 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement
Jun 04, 2026Existing code-generation benchmarks score a single mapping from a complete prompt to a one-shot output. However, real web development is different. Users seldom write a full spec at the start; many requirements only become clear once they look at an intermediate result and react to it. We present Asuka-Bench, a benchmark that pairs underspecified user intent with multi-round refinement, grounded in browser-rendered behavior. Each task is resolved through a closed loop: a Code Agent generates a web project, a UI Agent executes test cases on the deployed site, and a User LLM turns evaluation outcomes into natural-language feedback for the next round. The benchmark comprises 50 web tasks with 784 evaluation criteria and 2402 expected outcomes. We benchmark 8 LLMs across 2 agent frameworks. The results separate models clearly: weighted Task Pass Rate varies by 38 percentage points and models also differ substantially in their ability to repair from feedback. Asuka-Bench is also far from saturated: even the strongest model completes only 52% of projects after three rounds.
SAGE: A Quantitative Evaluation of Socialized Evolution in Agent Ecosystems
Jun 02, 2026Self-improving language agents are typically evaluated in isolation: an agent attempts a task, receives feedback, and iteratively refines its own behavior. Yet agents increasingly operate alongside peers whose strategies and outcomes are publicly visible. This raises an under-studied question: when does shared experience produce improvements that self-improvement alone cannot achieve? We introduce SAGE (Social Agent Group Evolution),an evaluation framework that compares two compute-matched conditions: SocialEvo, where agents from five distinct model families co-evolve with access to all peers' histories; and SelfEvo, where each agent receives the same number of task attempts but sees only its own past, which is conventional in self-improving agent studies. We instantiate SAGE in three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play, evaluated across multiple evolutionary rounds. We find that group history is not a universal amplifier: the strongest agent does not exceed its self-evolution ceiling. However, agents that plateau under self-improvement can achieve significant breakthroughs when peer experience is available. In competitive settings, counterfactual controls reveal that agents improve generally rather than developing opponent-specific strategies. Across different forms of shared history, filtered peer traces and reflective summaries often outperform raw logs, indicating that social gains depend on abstraction rather than exposure volume. These findings reveal that peer-history gains are agent-specific, arena-dependent, and contingent on the capacity to abstract transferable knowledge from public traces.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025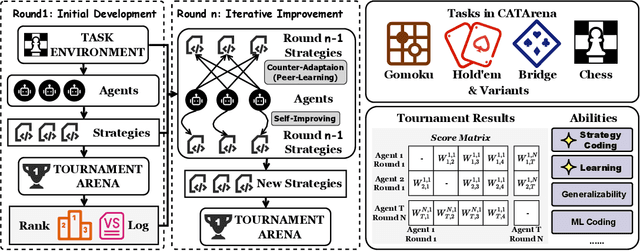
