition. Recently, internal language model estimation (ILME)-based LM fusion has shown significant word error rate (WER) reduction from Shallow Fusion by subtracting a weighted internal LM score from an interpolation of E2E model and external LM scores during beam search. However, on different test sets, the optimal LM interpolation weights vary over a wide range and have to be tuned extensively on well-matched validation sets. In this work, we perform LM fusion in the minimum WER (MWER) training of an E2E model to obviate the need for LM weights tuning during inference. Besides MWER training with Shallow Fusion (MWER-SF), we propose a novel MWER training with ILME (MWER-ILME) where the ILME-based fusion is conducted to generate N-best hypotheses and their posteriors. Additional gradient is induced when internal LM is engaged in MWER-ILME loss computation. During inference, LM weights pre-determined in MWER training enable robust LM integrations on test sets from different domains. Experimented with 30K-hour trained transformer transducers, MWER-ILME achieves on average 8.8% and 5.8% relative WER reductions from MWER and MWER-SF training, respectively, on 6 different test sets
* 5 pages, Interspeech 2021
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021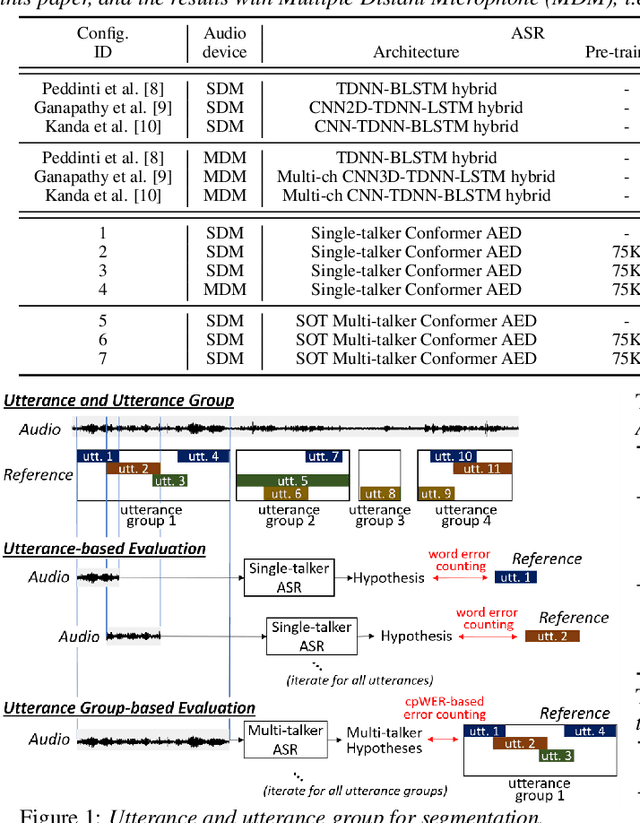


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
End-to-End Speaker-Attributed ASR with Transformer
Apr 05, 2021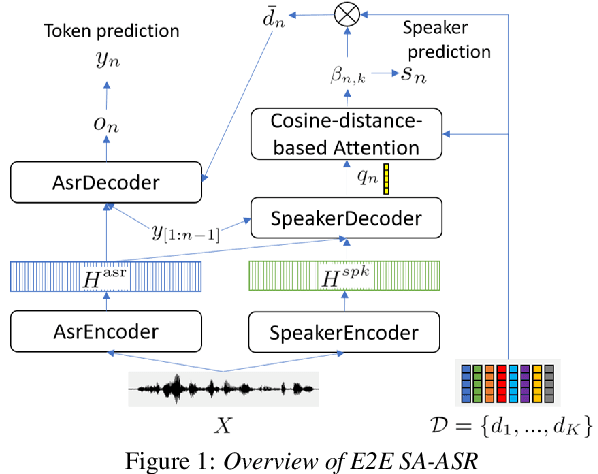
