 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Deepsets for Off-policy Evaluation under Spatial or Spatio-temporal Interferences
Jul 25, 2024



Off-policy evaluation (OPE) is widely applied in sectors such as pharmaceuticals and e-commerce to evaluate the efficacy of novel products or policies from offline datasets. This paper introduces a causal deepset framework that relaxes several key structural assumptions, primarily the mean-field assumption, prevalent in existing OPE methodologies that handle spatio-temporal interference. These traditional assumptions frequently prove inadequate in real-world settings, thereby restricting the capability of current OPE methods to effectively address complex interference effects. In response, we advocate for the implementation of the permutation invariance (PI) assumption. This innovative approach enables the data-driven, adaptive learning of the mean-field function, offering a more flexible estimation method beyond conventional averaging. Furthermore, we present novel algorithms that incorporate the PI assumption into OPE and thoroughly examine their theoretical foundations. Our numerical analyses demonstrate that this novel approach yields significantly more precise estimations than existing baseline algorithms, thereby substantially improving the practical applicability and effectiveness of OPE methodologies. A Python implementation of our proposed method is available at https://github.com/BIG-S2/Causal-Deepsets.
Sim2Rec: A Simulator-based Decision-making Approach to Optimize Real-World Long-term User Engagement in Sequential Recommender Systems
May 03, 2023Long-term user engagement (LTE) optimization in sequential recommender systems (SRS) is shown to be suited by reinforcement learning (RL) which finds a policy to maximize long-term rewards. Meanwhile, RL has its shortcomings, particularly requiring a large number of online samples for exploration, which is risky in real-world applications. One of the appealing ways to avoid the risk is to build a simulator and learn the optimal recommendation policy in the simulator. In LTE optimization, the simulator is to simulate multiple users' daily feedback for given recommendations. However, building a user simulator with no reality-gap, i.e., can predict user's feedback exactly, is unrealistic because the users' reaction patterns are complex and historical logs for each user are limited, which might mislead the simulator-based recommendation policy. In this paper, we present a practical simulator-based recommender policy training approach, Simulation-to-Recommendation (Sim2Rec) to handle the reality-gap problem for LTE optimization. Specifically, Sim2Rec introduces a simulator set to generate various possibilities of user behavior patterns, then trains an environment-parameter extractor to recognize users' behavior patterns in the simulators. Finally, a context-aware policy is trained to make the optimal decisions on all of the variants of the users based on the inferred environment-parameters. The policy is transferable to unseen environments (e.g., the real world) directly as it has learned to recognize all various user behavior patterns and to make the correct decisions based on the inferred environment-parameters. Experiments are conducted in synthetic environments and a real-world large-scale ride-hailing platform, DidiChuxing. The results show that Sim2Rec achieves significant performance improvement, and produces robust recommendations in unseen environments.
A Unified Representation Framework for Rideshare Marketplace Equilibrium and Efficiency
Feb 28, 2023



Ridesharing platforms are a type of two-sided marketplace where ``supply-demand balance'' is critical for market efficiency and yet is complex to define and analyze. We present a unified analytical framework based on the graph-based equilibrium metric (GEM) for quantifying the supply-demand spatiotemporal state and efficiency of a ridesharing marketplace. GEM was developed as a generalized Wasserstein distance between the supply and demand distributions in a ridesharing market and has been used as an evaluation metric for algorithms expected to improve supply-demand alignment. Building upon GEM, we develop SD-GEM, a dual-perspective (supply- and demand-side) representation of rideshare market equilibrium. We show that there are often disparities between the two views and examine how this dual-view leads to the notion of market efficiency, in which we propose novel statistical tests for capturing improvement and explaining the underlying driving factors.