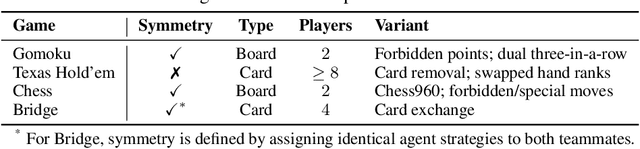
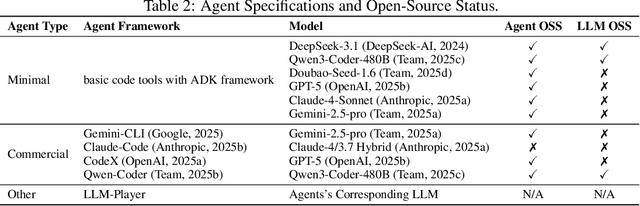
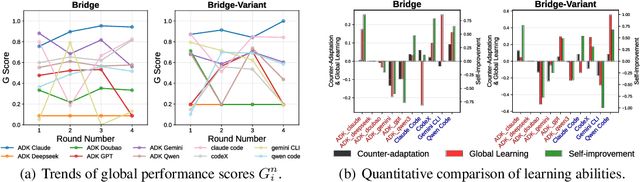
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
OIBench: Benchmarking Strong Reasoning Models with Olympiad in Informatics
Jun 12, 2025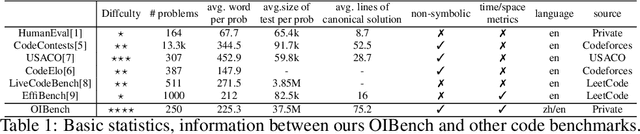

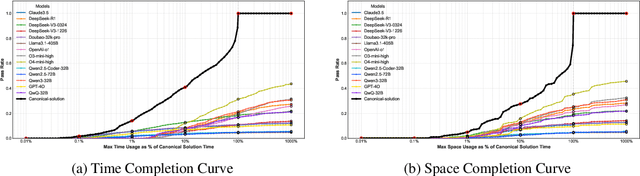
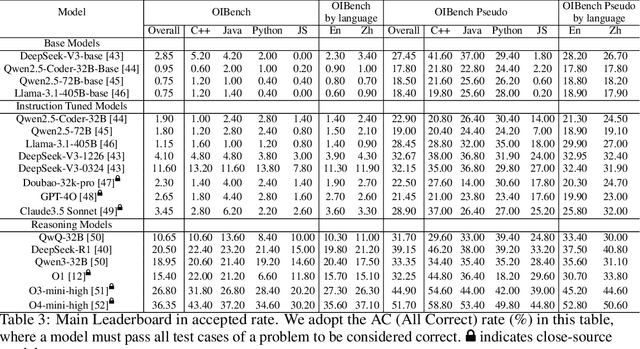
As models become increasingly sophisticated, conventional algorithm benchmarks are increasingly saturated, underscoring the need for more challenging benchmarks to guide future improvements in algorithmic reasoning. This paper introduces OIBench, a high-quality, private, and challenging olympiad-level informatics dataset comprising 250 carefully curated original problems. We detail the construction methodology of the benchmark, ensuring a comprehensive assessment across various programming paradigms and complexities, and we demonstrate its contamination-resistant properties via experiments. We propose Time/Space Completion Curves for finer-grained efficiency analysis and enable direct human-model comparisons through high-level participant evaluations. Our experiments reveal that while open-source models lag behind closed-source counterparts, current SOTA models already outperform most human participants in both correctness and efficiency, while still being suboptimal compared to the canonical solutions. By releasing OIBench as a fully open-source resource (https://huggingface.co/datasets/AGI-Eval/OIBench), we hope this benchmark will contribute to advancing code reasoning capabilities for future LLMs.
Beyond Triplet: Leveraging the Most Data for Multimodal Machine Translation
Dec 20, 2022



Multimodal machine translation (MMT) aims to improve translation quality by incorporating information from other modalities, such as vision. Previous MMT systems mainly focus on better access and use of visual information and tend to validate their methods on image-related datasets. These studies face two challenges. First, they can only utilize triple data (bilingual texts with images), which is scarce; second, current benchmarks are relatively restricted and do not correspond to realistic scenarios. Therefore, this paper correspondingly establishes new methods and new datasets for MMT. First, we propose a framework 2/3-Triplet with two new approaches to enhance MMT by utilizing large-scale non-triple data: monolingual image-text data and parallel text-only data. Second, we construct an English-Chinese {e}-commercial {m}ulti{m}odal {t}ranslation dataset (including training and testing), named EMMT, where its test set is carefully selected as some words are ambiguous and shall be translated mistakenly without the help of images. Experiments show that our method is more suitable for real-world scenarios and can significantly improve translation performance by using more non-triple data. In addition, our model also rivals various SOTA models in conventional multimodal translation benchmarks.
