 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to the Patient: Enhancing Medical Dialogue Generation with Patient Hallucination Detection and Mitigation
Oct 08, 2024



Medical dialogue systems aim to provide medical services through patient-agent conversations. Previous methods typically regard patients as ideal users, focusing mainly on common challenges in dialogue systems, while neglecting the potential biases or misconceptions that might be introduced by real patients, who are typically non-experts. This study investigates the discrepancy between patients' expressions during medical consultations and their actual health conditions, defined as patient hallucination. Such phenomena often arise from patients' lack of knowledge and comprehension, concerns, and anxieties, resulting in the transmission of inaccurate or wrong information during consultations. To address this issue, we propose MedPH, a Medical dialogue generation method for mitigating the problem of Patient Hallucinations designed to detect and cope with hallucinations. MedPH incorporates a detection method that utilizes one-dimensional structural entropy over a temporal dialogue entity graph, and a mitigation strategy based on hallucination-related information to guide patients in expressing their actual conditions. Experimental results indicate the high effectiveness of MedPH when compared to existing approaches in both medical entity prediction and response generation tasks, while also demonstrating its effectiveness in mitigating hallucinations within interactive scenarios.
Planning and Rendering: Towards End-to-End Product Poster Generation
Dec 14, 2023



End-to-end product poster generation significantly optimizes design efficiency and reduces production costs. Prevailing methods predominantly rely on image-inpainting methods to generate clean background images for given products. Subsequently, poster layout generation methods are employed to produce corresponding layout results. However, the background images may not be suitable for accommodating textual content due to their complexity, and the fixed location of products limits the diversity of layout results. To alleviate these issues, we propose a novel product poster generation framework named P\&R. The P\&R draws inspiration from the workflow of designers in creating posters, which consists of two stages: Planning and Rendering. At the planning stage, we propose a PlanNet to generate the layout of the product and other visual components considering both the appearance features of the product and semantic features of the text, which improves the diversity and rationality of the layouts. At the rendering stage, we propose a RenderNet to generate the background for the product while considering the generated layout, where a spatial fusion module is introduced to fuse the layout of different visual components. To foster the advancement of this field, we propose the first end-to-end product poster generation dataset PPG30k, comprising 30k exquisite product poster images along with comprehensive image and text annotations. Our method outperforms the state-of-the-art product poster generation methods on PPG30k. The PPG30k will be released soon.
Well Begun is Half Done: Generator-agnostic Knowledge Pre-Selection for Knowledge-Grounded Dialogue
Oct 20, 2023



Accurate knowledge selection is critical in knowledge-grounded dialogue systems. Towards a closer look at it, we offer a novel perspective to organize existing literature, i.e., knowledge selection coupled with, after, and before generation. We focus on the third under-explored category of study, which can not only select knowledge accurately in advance, but has the advantage to reduce the learning, adjustment, and interpretation burden of subsequent response generation models, especially LLMs. We propose GATE, a generator-agnostic knowledge selection method, to prepare knowledge for subsequent response generation models by selecting context-related knowledge among different knowledge structures and variable knowledge requirements. Experimental results demonstrate the superiority of GATE, and indicate that knowledge selection before generation is a lightweight yet effective way to facilitate LLMs (e.g., ChatGPT) to generate more informative responses.
Joint Open Knowledge Base Canonicalization and Linking
Dec 02, 2022Open Information Extraction (OIE) methods extract a large number of OIE triples (noun phrase, relation phrase, noun phrase) from text, which compose large Open Knowledge Bases (OKBs). However, noun phrases (NPs) and relation phrases (RPs) in OKBs are not canonicalized and often appear in different paraphrased textual variants, which leads to redundant and ambiguous facts. To address this problem, there are two related tasks: OKB canonicalization (i.e., convert NPs and RPs to canonicalized form) and OKB linking (i.e., link NPs and RPs with their corresponding entities and relations in a curated Knowledge Base (e.g., DBPedia). These two tasks are tightly coupled, and one task can benefit significantly from the other. However, they have been studied in isolation so far. In this paper, we explore the task of joint OKB canonicalization and linking for the first time, and propose a novel framework JOCL based on factor graph model to make them reinforce each other. JOCL is flexible enough to combine different signals from both tasks, and able to extend to fit any new signals. A thorough experimental study over two large scale OIE triple data sets shows that our framework outperforms all the baseline methods for the task of OKB canonicalization (OKB linking) in terms of average F1 (accuracy).
