 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe finite expression method for turbulent dynamics with high-order moment recovery
May 11, 2026Turbulent dynamical systems are characterized by nonlinear interactions and stochastic effects that generate coupled statistical quantities, such as non-zero higher-order moments, which are difficult to capture from data with accuracy. We propose a two-stage data-driven modeling framework that combines symbolic regression with generative models to jointly identify the governing dynamics and predict their key statistical quantities. In Stage I of the framework, the Finite Expression Method (FEX) is adopted to discover closed-form expressions of the deterministic dynamics, recovering nonlinear interaction terms and external forcing without predefined libraries. In Stage II, generative models are introduced to learn the residual stochastic components as a refined correction to the model error from the Stage I approximation, enabling accurate characterization of higher-order statistics. Theoretical analysis establishes the consistency of the symbolic estimator and quantifies the estimation error in terms of data size and numerical discretization. The model performance is verified through detailed numerical experiments on the stochastic triad models across multiple regimes, demonstrating that the framework successfully recovers interaction terms and forcing expressions, and accurately predicts statistical moments up to order five. These results highlight the potential of integrating interpretable symbolic discovery with data-driven stochastic modeling for complex turbulent systems.
Jeffreys Flow: Robust Boltzmann Generators for Rare Event Sampling via Parallel Tempering Distillation
Apr 07, 2026Sampling physical systems with rough energy landscapes is hindered by rare events and metastable trapping. While Boltzmann generators already offer a solution, their reliance on the reverse Kullback--Leibler divergence frequently induces catastrophic mode collapse, missing specific modes in multi-modal distributions. Here, we introduce the Jeffreys Flow, a robust generative framework that mitigates this failure by distilling empirical sampling data from Parallel Tempering trajectories using the symmetric Jeffreys divergence. This formulation effectively balances local target-seeking precision with global modes coverage. We show that minimizing Jeffreys divergence suppresses mode collapse and structurally corrects inherent inaccuracies via distillation of the empirical reference data. We demonstrate the framework's scalability and accuracy on highly non-convex multidimensional benchmarks, including the systematic correction of stochastic gradient biases in Replica Exchange Stochastic Gradient Langevin Dynamics and the massive acceleration of exact importance sampling in Path Integral Monte Carlo for quantum thermal states.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
DockSmith: Scaling Reliable Coding Environments via an Agentic Docker Builder
Jan 31, 2026Reliable Docker-based environment construction is a dominant bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We introduce DockSmith, a specialized agentic Docker builder designed to address this challenge. DockSmith treats environment construction not only as a preprocessing step, but as a core agentic capability that exercises long-horizon tool use, dependency reasoning, and failure recovery, yielding supervision that transfers beyond Docker building itself. DockSmith is trained on large-scale, execution-grounded Docker-building trajectories produced by a SWE-Factory-style pipeline augmented with a loop-detection controller and a cross-task success memory. Training a 30B-A3B model on these trajectories achieves open-source state-of-the-art performance on Multi-Docker-Eval, with 39.72% Fail-to-Pass and 58.28% Commit Rate. Moreover, DockSmith improves out-of-distribution performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0, demonstrating broader agentic benefits of environment construction.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
Predicting 3D representations for Dynamic Scenes
Jan 28, 2025



We present a novel framework for dynamic radiance field prediction given monocular video streams. Unlike previous methods that primarily focus on predicting future frames, our method goes a step further by generating explicit 3D representations of the dynamic scene. The framework builds on two core designs. First, we adopt an ego-centric unbounded triplane to explicitly represent the dynamic physical world. Second, we develop a 4D-aware transformer to aggregate features from monocular videos to update the triplane. Coupling these two designs enables us to train the proposed model with large-scale monocular videos in a self-supervised manner. Our model achieves top results in dynamic radiance field prediction on NVIDIA dynamic scenes, demonstrating its strong performance on 4D physical world modeling. Besides, our model shows a superior generalizability to unseen scenarios. Notably, we find that our approach emerges capabilities for geometry and semantic learning.
Slot-guided Volumetric Object Radiance Fields
Jan 04, 2024