Spatio-temporal Incentives Optimization for Ride-hailing Services with Offline Deep Reinforcement Learning
Nov 06, 2022A fundamental question in any peer-to-peer ride-sharing system is how to, both effectively and efficiently, meet the request of passengers to balance the supply and demand in real time. On the passenger side, traditional approaches focus on pricing strategies by increasing the probability of users' call to adjust the distribution of demand. However, previous methods do not take into account the impact of changes in strategy on future supply and demand changes, which means drivers are repositioned to different destinations due to passengers' calls, which will affect the driver's income for a period of time in the future. Motivated by this observation, we make an attempt to optimize the distribution of demand to handle this problem by learning the long-term spatio-temporal values as a guideline for pricing strategy. In this study, we propose an offline deep reinforcement learning based method focusing on the demand side to improve the utilization of transportation resources and customer satisfaction. We adopt a spatio-temporal learning method to learn the value of different time and location, then incentivize the ride requests of passengers to adjust the distribution of demand to balance the supply and demand in the system. In particular, we model the problem as a Markov Decision Process (MDP).
Reinforcement Learning in the Wild: Scalable RL Dispatching Algorithm Deployed in Ridehailing Marketplace
Feb 10, 2022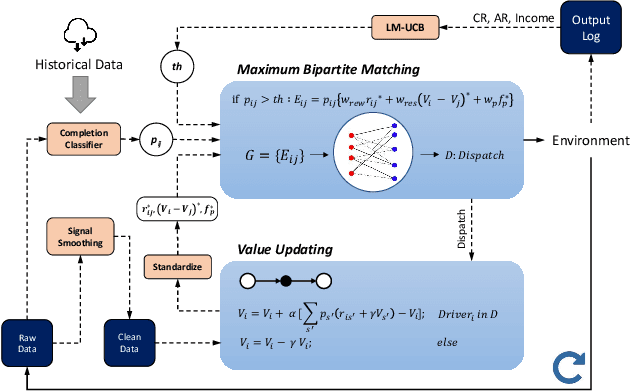
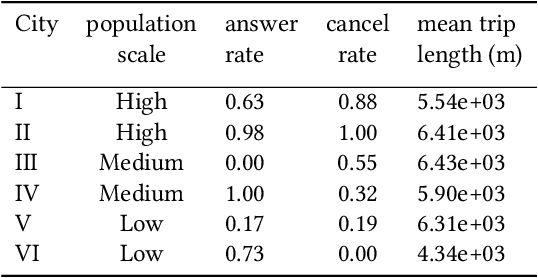
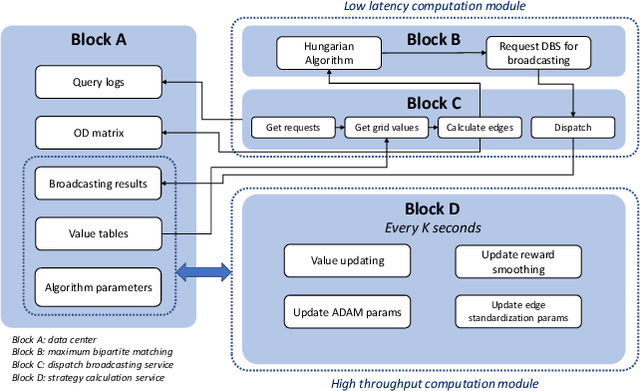
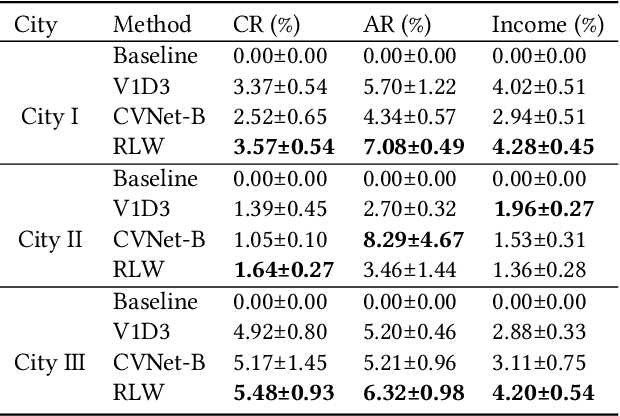
