 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: A General Evaluation Benchmark for Multimodal Tasks
Jun 18, 2021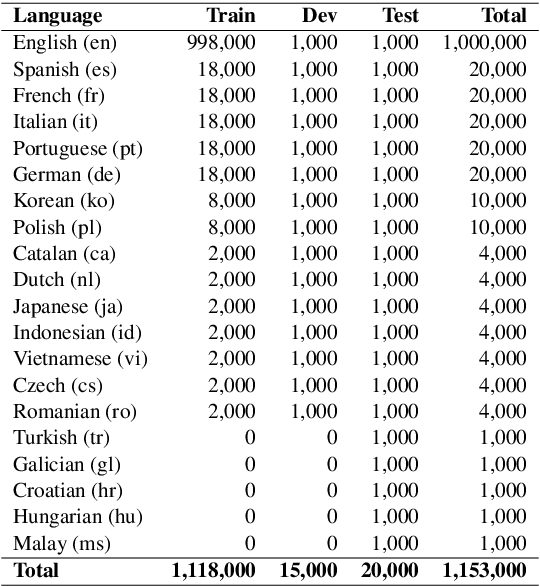

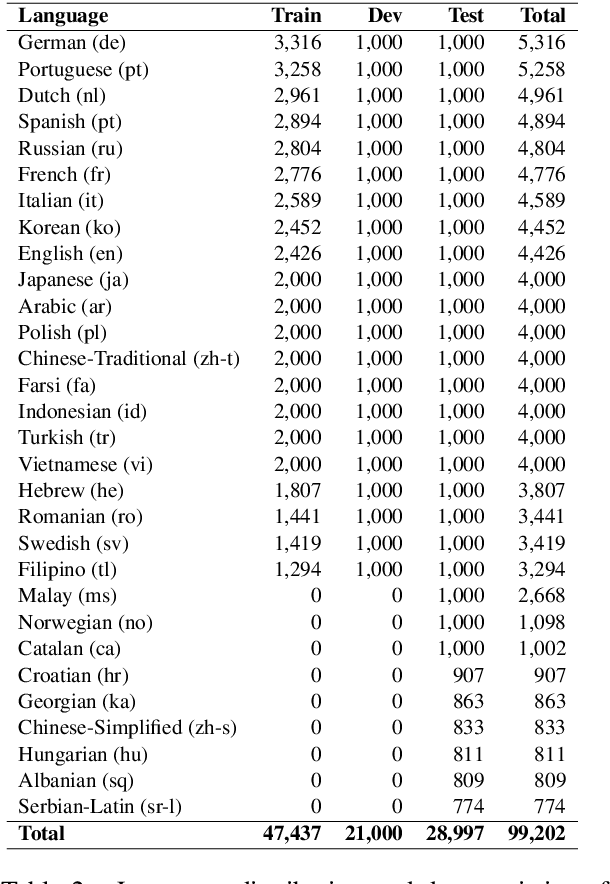

In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020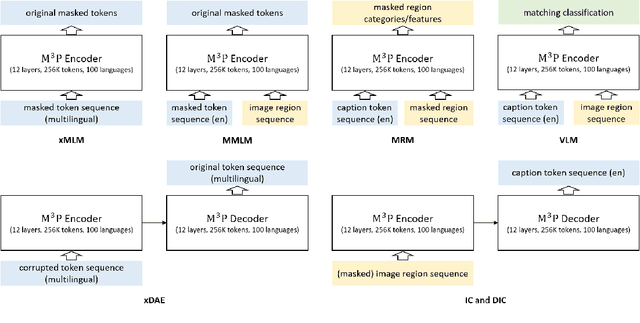


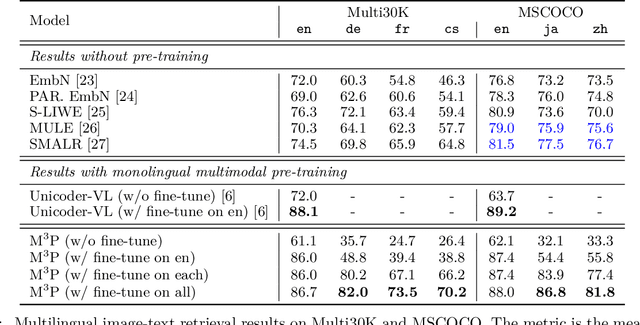
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020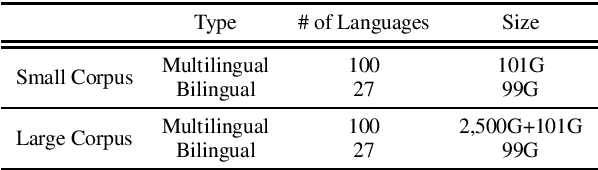
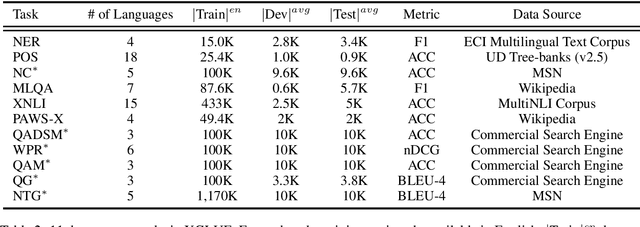
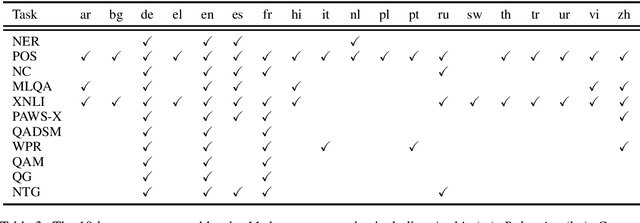
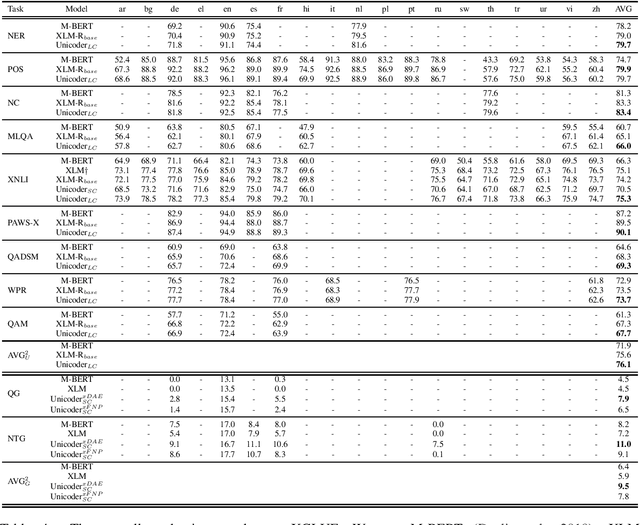
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
XGPT: Cross-modal Generative Pre-Training for Image Captioning
Mar 04, 2020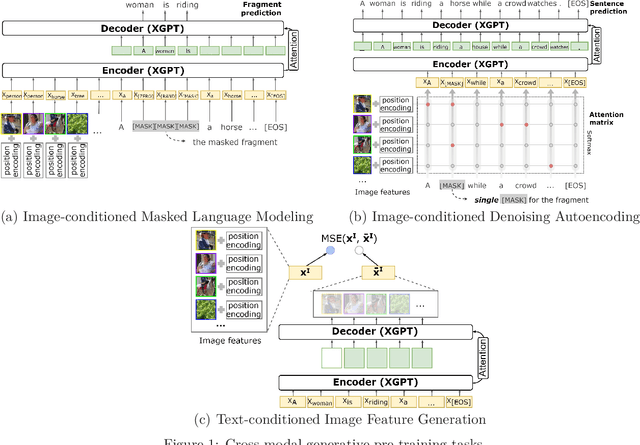