Interacting with Non-Cooperative User: A New Paradigm for Proactive Dialogue Policy
Apr 07, 2022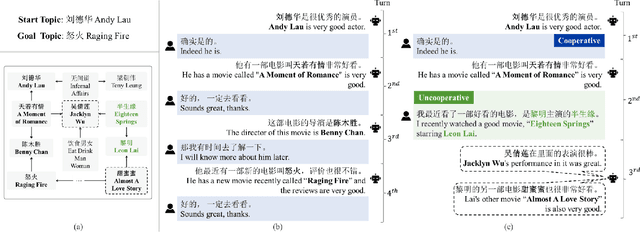
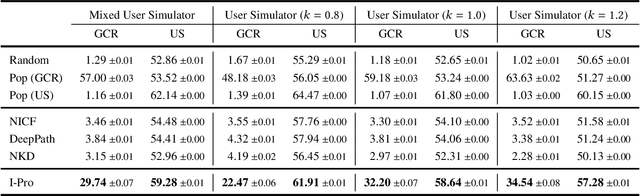

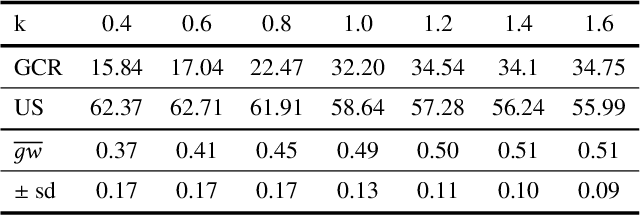
Proactive dialogue system is able to lead the conversation to a goal topic and has advantaged potential in bargain, persuasion and negotiation. Current corpus-based learning manner limits its practical application in real-world scenarios. To this end, we contribute to advance the study of the proactive dialogue policy to a more natural and challenging setting, i.e., interacting dynamically with users. Further, we call attention to the non-cooperative user behavior -- the user talks about off-path topics when he/she is not satisfied with the previous topics introduced by the agent. We argue that the targets of reaching the goal topic quickly and maintaining a high user satisfaction are not always converge, because the topics close to the goal and the topics user preferred may not be the same. Towards this issue, we propose a new solution named I-Pro that can learn Proactive policy in the Interactive setting. Specifically, we learn the trade-off via a learned goal weight, which consists of four factors (dialogue turn, goal completion difficulty, user satisfaction estimation, and cooperative degree). The experimental results demonstrate I-Pro significantly outperforms baselines in terms of effectiveness and interpretability.
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
Apr 06, 2022Procedural Multimodal Documents (PMDs) organize textual instructions and corresponding images step by step. Comprehending PMDs and inducing their representations for the downstream reasoning tasks is designated as Procedural MultiModal Machine Comprehension (M3C). In this study, we approach Procedural M3C at a fine-grained level (compared with existing explorations at a document or sentence level), that is, entity. With delicate consideration, we model entity both in its temporal and cross-modal relation and propose a novel Temporal-Modal Entity Graph (TMEG). Specifically, graph structure is formulated to capture textual and visual entities and trace their temporal-modal evolution. In addition, a graph aggregation module is introduced to conduct graph encoding and reasoning. Comprehensive experiments across three Procedural M3C tasks are conducted on a traditional dataset RecipeQA and our new dataset CraftQA, which can better evaluate the generalization of TMEG.
