 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me How to Ask Again: Question Data Augmentation with Controllable Rewriting in Continuous Space
Oct 04, 2020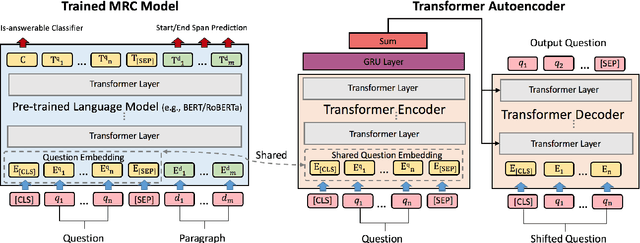
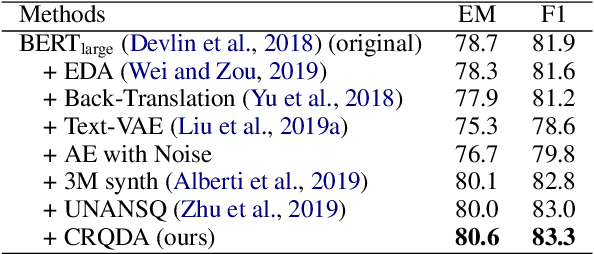
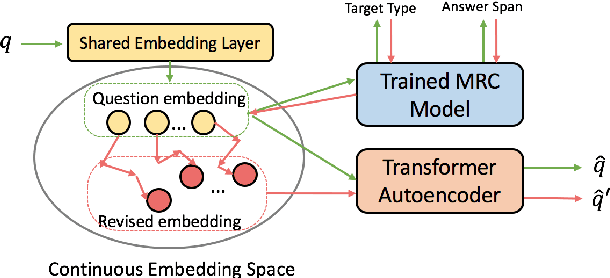
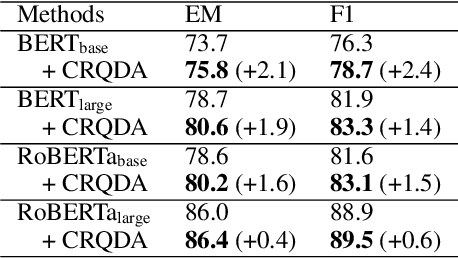
In this paper, we propose a novel data augmentation method, referred to as Controllable Rewriting based Question Data Augmentation (CRQDA), for machine reading comprehension (MRC), question generation, and question-answering natural language inference tasks. We treat the question data augmentation task as a constrained question rewriting problem to generate context-relevant, high-quality, and diverse question data samples. CRQDA utilizes a Transformer autoencoder to map the original discrete question into a continuous embedding space. It then uses a pre-trained MRC model to revise the question representation iteratively with gradient-based optimization. Finally, the revised question representations are mapped back into the discrete space, which serve as additional question data. Comprehensive experiments on SQuAD 2.0, SQuAD 1.1 question generation, and QNLI tasks demonstrate the effectiveness of CRQDA
GraphCodeBERT: Pre-training Code Representations with Data Flow
Sep 29, 2020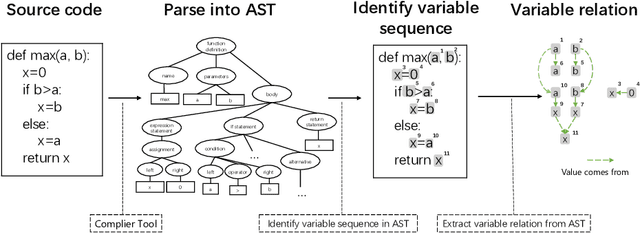
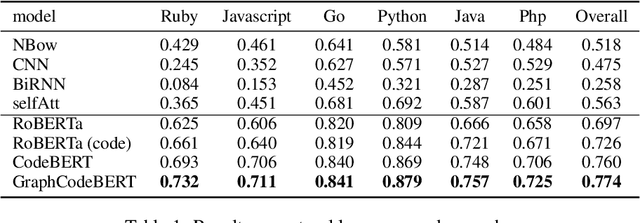
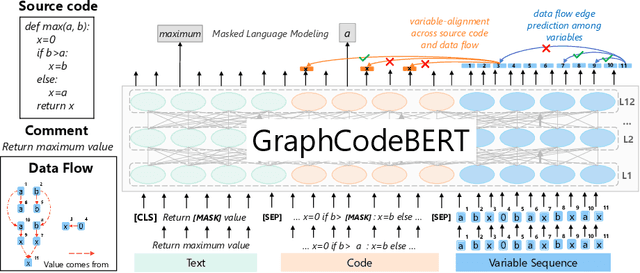
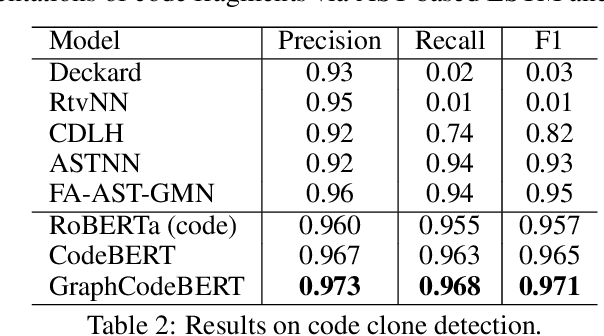
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequence of tokens, while ignoring the inherent structure of code, which provides crucial code semantics and would enhance the code understanding process. We present GraphCodeBERT, a pre-trained model for programming language that considers the inherent structure of code. Instead of taking syntactic-level structure of code like abstract syntax tree (AST), we use data flow in the pre-training stage, which is a semantic-level structure of code that encodes the relation of "where-the-value-comes-from" between variables. Such a semantic-level structure is neat and does not bring an unnecessarily deep hierarchy