In this study, a real-time dispatching algorithm based on reinforcement learning is proposed and for the first time, is deployed in large scale. Current dispatching methods in ridehailing platforms are dominantly based on myopic or rule-based non-myopic approaches. Reinforcement learning enables dispatching policies that are informed of historical data and able to employ the learned information to optimize returns of expected future trajectories. Previous studies in this field yielded promising results, yet have left room for further improvements in terms of performance gain, self-dependency, transferability, and scalable deployment mechanisms. The present study proposes a standalone RL-based dispatching solution that is equipped with multiple mechanisms to ensure robust and efficient on-policy learning and inference while being adaptable for full-scale deployment. A new form of value updating based on temporal difference is proposed that is more adapted to the inherent uncertainty of the problem. For the driver-order assignment, a customized utility function is proposed that when tuned based on the statistics of the market, results in remarkable performance improvement and interpretability. In addition, for reducing the risk of cancellation after drivers' assignment, an adaptive graph pruning strategy based on the multi-arm bandit problem is introduced. The method is evaluated using offline simulation with real data and yields notable performance improvement. In addition, the algorithm is deployed online in multiple cities under DiDi's operation for A/B testing and is launched in one of the major international markets as the primary mode of dispatch. The deployed algorithm shows over 1.3% improvement in total driver income from A/B testing. In addition, by causal inference analysis, as much as 5.3% improvement in major performance metrics is detected after full-scale deployment.
A Deep Value-network Based Approach for Multi-Driver Order Dispatching
Jun 08, 2021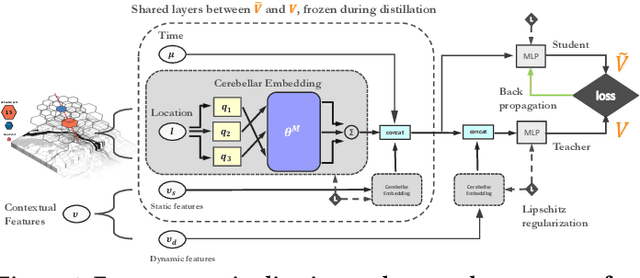
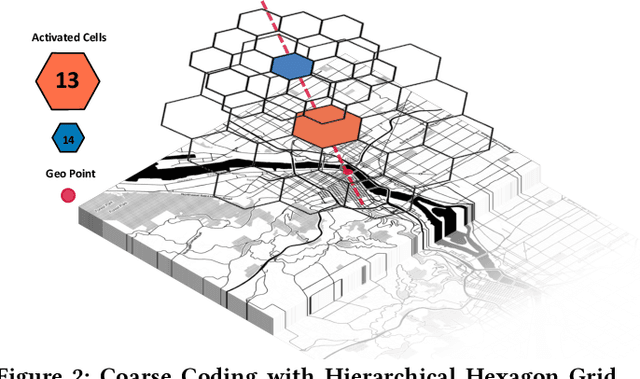
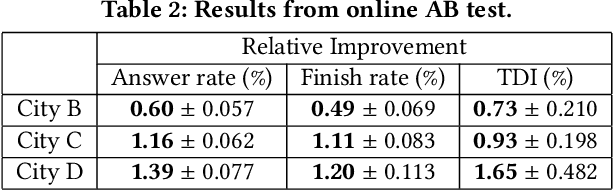
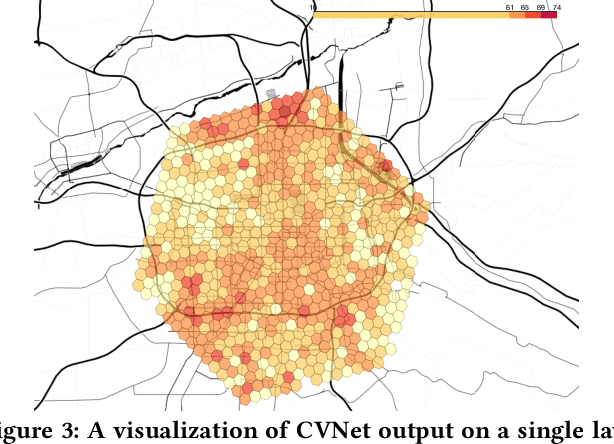
