 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?
Jun 09, 2026The deployment of Large Language Model (LLM) agents for computer automation is accelerating, yet their ability to navigate complex, professional-grade productivity software is largely untested. We argue that Office automation is an ideal environment for benchmarking document-automation capability, as it requires long-horizon planning and reasoning, precise parameter configuration, and multi-application integration. To quantify this capability, we introduce an evaluation based on China's National Computer Rank Examination (NCRE), featuring 200 comprehensive practical-operation tasks across Word, Excel, and PowerPoint. Each task is scored on a 100-point rubric scale using 7,118 machine-gradable criteria, and Score Rate (SR) denotes the mean percentage of rubric points earned across these tasks. We benchmark 7 frontier LLMs and observe stark limitations: single-turn models score a maximum of 36.6%. A stronger agentic system with execution feedback, iterative repair, and broader Office automation access reaches 68.8%, but remains below the 95.5% community-reference score used as a scoring sanity check. Ultimately, our experiments demonstrate that despite recent advancements in code generation, achieving reliable fine-grained Office document automation remains a significant challenge for current code-generating LLM and agent systems.
PoseCompass: Intelligent Synthetic Pose Selection for Visual Localization
May 12, 2026In visual localization, Absolute Pose Regression (APR) enables real-time 6-DoF camera pose inference from single images, yet critically depends on fine-tuning data quality and coverage. While recent methods leverage 3D Gaussian Splatting (3DGS) for novel view synthesis-based data augmentation, random sampling generates redundant views and noisy samples from poorly reconstructed regions. To mitigate this research gap, we propose PoseCompass, an intelligent pose selection pipeline for 3DGS-based APR. PoseCompass formulates synthetic pose selection and derives a value-based pose ranking mechanism to identify informative poses. The ranking integrates three dimensions: Localization Difficulty, favoring challenging regions; Coverage Novelty, exploring under-sampled areas; and Rendering Observability, filtering artifacts and noise. PoseCompass then generates trajectory-constrained candidates, selects the top-K ranked poses, and synthesizes views using 3DGS with lightweight diffusion-based alignment. Finally, the pose regressor is fine-tuned on mixed real and synthetic data. We evaluate PoseCompass on 7-Scenes, where it reduces adaptation time from 15.2 to 5.1 minutes, a 3x speedup, while cutting median pose errors by 53.8 percent and significantly outperforming random baselines.
On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
May 04, 2026Large language models (LLMs) have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
Only Say What You Know: Calibration-Aware Generation for Long-Form Factuality
May 03, 2026Large Reasoning Models achieve strong performance on complex tasks but remain prone to hallucinations, particularly in long-form generation where errors compound across reasoning steps. Existing approaches to improving factuality, including abstention and factuality-driven optimization, follow a \emph{coupled exploration-commitment} paradigm, in which intermediate reasoning is unconditionally propagated to the final output, limiting fine-grained control over information selection and integration. In this paper, we propose an \textbf{Exploration-Commitment Decoupling} paradigm that disentangles knowledge exploration from final commitment, enabling models to explore with awareness while answering cautiously. We instantiate the paradigm with \textbf{Calibration-Aware Generation (CAG)}, a framework that equips models with end-to-end, calibration-aware generation capabilities, by augmenting intermediate reasoning with calibrated reliability estimates and prioritizing reliable content in final outputs. Across five long-form factuality benchmarks and multiple model families, CAG improves factuality by up to 13%, while reducing decoding time by up to 37%. Overall, our work highlights decoupling as a principled approach for more reliable long-form generation, offering directions for trustworthy and self-aware generative systems.
Distributed Optimization-Learning with Graph Transformers for Terahertz Cell-Free Integrated Sensing and Communication Systems
Apr 11, 2026In this paper, we propose a distributed optimization-learning framework for terahertz (THz) cell-free integrated sensing and communication (CF-ISAC) systems, termed Distributed Optimization-Learning with Graph Transformers (DOLG). We first formulate a highly non-convex joint scheduling and signal design problem for THz CF-ISAC systems, jointly optimizing access point (AP)-user equipment (UE) association and beamforming under signal to interference plus noise ratio based communication and Cramér-Rao bound based sensing constraints, together with line-of-sight-driven visibility rules and per-AP power constraints. We also develop an optimization based benchmark utilizing a tractable relaxed reformulation. Building upon this optimization structure, we redesign a graph transformer network (GTN) as an optimization-aware representation module that encodes cross-field wavefront geometry, blockage visibility, and sensing relevance in a permutation-equivariant manner. The proposed DOLG framework amortizes the iterative optimization procedure into a scalable GTN-conditioned distributed multi-agent reinforcement learning policy through centralized training and decentralized execution, while preserving per-AP power constraints via structure-preserving projections. Simulation results demonstrate that the proposed DOLG framework achieves stable convergence and effectively balances the communication-sensing tradeoff. From the system-level perspective, it outperforms multicell and non-joint design baselines. Furthermore, it surpasses conventional optimization based and heuristic approaches in terms of both ISAC performance and computational scalability.