Unified Multimodal Punctuation Restoration Framework for Mixed-Modality Corpus
Jan 24, 2022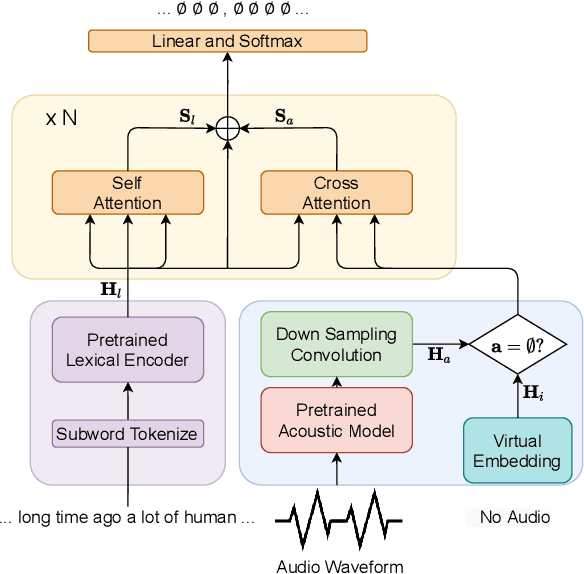
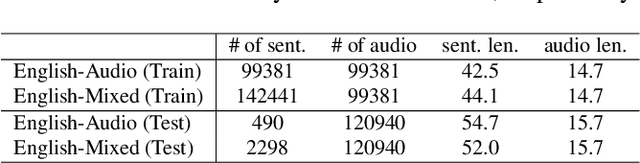
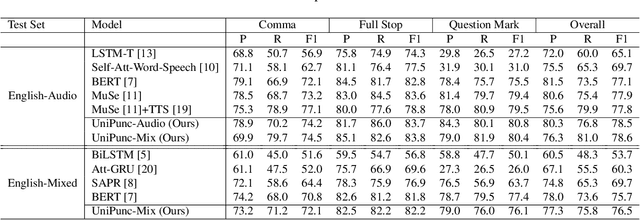
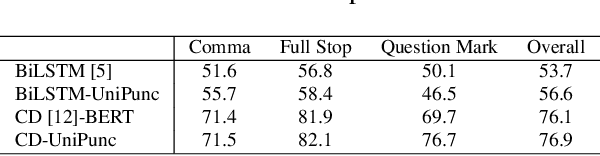
The punctuation restoration task aims to correctly punctuate the output transcriptions of automatic speech recognition systems. Previous punctuation models, either using text only or demanding the corresponding audio, tend to be constrained by real scenes, where unpunctuated sentences are a mixture of those with and without audio. This paper proposes a unified multimodal punctuation restoration framework, named UniPunc, to punctuate the mixed sentences with a single model. UniPunc jointly represents audio and non-audio samples in a shared latent space, based on which the model learns a hybrid representation and punctuates both kinds of samples. We validate the effectiveness of the UniPunc on real-world datasets, which outperforms various strong baselines (e.g. BERT, MuSe) by at least 0.8 overall F1 scores, making a new state-of-the-art. Extensive experiments show that UniPunc's design is a pervasive solution: by grafting onto previous models, UniPunc enables them to punctuate on the mixed corpus. Our code is available at github.com/Yaoming95/UniPunc
The Volctrans GLAT System: Non-autoregressive Translation Meets WMT21
Sep 24, 2021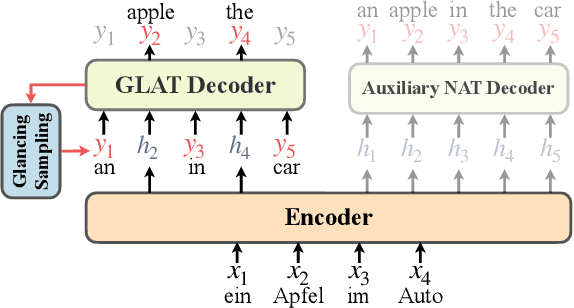
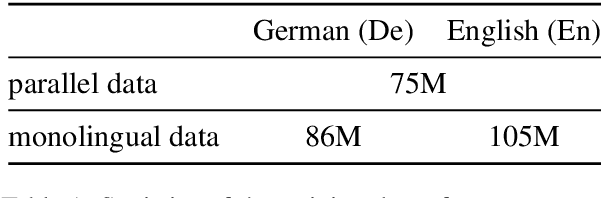