Recent works on ride-sharing order dispatching have highlighted the importance of taking into account both the spatial and temporal dynamics in the dispatching process for improving the transportation system efficiency. At the same time, deep reinforcement learning has advanced to the point where it achieves superhuman performance in a number of fields. In this work, we propose a deep reinforcement learning based solution for order dispatching and we conduct large scale online A/B tests on DiDi's ride-dispatching platform to show that the proposed method achieves significant improvement on both total driver income and user experience related metrics. In particular, we model the ride dispatching problem as a Semi Markov Decision Process to account for the temporal aspect of the dispatching actions. To improve the stability of the value iteration with nonlinear function approximators like neural networks, we propose Cerebellar Value Networks (CVNet) with a novel distributed state representation layer. We further derive a regularized policy evaluation scheme for CVNet that penalizes large Lipschitz constant of the value network for additional robustness against adversarial perturbation and noises. Finally, we adapt various transfer learning methods to CVNet for increased learning adaptability and efficiency across multiple cities. We conduct extensive offline simulations based on real dispatching data as well as online AB tests through the DiDi's platform. Results show that CVNet consistently outperforms other recently proposed dispatching methods. We finally show that the performance can be further improved through the efficient use of transfer learning.
Value Function is All You Need: A Unified Learning Framework for Ride Hailing Platforms
Jun 04, 2021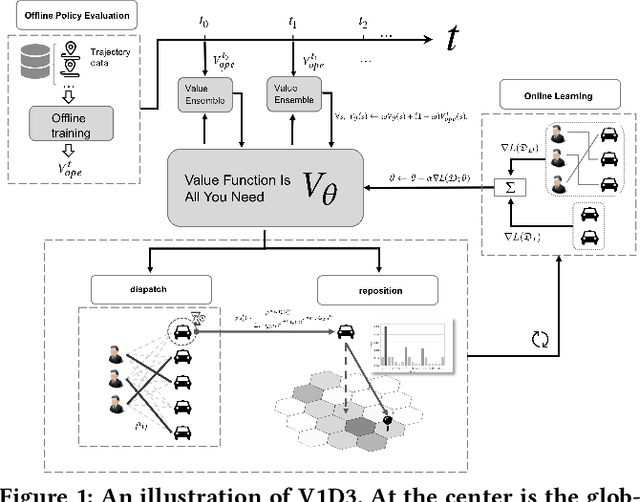
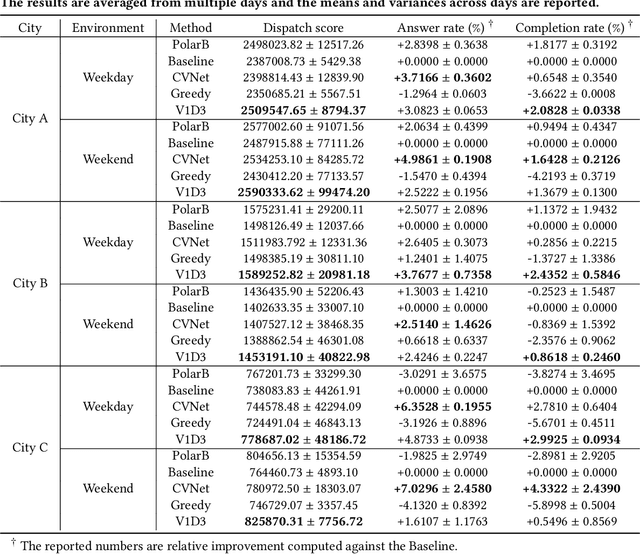
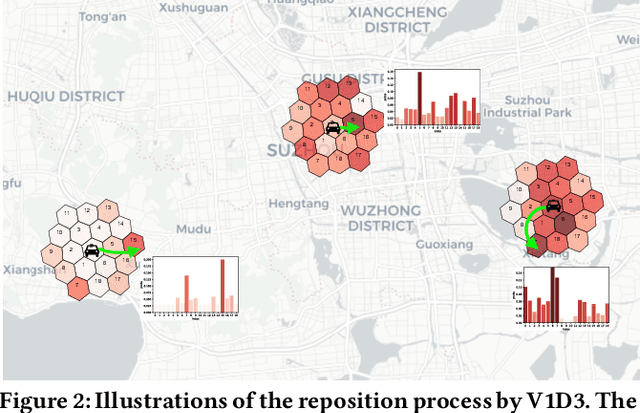
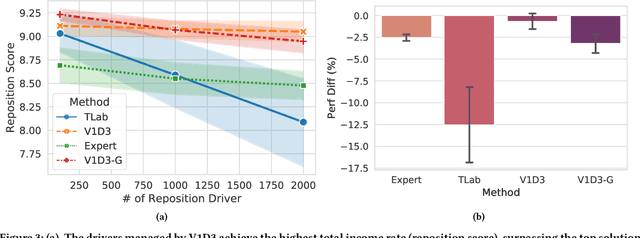