HyperPELT: Unified Parameter-Efficient Language Model Tuning for Both Language and Vision-and-Language Tasks
Mar 08, 2022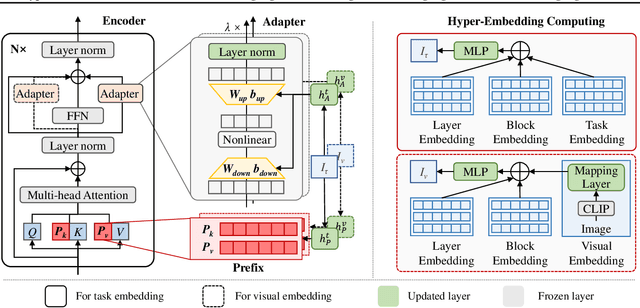
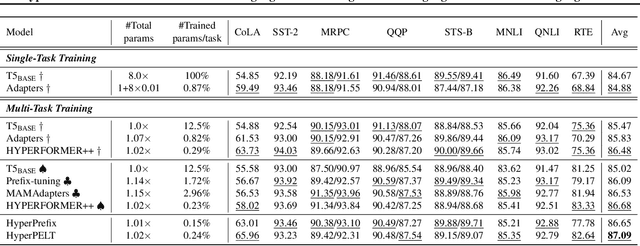
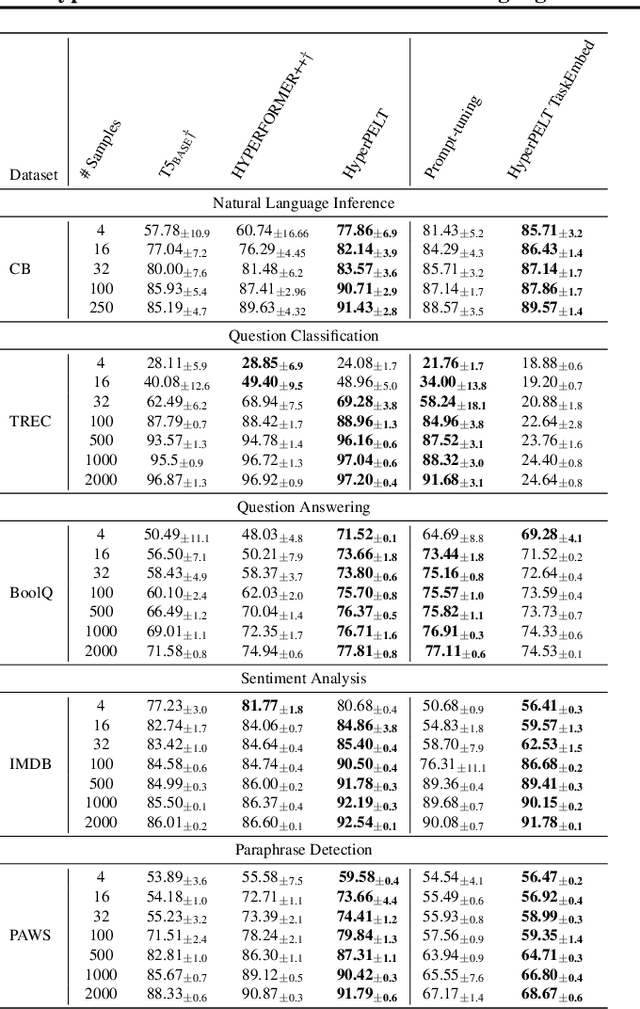
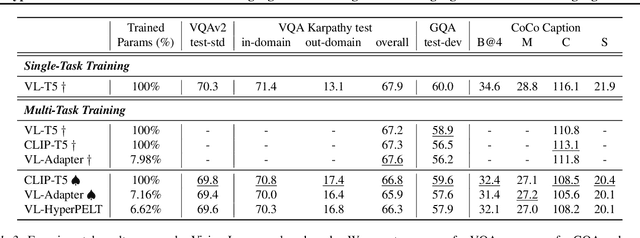
The workflow of pretraining and fine-tuning has emerged as a popular paradigm for solving various NLP and V&L (Vision-and-Language) downstream tasks. With the capacity of pretrained models growing rapidly, how to perform parameter-efficient fine-tuning has become fairly important for quick transfer learning and deployment. In this paper, we design a novel unified parameter-efficient transfer learning framework that works effectively on both pure language and V&L tasks. In particular, we use a shared hypernetwork that takes trainable hyper-embeddings as input, and outputs weights for fine-tuning different small modules in a pretrained language model, such as tuning the parameters inserted into multi-head attention blocks (i.e., prefix-tuning) and feed-forward blocks (i.e., adapter-tuning). We define a set of embeddings (e.g., layer, block, task and visual embeddings) as the key components to calculate hyper-embeddings, which thus can support both pure language and V&L tasks. Our proposed framework adds fewer trainable parameters in multi-task learning while achieving superior performances and transfer ability compared to state-of-the-art methods. Empirical results on the GLUE benchmark and multiple V&L tasks confirm the effectiveness of our framework on both textual and visual modalities.