of AST, the property of which makes the model more efficient. We develop GraphCodeBERT based on Transformer. In addition to using the task of masked language modeling, we introduce two structure-aware pre-training tasks. One is to predict code structure edges, and the other is to align representations between source code and code structure. We implement the model in an efficient way with a graph-guided masked attention function to incorporate the code structure. We evaluate our model on four tasks, including code search, clone detection, code translation, and code refinement. Results show that code structure and newly introduced pre-training tasks can improve GraphCodeBERT and achieves state-of-the-art performance on the four downstream tasks. We further show that the model prefers structure-level attentions over token-level attentions in the task of code search.
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
Sep 27, 2020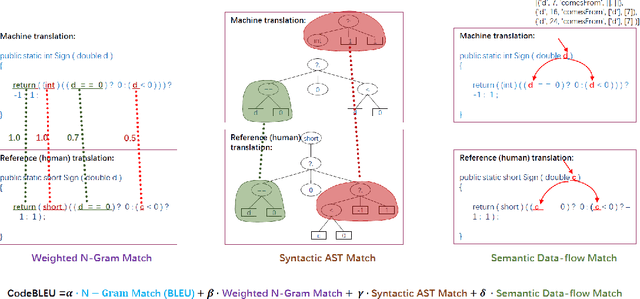


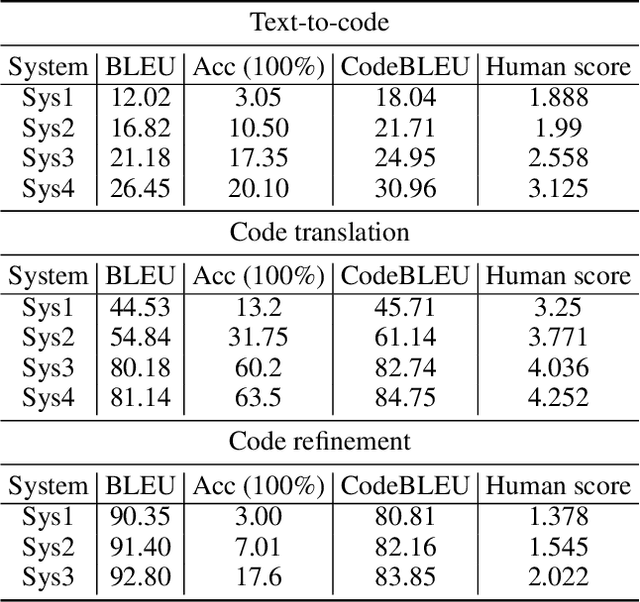
Evaluation metrics play a vital role in the growth of an area as it defines the standard of distinguishing between good and bad models. In the area of code synthesis, the commonly used evaluation metric is BLEU or perfect accuracy, but they are not suitable enough to evaluate codes, because BLEU is originally designed to evaluate the natural language, neglecting important syntactic and semantic features of codes, and perfect accuracy is too strict thus it underestimates different outputs with the same semantic logic. To remedy this, we introduce a new automatic evaluation metric, dubbed CodeBLEU. It absorbs the strength of BLEU in the n-gram match and further injects code syntax via abstract syntax trees (AST) and code semantics via data-flow. We conduct experiments by evaluating the correlation coefficient between CodeBLEU and quality scores assigned by the programmers on three code synthesis tasks, i.e., text-to-code, code translation, and code refinement. Experimental results show that our proposed CodeBLEU can achieve a better correlation with programmer assigned scores compared with BLEU and accuracy.