Large ride-hailing platforms, such as DiDi, Uber and Lyft, connect tens of thousands of vehicles in a city to millions of ride demands throughout the day, providing great promises for improving transportation efficiency through the tasks of order dispatching and vehicle repositioning. Existing studies, however, usually consider the two tasks in simplified settings that hardly address the complex interactions between the two, the real-time fluctuations between supply and demand, and the necessary coordinations due to the large-scale nature of the problem. In this paper we propose a unified value-based dynamic learning framework (V1D3) for tackling both tasks. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. To improve the sample-efficiency and the robustness, we further propose a novel periodic ensemble method combining the fast online learning with a large-scale offline training scheme that leverages the abundant historical driver trajectory data. This allows the proposed framework to adapt quickly to the highly dynamic environment, to generalize robustly to recurrent patterns and to drive implicit coordinations among the population of managed vehicles. Extensive experiments based on real-world datasets show considerably improvements over other recently proposed methods on both tasks. Particularly, V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics.
Reinforcement Learning for Ridesharing: A Survey
May 03, 2021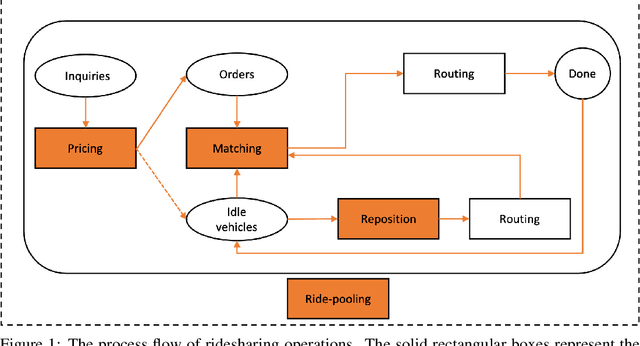
In this paper, we present a comprehensive, in-depth survey of the literature on reinforcement learning approaches to ridesharing problems. Papers on the topics of rideshare matching, vehicle repositioning, ride-pooling, and dynamic pricing are covered. Popular data sets and open simulation environments are also introduced. Subsequently, we discuss a number of challenges and opportunities for reinforcement learning research on this important domain.