Self-Supervised Learning for speech recognition with Intermediate layer supervision
Dec 16, 2021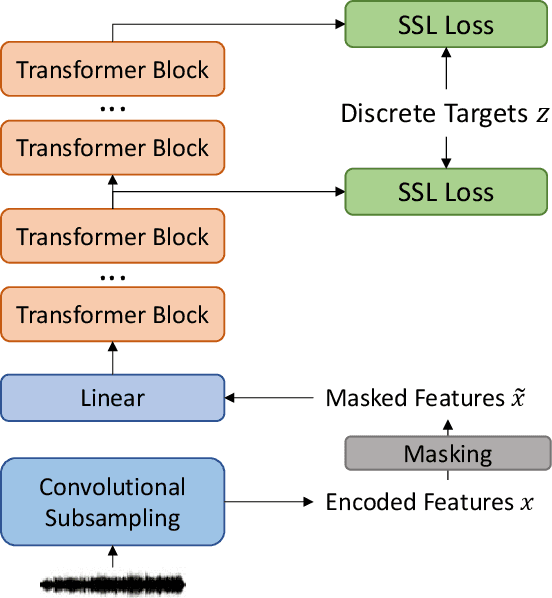
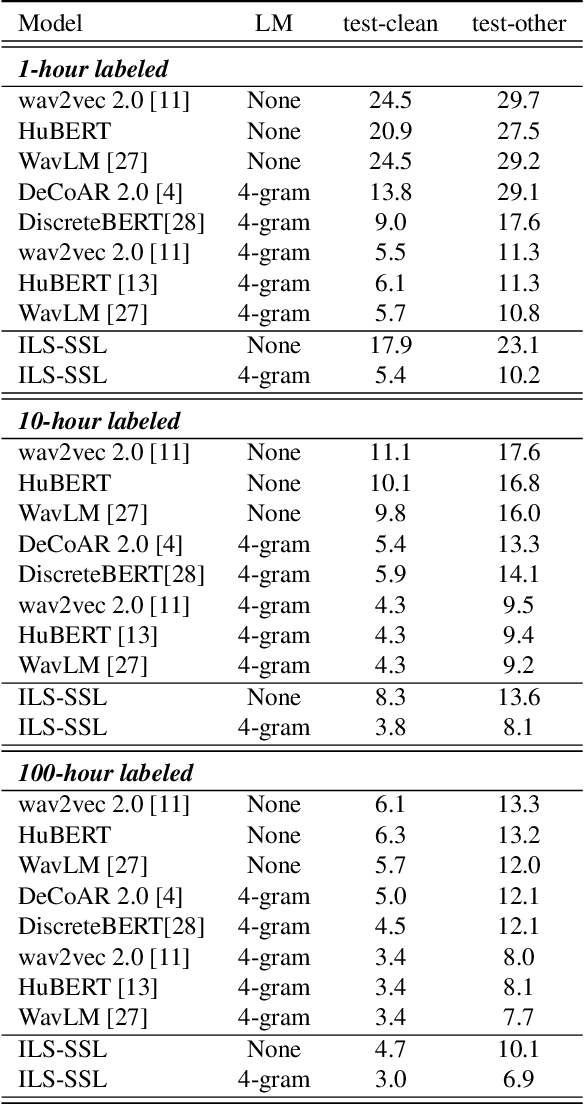
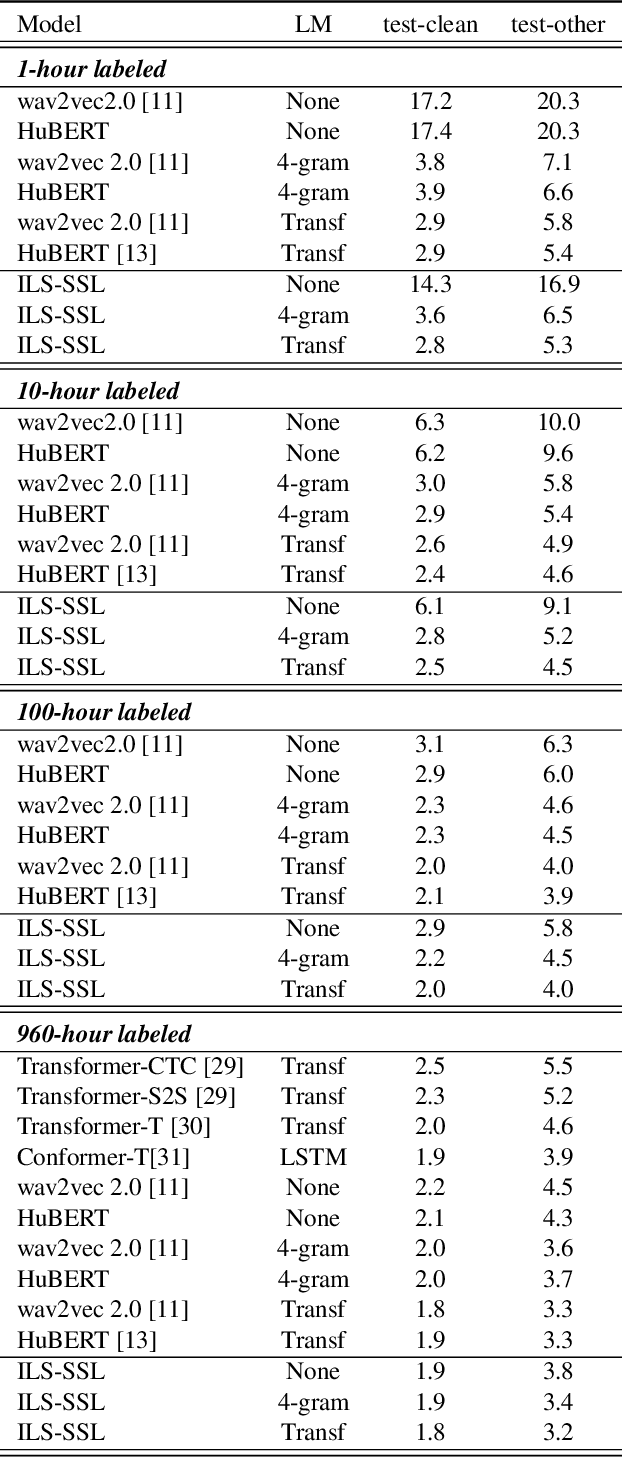
Recently, pioneer work finds that speech pre-trained models can solve full-stack speech processing tasks, because the model utilizes bottom layers to learn speaker-related information and top layers to encode content-related information. Since the network capacity is limited, we believe the speech recognition performance could be further improved if the model is dedicated to audio content information learning. To this end, we propose Intermediate Layer Supervision for Self-Supervised Learning (ILS-SSL), which forces the model to concentrate on content information as much as possible by adding an additional SSL loss on the intermediate layers. Experiments on LibriSpeech test-other set show that our method outperforms HuBERT significantly, which achieves a 