Continuous Speech Separation with Conformer
Aug 13, 2020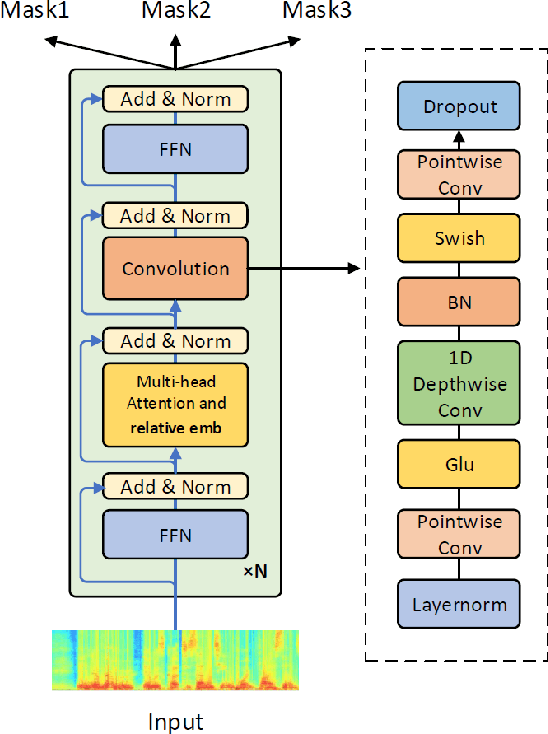
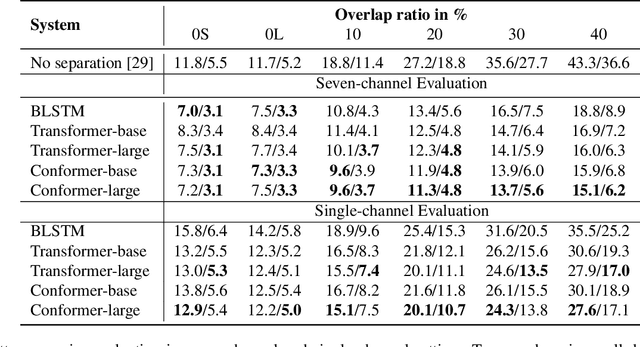
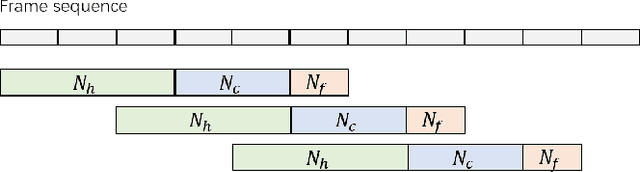
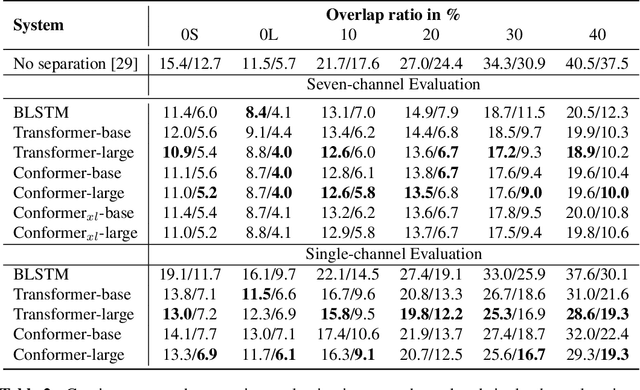
Continuous speech separation plays a vital role in complicated speech related tasks such as conversation transcription. The separation model extracts a single speaker signal from a mixed speech. In this paper, we use transformer and conformer in lieu of recurrent neural networks in the separation system, as we believe capturing global information with the self-attention based method is crucial for the speech separation. Evaluating on the LibriCSS dataset, the conformer separation model achieves state of the art results, with a relative 23.5% word error rate (WER) reduction from bi-directional LSTM (BLSTM) in the utterance-wise evaluation and a 15.4% WER reduction in the continuous evaluation.
InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training
Jul 15, 2020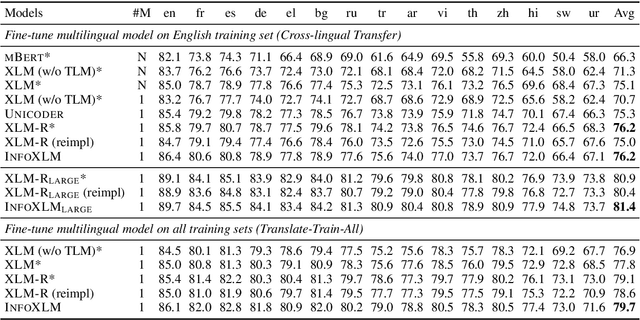
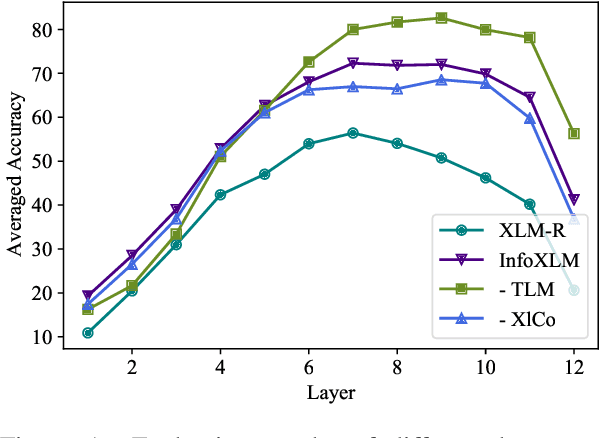
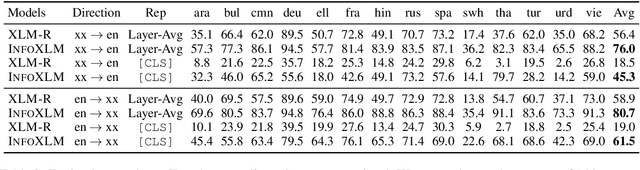
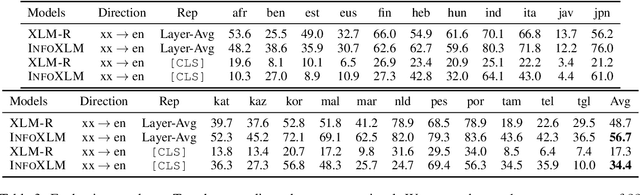
In this work, we formulate cross-lingual language model pre-training as maximizing mutual information between multilingual-multi-granularity texts. The unified view helps us to better understand the existing methods for learning cross-lingual representations. More importantly, the information-theoretic framework inspires us to propose a pre-training task based on contrastive learning. Given a bilingual sentence pair, we regard them as two views of the same meaning, and encourage their encoded representations to be more similar than the negative examples. By leveraging both monolingual and parallel corpora, we jointly train the pretext tasks to improve the cross-lingual transferability of pre-trained models. Experimental results on several benchmarks show that our approach achieves considerably better performance. The code and pre-trained models are available at http://aka.ms/infoxlm.