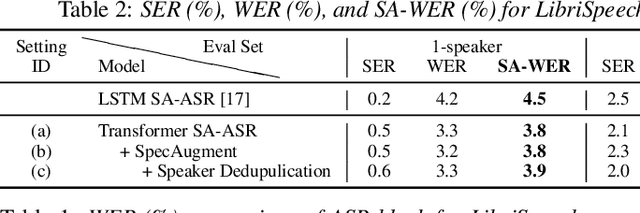
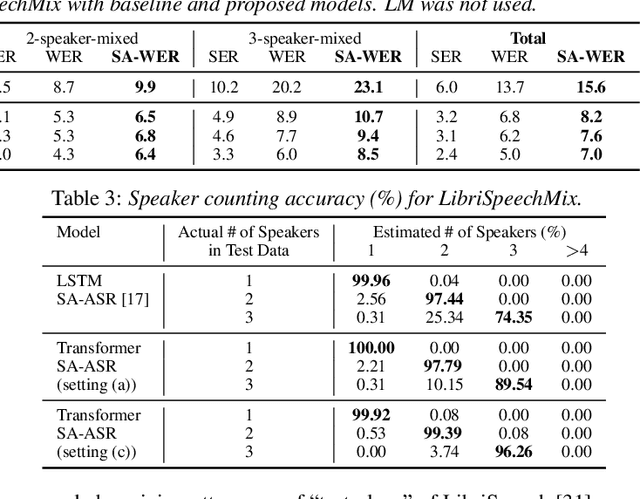
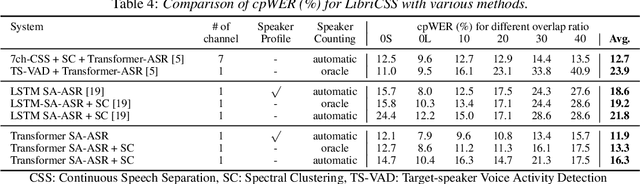
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.
Semantic Mask for Transformer based End-to-End Speech Recognition
Dec 06, 2019
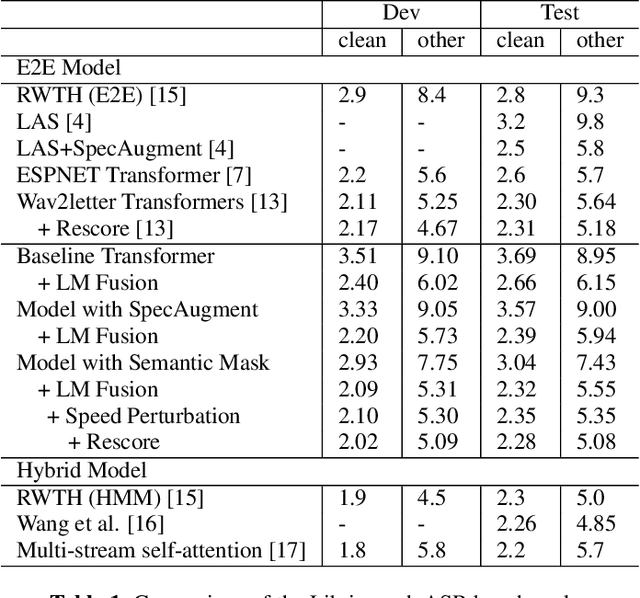
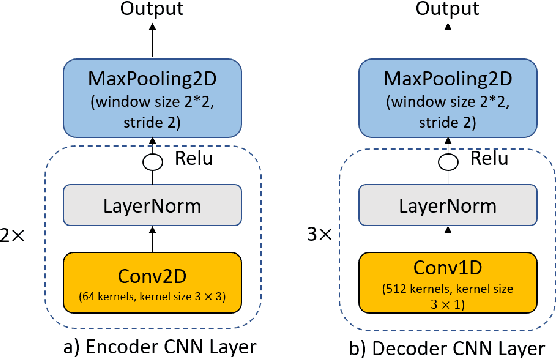
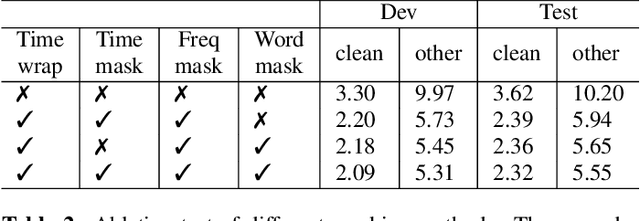
Attention-based encoder-decoder model has achieved impressive results for both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. This approach takes advantage of the memorization capacity of neural networks to learn the mapping from the input sequence to the output sequence from scratch, without the assumption of prior knowledge such as the alignments. However, this model is prone to overfitting, especially when the amount of training data is limited. Inspired by SpecAugment and BERT, in this paper, we propose a semantic mask based regularization for training such kind of end-to-end (E2E) model. The idea is to mask the input features corresponding to a particular output token, e.g., a word or a word-piece, in order to encourage the model to fill the token based on the contextual information. While this approach is applicable to the encoder-decoder framework with any type of neural network architecture, we study the transformer-based model for ASR in this work. We perform experiments on Librispeech 960h and TedLium2 data sets, and achieve the state-of-the-art performance on the test set in the scope of E2E models.