23.5%/11.6% relative word error rate reduction in the w/o language model setting for base/large models. Detailed analysis shows the bottom layers of our model have a better correlation with phonetic units, which is consistent with our intuition and explains the success of our method for ASR.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
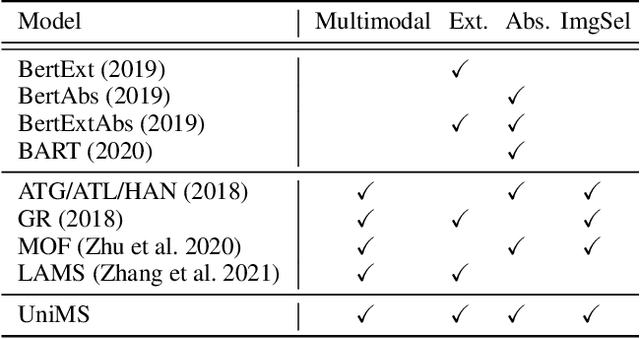
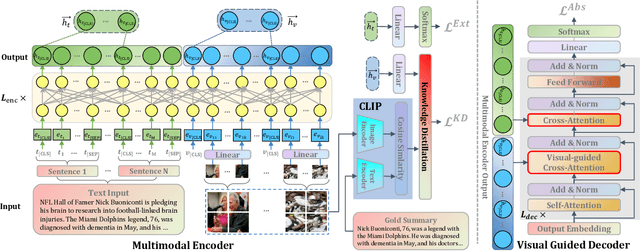
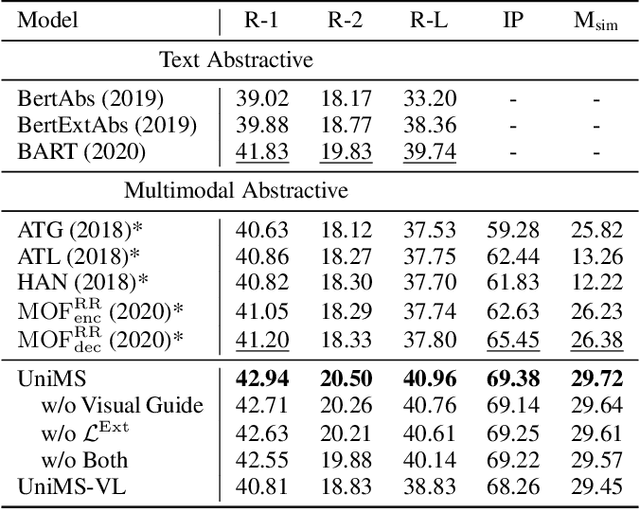
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.
Fact-Tree Reasoning for N-ary Question Answering over Knowledge Graphs
Aug 17, 2021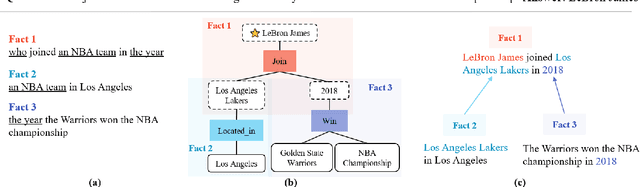
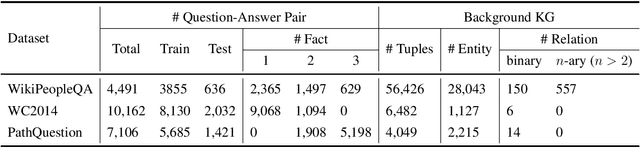
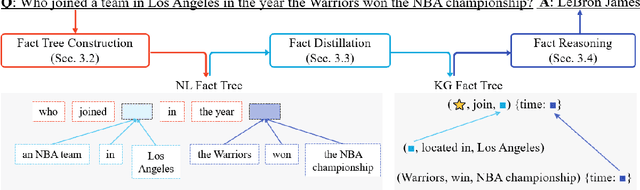
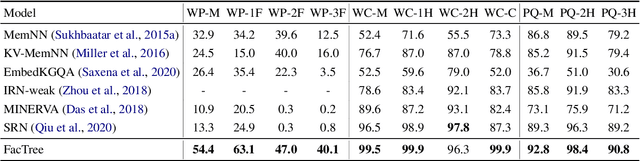
In the question answering(QA) task, multi-hop reasoning framework has been extensively studied in recent years to perform more efficient and interpretable answer reasoning on the Knowledge Graph(KG). However, multi-hop reasoning is inapplicable for answering n-ary fact questions due to its linear reasoning nature. We discover that there are two feasible improvements: 1) upgrade the basic reasoning unit from entity or relation to fact; and 2) upgrade the reasoning structure from chain to tree. Based on these, we propose a novel fact-tree reasoning framework, through transforming the question into a fact tree and performing iterative fact reasoning on it to predict the correct answer. Through a comprehensive evaluation on the n-ary fact KGQA dataset introduced by this work, we demonstrate that the proposed fact-tree reasoning framework has the desired advantage of high answer prediction accuracy. In addition, we also evaluate the fact-tree reasoning framework on two binary KGQA datasets and show that our approach also has a strong reasoning ability compared with several excellent baselines. This work has direct implications for exploring complex reasoning scenarios and provides a preliminary baseline approach.