Evidence-Aware Inferential Text Generation with Vector Quantised Variational AutoEncoder
Jun 15, 2020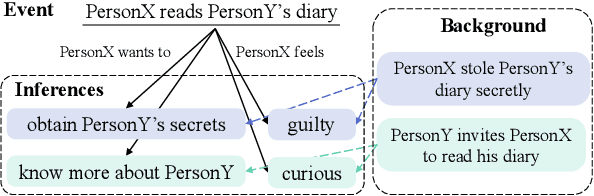
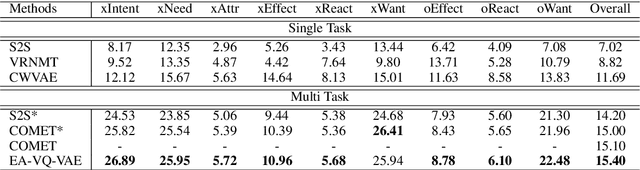
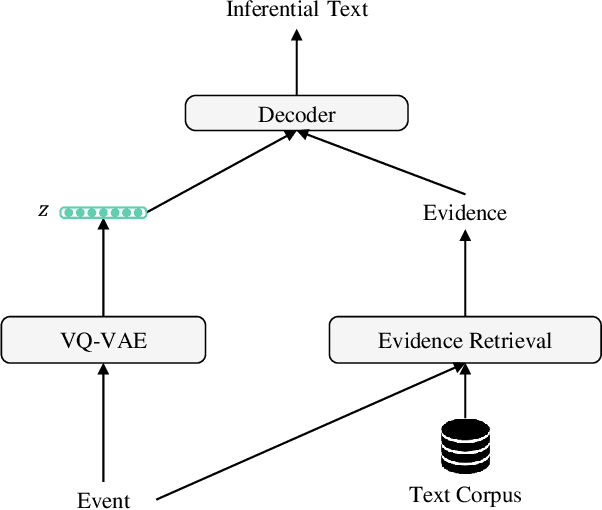
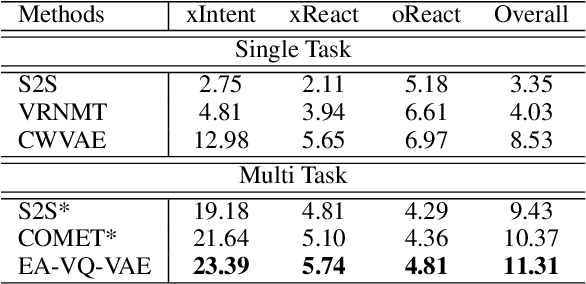
Generating inferential texts about an event in different perspectives requires reasoning over different contexts that the event occurs. Existing works usually ignore the context that is not explicitly provided, resulting in a context-independent semantic representation that struggles to support the generation. To address this, we propose an approach that automatically finds evidence for an event from a large text corpus, and leverages the evidence to guide the generation of inferential texts. Our approach works in an encoder-decoder manner and is equipped with a Vector Quantised-Variational Autoencoder, where the encoder outputs representations from a distribution over discrete variables. Such discrete representations enable automatically selecting relevant evidence, which not only facilitates evidence-aware generation, but also provides a natural way to uncover rationales behind the generation. Our approach provides state-of-the-art performance on both Event2Mind and ATOMIC datasets. More importantly, we find that with discrete representations, our model selectively uses evidence to generate different inferential texts.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020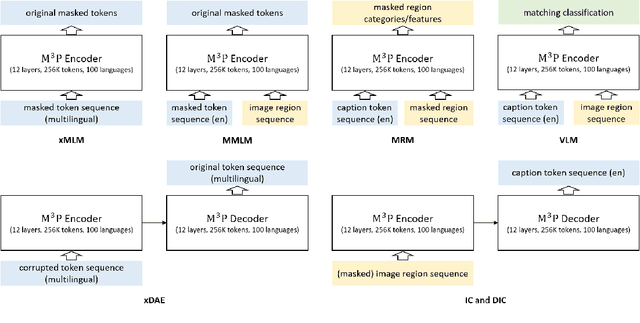


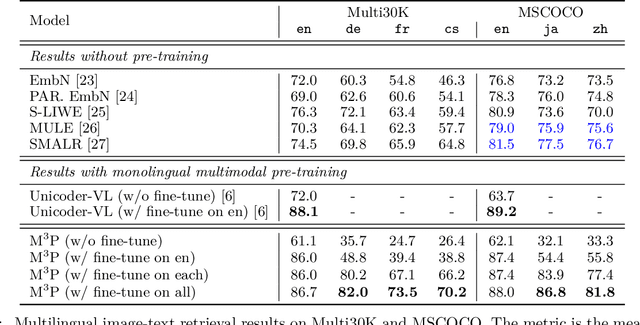
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
DocBank: A Benchmark Dataset for Document Layout Analysis
Jun 01, 2020
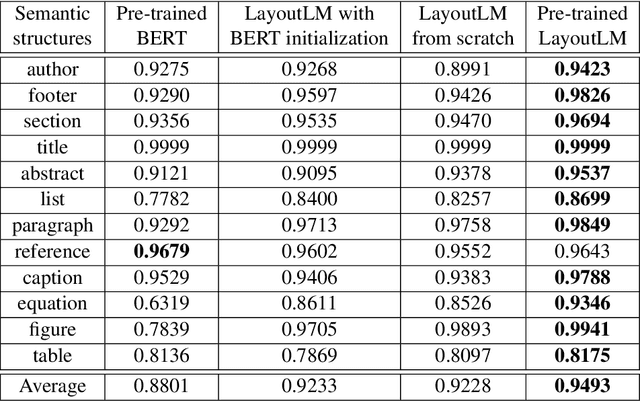

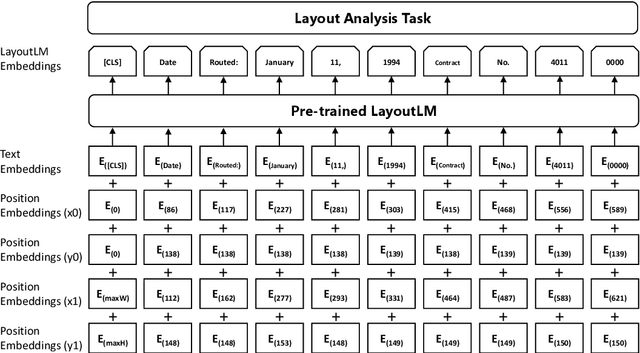