We present a novel framework for 3D object-centric representation learning. Our approach effectively decomposes complex scenes into individual objects from a single image in an unsupervised fashion. This method, called slot-guided Volumetric Object Radiance Fields (sVORF), composes volumetric object radiance fields with object slots as a guidance to implement unsupervised 3D scene decomposition. Specifically, sVORF obtains object slots from a single image via a transformer module, maps these slots to volumetric object radiance fields with a hypernetwork and composes object radiance fields with the guidance of object slots at a 3D location. Moreover, sVORF significantly reduces memory requirement due to small-sized pixel rendering during training. We demonstrate the effectiveness of our approach by showing top results in scene decomposition and generation tasks of complex synthetic datasets (e.g., Room-Diverse). Furthermore, we also confirm the potential of sVORF to segment objects in real-world scenes (e.g., the LLFF dataset). We hope our approach can provide preliminary understanding of the physical world and help ease future research in 3D object-centric representation learning.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020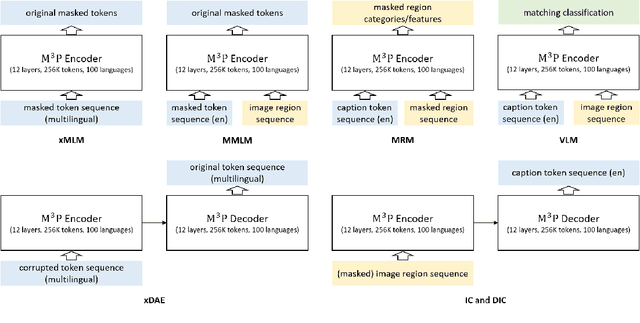


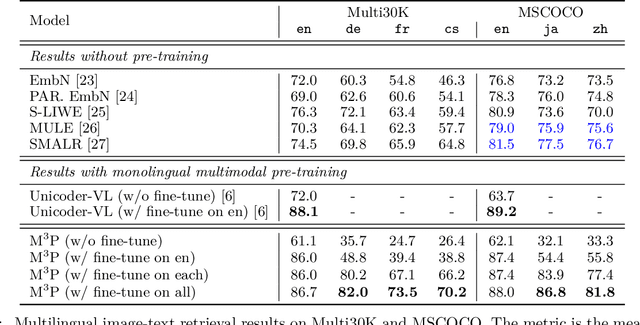
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Jan 23, 2020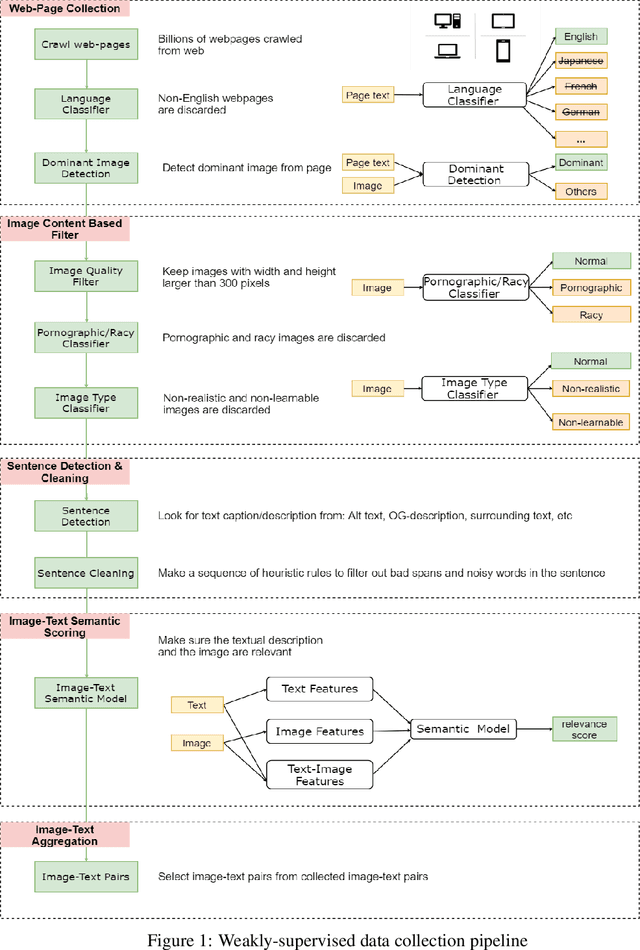
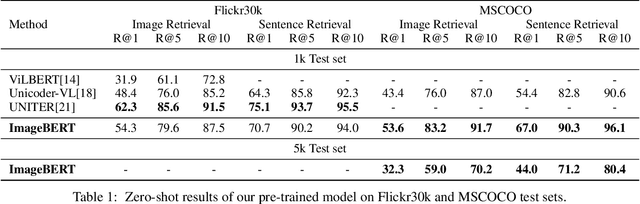

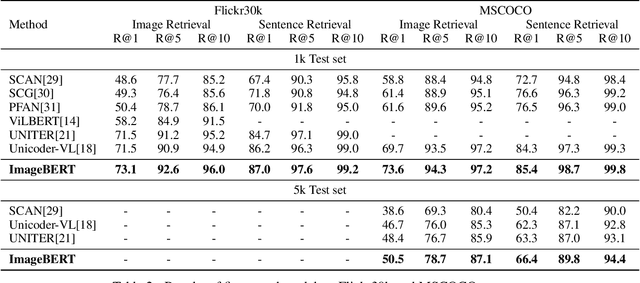
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.