Real-world Ride-hailing Vehicle Repositioning using Deep Reinforcement Learning
Mar 08, 2021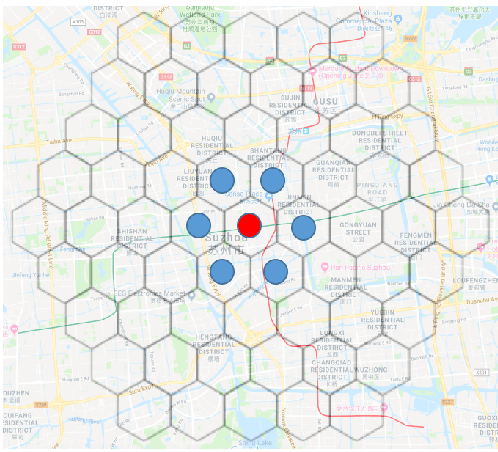
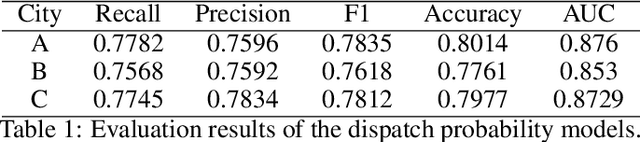
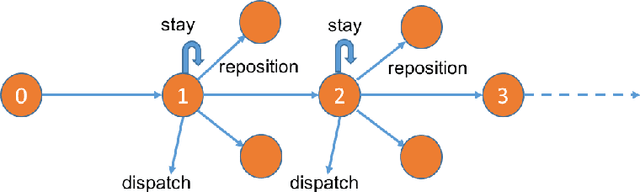

We present a new practical framework based on deep reinforcement learning and decision-time planning for real-world vehicle repositioning on ride-hailing (a type of mobility-on-demand, MoD) platforms. Our approach learns the spatiotemporal state-value function using a batch training algorithm with deep value networks. The optimal repositioning action is generated on-demand through value-based policy search, which combines planning and bootstrapping with the value networks. For the large-fleet problems, we develop several algorithmic features that we incorporate into our framework and that we demonstrate to induce coordination among the algorithmically-guided vehicles. We benchmark our algorithm with baselines in a ride-hailing simulation environment to demonstrate its superiority in improving income efficiency meausred by income-per-hour. We have also designed and run a real-world experiment program with regular drivers on a major ride-hailing platform. We have observed significantly positive results on key metrics comparing our method with experienced drivers who performed idle-time repositioning based on their own expertise.
Value-based Bayesian Meta-reinforcement Learning and Traffic Signal Control
Oct 01, 2020

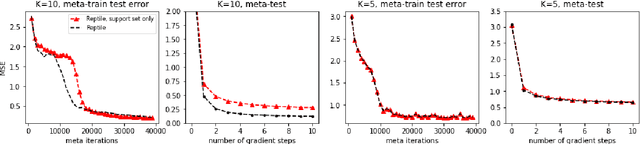
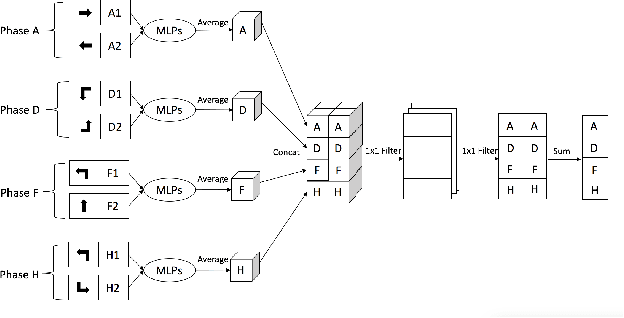
Reinforcement learning methods for traffic signal control has gained increasing interests recently and achieved better performances compared with traditional transportation methods. However, reinforcement learning based methods usually requires heavy training data and computational resources which largely limit its application in real-world traffic signal control. This makes meta-learning, which enables data-efficient and fast-adaptation training by leveraging the knowledge of previous learning experiences, catches attentions in traffic signal control. In this paper, we propose a novel value-based Bayesian meta-reinforcement learning framework BM-DQN to robustly speed up the learning process in new scenarios by utilizing well-trained prior knowledge learned from existing scenarios. This framework based on our proposed fast-adaptation variation to Gradient-EM Bayesian Meta-learning and the fast update advantage of DQN, which allows fast adaptation to new scenarios with continual learning ability and robustness to uncertainty. The experiments on 2D navigation and traffic signal control show that our proposed framework adapts more quickly and robustly in new scenarios than previous methods, and specifically, much better continual learning ability in heterogeneous scenarios.