Document layout analysis usually relies on computer vision models to understand documents while ignoring textual information that is vital to capture. Meanwhile, high quality labeled datasets with both visual and textual information are still insufficient. In this paper, we present \textbf{DocBank}, a benchmark dataset with fine-grained token-level annotations for document layout analysis. DocBank is constructed using a simple yet effective way with weak supervision from the \LaTeX{} documents available on the arXiv.com. With DocBank, models from different modalities can be compared fairly and multi-modal approaches will be further investigated and boost the performance of document layout analysis. We build several strong baselines and manually split train/dev/test sets for evaluation. Experiment results show that models trained on DocBank accurately recognize the layout information for a variety of documents. The DocBank dataset will be publicly available at \url{https://github.com/doc-analysis/DocBank}.
Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension
May 13, 2020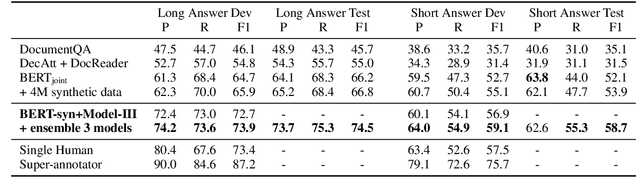

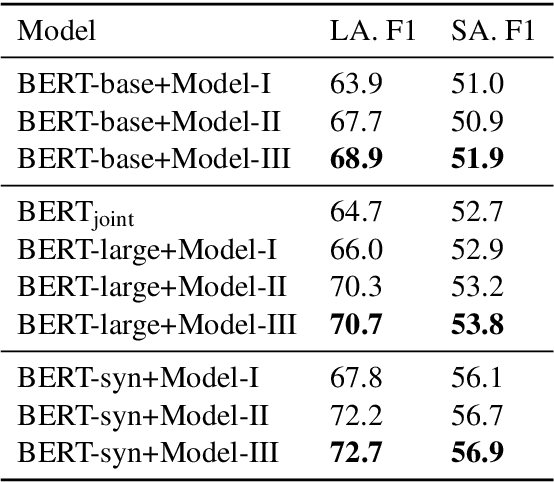

Natural Questions is a new challenging machine reading comprehension benchmark with two-grained answers, which are a long answer (typically a paragraph) and a short answer (one or more entities inside the long answer). Despite the effectiveness of existing methods on this benchmark, they treat these two sub-tasks individually during training while ignoring their dependencies. To address this issue, we present a novel multi-grained machine reading comprehension framework that focuses on modeling documents at their hierarchical nature, which are different levels of granularity: documents, paragraphs, sentences, and tokens. We utilize graph attention networks to obtain different levels of representations so that they can be learned simultaneously. The long and short answers can be extracted from paragraph-level representation and token-level representation, respectively. In this way, we can model the dependencies between the two-grained answers to provide evidence for each other. We jointly train the two sub-tasks, and our experiments show that our approach significantly outperforms previous systems at both long and short answer criteria.