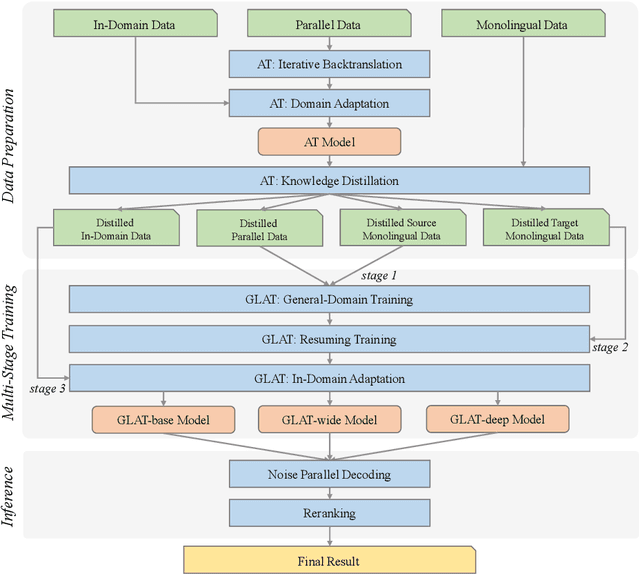
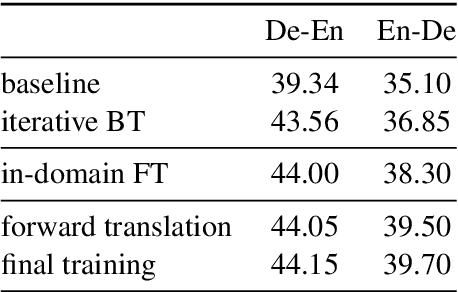
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models. To the best of our knowledge, this is the first parallel translation system that can be scaled to such a practical scenario like WMT competition. More importantly, our parallel translation system achieves the best BLEU score (35.0) on German->English translation task, outperforming all strong autoregressive counterparts.
UniST: Unified End-to-end Model for Streaming and Non-streaming Speech Translation
Sep 15, 2021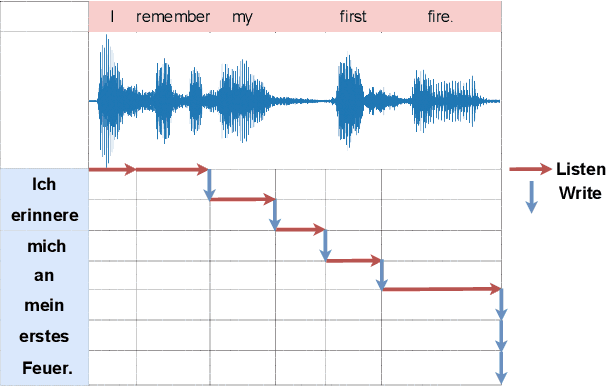

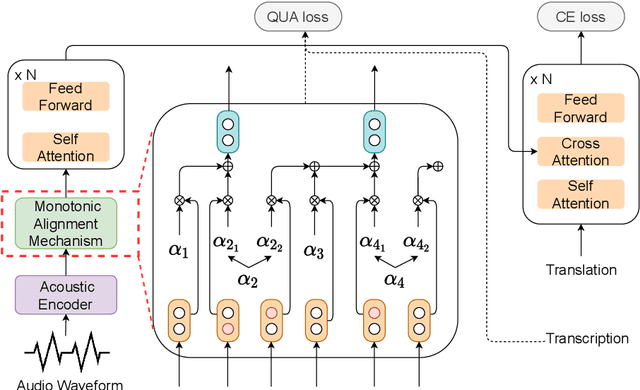

This paper presents a unified end-to-end frame-work for both streaming and non-streamingspeech translation. While the training recipes for non-streaming speech translation have been mature, the recipes for streaming speechtranslation are yet to be built. In this work, wefocus on developing a unified model (UniST) which supports streaming and non-streaming ST from the perspective of fundamental components, including training objective, attention mechanism and decoding policy. Experiments on the most popular speech-to-text translation benchmark dataset, MuST-C, show that UniST achieves significant improvement for non-streaming ST, and a better-learned trade-off for BLEU score and latency metrics for streaming ST, compared with end-to-end baselines and the cascaded models. We will make our codes and evaluation tools publicly available.