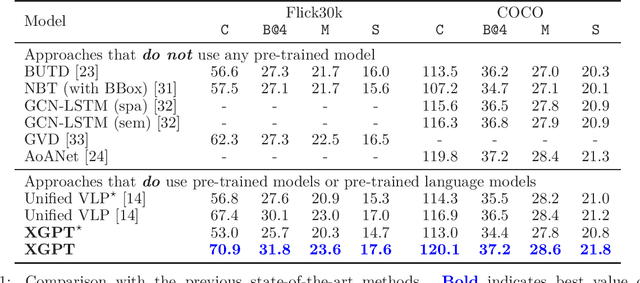
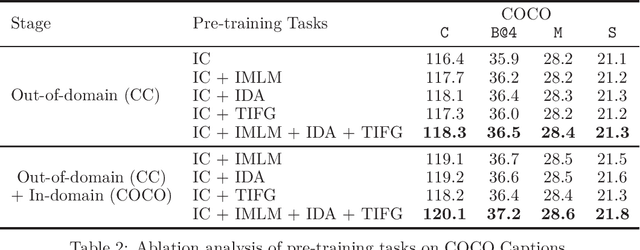
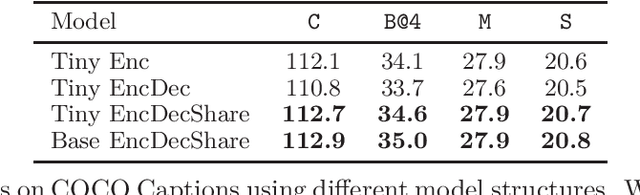
While many BERT-based cross-modal pre-trained models produce excellent results on downstream understanding tasks like image-text retrieval and VQA, they cannot be applied to generation tasks directly. In this paper, we propose XGPT, a new method of Cross-modal Generative Pre-Training for Image Captioning that is designed to pre-train text-to-image caption generators through three novel generation tasks, including Image-conditioned Masked Language Modeling (IMLM), Image-conditioned Denoising Autoencoding (IDA), and Text-conditioned Image Feature Generation (TIFG). As a result, the pre-trained XGPT can be fine-tuned without any task-specific architecture modifications to create state-of-the-art models for image captioning. Experiments show that XGPT obtains new state-of-the-art results on the benchmark datasets, including COCO Captions and Flickr30k Captions. We also use XGPT to generate new image captions as data augmentation for the image retrieval task and achieve significant improvement on all recall metrics.
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Jan 23, 2020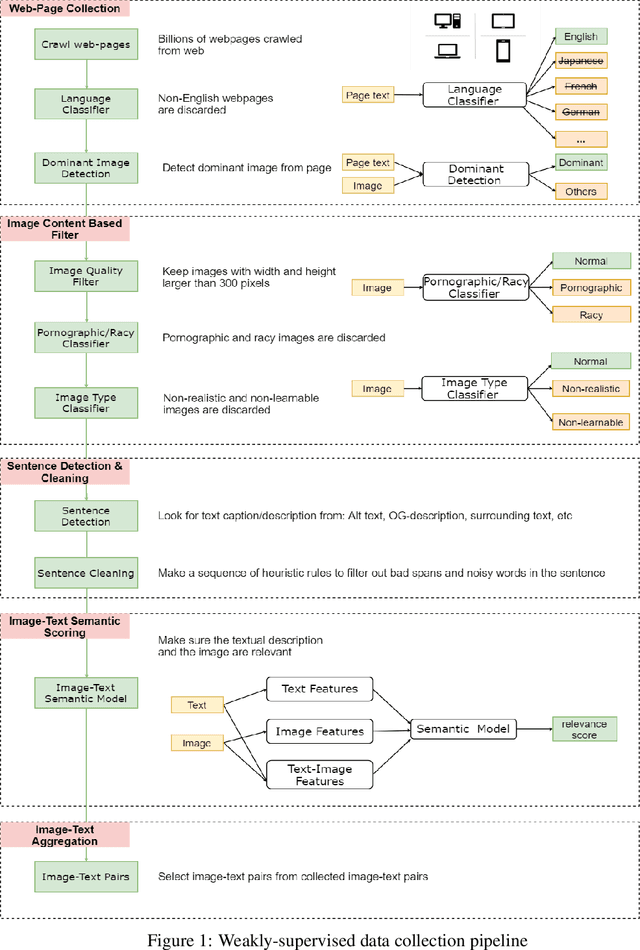
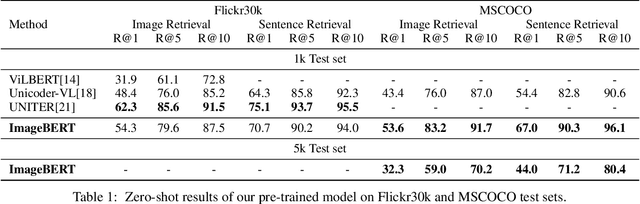

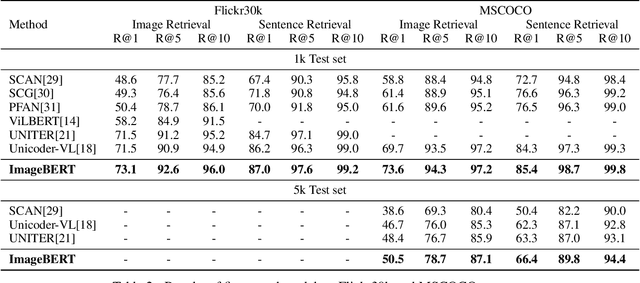
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.