Leveraging Declarative Knowledge in Text and First-Order Logic for Fine-Grained Propaganda Detection
Apr 29, 2020
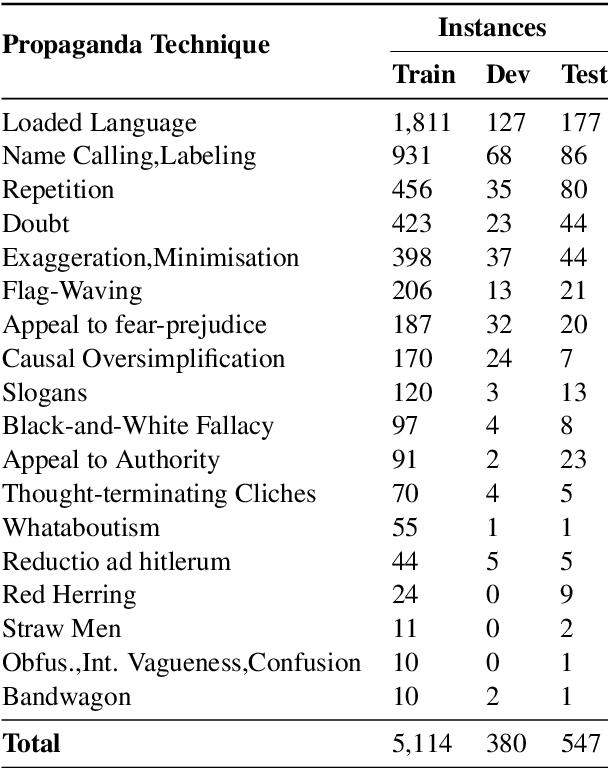
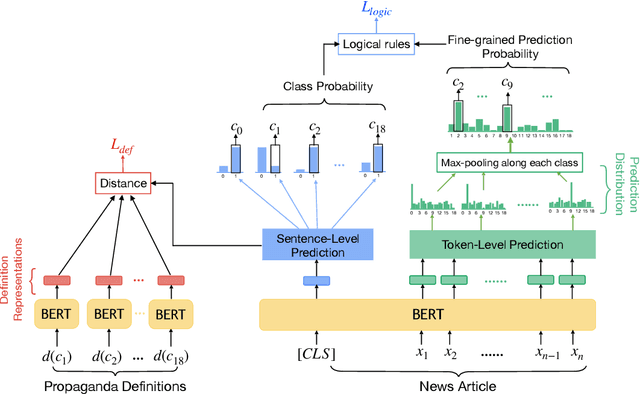

We study the detection of propagandistic text fragments in news articles. Instead of merely learning from input-output datapoints in training data, we introduce an approach to inject declarative knowledge of fine-grained propaganda techniques. We leverage declarative knowledge expressed in both natural language and first-order logic. The former refers to the literal definition of each propaganda technique, which is utilized to get class representations for regularizing the model parameters. The latter refers to logical consistency between coarse- and fine- grained predictions, which is used to regularize the training process with propositional Boolean expressions. We conduct experiments on Propaganda Techniques Corpus, a large manually annotated dataset for fine-grained propaganda detection. Experiments show that our method achieves superior performance, demonstrating that injecting declarative knowledge expressed in both natural language and first-order logic can help the model to make more accurate predictions.