Advancing Acoustic-to-Word CTC Model with Attention and Mixed-Units
Dec 31, 2018
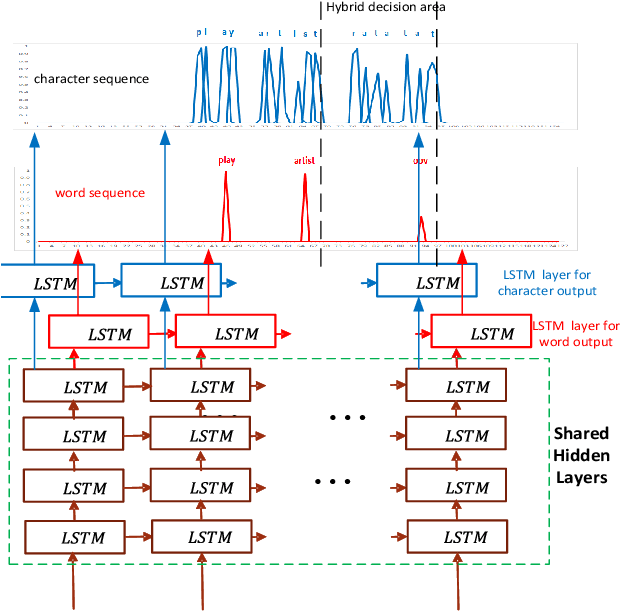
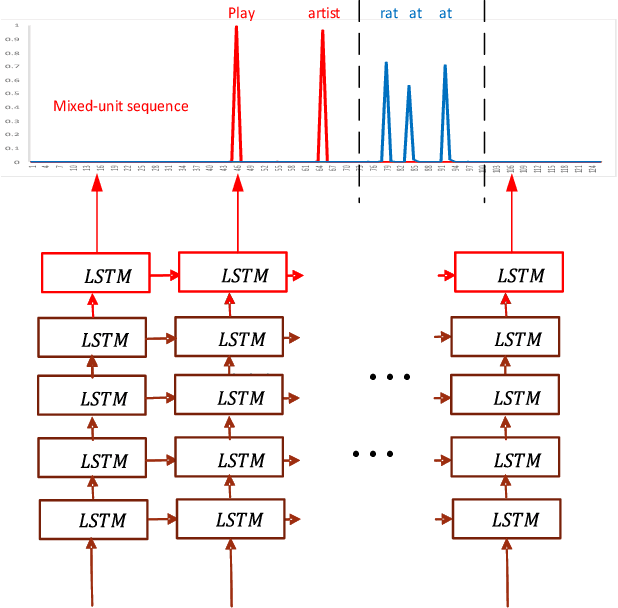

The acoustic-to-word model based on the Connectionist Temporal Classification (CTC) criterion is a natural end-to-end (E2E) system directly targeting word as output unit. Two issues exist in the system: first, the current output of the CTC model relies on the current input and does not account for context weighted inputs. This is the hard alignment issue. Second, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue. This means it can model only the frequently occurring words while tagging the remaining words as OOV. Hence, such a model is limited in its capacity in recognizing only a fixed set of frequent words. In this study, we propose addressing these problems using a combination of attention mechanism and mixed-units. In particular, we introduce Attention CTC, Self-Attention CTC, Hybrid CTC, and Mixed-unit CTC. First, we blend attention modeling capabilities directly into the CTC network using Attention CTC and Self-Attention CTC. Second, to alleviate the OOV issue, we present Hybrid CTC which uses a word and letter CTC with shared hidden layers. The Hybrid CTC consults the letter CTC when the word CTC emits an OOV. Then, we propose a much better solution by training a Mixed-unit CTC which decomposes all the OOV words into sequences of frequent words and multi-letter units. Evaluated on a 3400 hours Microsoft Cortana voice assistant task, our final acoustic-to-word solution using attention and mixed-units achieves a relative reduction in word error rate (WER) over the vanilla word CTC by 12.09%. Such an E2E model without using any language model (LM) or complex decoder also outperforms a traditional context-dependent (CD) phoneme CTC with strong LM and decoder by 6.79% relative.