Learning to Draft: Adaptive Speculative Decoding with Reinforcement Learning
Mar 02, 2026Speculative decoding accelerates large language model (LLM) inference by using a small draft model to generate candidate tokens for a larger target model to verify. The efficacy of this technique hinges on the trade-off between the time spent on drafting candidates and verifying them. However, current state-of-the-art methods rely on a static time allocation, while recent dynamic approaches optimize for proxy metrics like acceptance length, often neglecting the true time cost and treating the drafting and verification phases in isolation. To address these limitations, we introduce Learning to Draft (LTD), a novel method that directly optimizes for throughput of each draft-and-verify cycle. We formulate the problem as a reinforcement learning environment and train two co-adaptive policies to dynamically coordinate the draft and verification phases. This encourages the policies to adapt to each other and explicitly maximize decoding efficiency. We conducted extensive evaluations on five diverse LLMs and four distinct tasks. Our results show that LTD achieves speedup ratios ranging from 2.24x to 4.32x, outperforming the state-of-the-art method Eagle3 up to 36.4%.
Symbol-Aware Precoder Design for Physical-Layer Anonymous Communications
Feb 24, 2026Physical-layer characteristics, such as channel state information (CSI) and transmitter noise induced by hardware impairments, are often uniquely associated with a transmitter. This paper investigates transmitter anonymity at the physical layer from a signal design perspective. We consider an anonymous communication problem where the receiver should reliably decode the signal from the transmitter but should not make use of the signal to infer the transmitter's identity.Transmitter anonymity is quantified using a Kullback-Leibler divergence (KLD)-based metric, which enables the formulation of explicit anonymity constraints in the precoder design.We then propose an anonymous symbol-level precoding strategy that preserves reliable communication under spatial multiplexing while preventing transmitter identification. The proposed framework employs a partitioned equal-gain combining (P-EGC) scheme that leverages receiver diversity without requiring transmitter-specific CSI. Simulation results demonstrate anonymity-reliability tradeoffs across different signal-to-noise ratios (SNRs) and numbers of data streams. Moreover, the results reveal opposite trends of anonymity with respect to transmitter-dependent noise variations in the low-SNR and high-SNR regimes.
Impact of Pointing Error on Coverage Performance of 3D Indoor Terahertz Communication Systems
Jan 29, 2026In this paper, we develop a tractable analytical framework for a three-dimensional (3D) indoor terahertz (THz) communication system to theoretically assess the impact of the pointing error on its coverage performance. Specifically, we model the locations of access points (APs) using a Poisson point process, human blockages as random cylinder processes, and wall blockages through a Boolean straight line process. A pointing error refers to beamforming gain and direction mismatch between the transmitter and receiver. We characterize it based on the inaccuracy of location estimate. We then analyze the impact of this pointing error on the received signal power and derive a tractable expression for the coverage probability, incorporating the multi-cluster fluctuating two-ray distribution to accurately model small-scale fading in THz communications. Aided by simulation results, we corroborate our analysis and demonstrate that the pointing error has a pronounced impact on the coverage probability. Specifically, we find that merely increasing the antenna array size is insufficient to improve the coverage probability and mitigate the detrimental impact of the pointing error, highlighting the necessity of advanced estimation techniques in THz communication systems.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Optimal Look-back Horizon for Time Series Forecasting in Federated Learning
Nov 18, 2025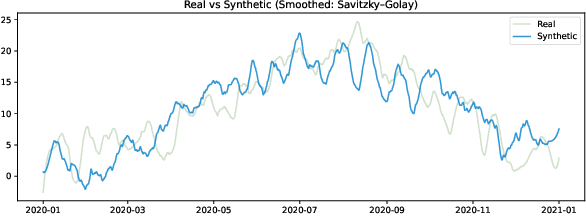
Selecting an appropriate look-back horizon remains a fundamental challenge in time series forecasting (TSF), particularly in the federated learning scenarios where data is decentralized, heterogeneous, and often non-independent. While recent work has explored horizon selection by preserving forecasting-relevant information in an intrinsic space, these approaches are primarily restricted to centralized and independently distributed settings. This paper presents a principled framework for adaptive horizon selection in federated time series forecasting through an intrinsic space formulation. We introduce a synthetic data generator (SDG) that captures essential temporal structures in client data, including autoregressive dependencies, seasonality, and trend, while incorporating client-specific heterogeneity. Building on this model, we define a transformation that maps time series windows into an intrinsic representation space with well-defined geometric and statistical properties. We then derive a decomposition of the forecasting loss into a Bayesian term, which reflects irreducible uncertainty, and an approximation term, which accounts for finite-sample effects and limited model capacity. Our analysis shows that while increasing the look-back horizon improves the identifiability of deterministic patterns, it also increases approximation error due to higher model complexity and reduced sample efficiency. We prove that the total forecasting loss is minimized at the smallest horizon where the irreducible loss starts to saturate, while the approximation loss continues to rise. This work provides a rigorous theoretical foundation for adaptive horizon selection for time series forecasting in federated learning.