 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Training Bottlenecks: Effective and Stable Reinforcement Learning for Coding Models
Mar 08, 2026Modern code generation models exhibit longer outputs, accelerated capability growth, and changed training dynamics, rendering traditional training methodologies, algorithms, and datasets ineffective for improving their performance. To address these training bottlenecks, we propose MicroCoder-GRPO, an improved Group Relative Policy Optimization approach with three innovations: conditional truncation masking to improve long output potential while maintaining training stability, diversity-determined temperature selection to maintain and encourage output diversity, and removal of KL loss with high clipping ratios to facilitate solution diversity. MicroCoder-GRPO achieves up to 17.6% relative improvement over strong baselines on LiveCodeBench v6, with more pronounced gains under extended context evaluation. Additionally, we release MicroCoder-Dataset, a more challenging training corpus that achieves 3x larger performance gains than mainstream datasets on LiveCodeBench v6 within 300 training steps, and MicroCoder-Evaluator, a robust framework with approximately 25% improved evaluation accuracy and around 40% faster execution. Through comprehensive analysis across more than thirty controlled experiments, we reveal 34 training insights across seven main aspects, demonstrating that properly trained models can achieve competitive performance with larger counterparts.
SlideSparse: Fast and Flexible (2N-2):2N Structured Sparsity
Mar 05, 2026NVIDIA's 2:4 Sparse Tensor Cores deliver 2x throughput but demand strict 50% pruning -- a ratio that collapses LLM reasoning accuracy (Qwen3: 54% to 15%). Milder $(2N-2):2N$ patterns (e.g., 6:8, 25% pruning) preserve accuracy yet receive no hardware support, falling back to dense execution without any benefit from sparsity. We present SlideSparse, the first system to unlock Sparse Tensor Core acceleration for the $(2N-2):2N$ model family on commodity GPUs. Our Sliding Window Decomposition reconstructs any $(2N-2):2N$ weight block into $N-1$ overlapping 2:4-compliant windows without any accuracy loss; Activation Lifting fuses the corresponding activation rearrangement into per-token quantization at near-zero cost. Integrated into vLLM, SlideSparse is evaluated across various GPUs (A100, H100, B200, RTX 4090, RTX 5080, DGX-spark), precisions (FP4, INT8, FP8, BF16, FP16), and model families (Llama, Qwen, BitNet). On compute-bound workloads, the measured speedup ratio (1.33x) approaches the theoretical upper-bound $N/(N-1)=4/3$ at 6:8 weight sparsity in Qwen2.5-7B, establishing $(2N-2):2N$ as a practical path to accuracy-preserving LLM acceleration. Code available at https://github.com/bcacdwk/vllmbench.
Sparse-BitNet: 1.58-bit LLMs are Naturally Friendly to Semi-Structured Sparsity
Mar 05, 2026Semi-structured N:M sparsity and low-bit quantization (e.g., 1.58-bit BitNet) are two promising approaches for improving the efficiency of large language models (LLMs), yet they have largely been studied in isolation. In this work, we investigate their interaction and show that 1.58-bit BitNet is naturally more compatible with N:M sparsity than full-precision models. To study this effect, we propose Sparse-BitNet, a unified framework that jointly applies 1.58-bit quantization and dynamic N:M sparsification while ensuring stable training for the first time. Across multiple model scales and training regimes (sparse pretraining and dense-to-sparse schedules), 1.58-bit BitNet consistently exhibits smaller performance degradation than full-precision baselines at the same sparsity levels and can tolerate higher structured sparsity before accuracy collapse. Moreover, using our custom sparse tensor core, Sparse-BitNet achieves substantial speedups in both training and inference, reaching up to 1.30X. These results highlight that combining extremely low-bit quantization with semi-structured N:M sparsity is a promising direction for efficient LLMs. Code available at https://github.com/AAzdi/Sparse-BitNet
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
Black-Box On-Policy Distillation of Large Language Models
Nov 13, 2025Black-box distillation creates student large language models (LLMs) by learning from a proprietary teacher model's text outputs alone, without access to its internal logits or parameters. In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation. GAD frames the student LLM as a generator and trains a discriminator to distinguish its responses from the teacher LLM's, creating a minimax game. The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback. Experimental results show that GAD consistently surpasses the commonly used sequence-level knowledge distillation. In particular, Qwen2.5-14B-Instruct (student) trained with GAD becomes comparable to its teacher, GPT-5-Chat, on the LMSYS-Chat automatic evaluation. The results establish GAD as a promising and effective paradigm for black-box LLM distillation.
The Era of Agentic Organization: Learning to Organize with Language Models
Oct 30, 2025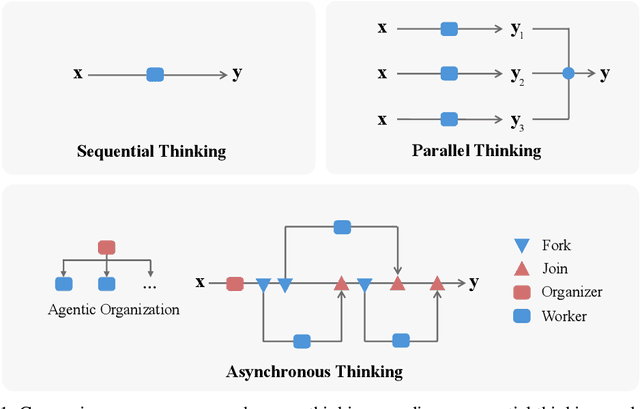

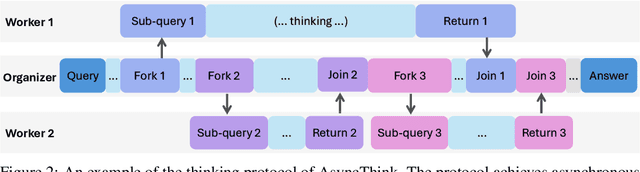
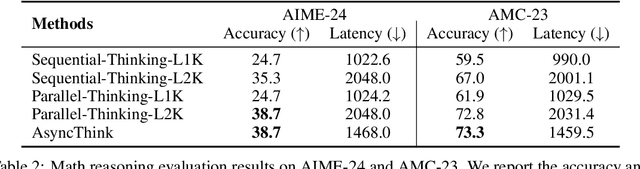
We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with large language models, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
Oct 27, 2025Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.
On-Policy RL with Optimal Reward Baseline
May 29, 2025Reinforcement learning algorithms are fundamental to align large language models with human preferences and to enhance their reasoning capabilities. However, current reinforcement learning algorithms often suffer from training instability due to loose on-policy constraints and computational inefficiency due to auxiliary models. In this work, we propose On-Policy RL with Optimal reward baseline (OPO), a novel and simplified reinforcement learning algorithm designed to address these challenges. OPO emphasizes the importance of exact on-policy training, which empirically stabilizes the training process and enhances exploration. Moreover, OPO introduces the optimal reward baseline that theoretically minimizes gradient variance. We evaluate OPO on mathematical reasoning benchmarks. The results demonstrate its superior performance and training stability without additional models or regularization terms. Furthermore, OPO achieves lower policy shifts and higher output entropy, encouraging more diverse and less repetitive responses. These results highlight OPO as a promising direction for stable and effective reinforcement learning in large language model alignment and reasoning tasks. The implementation is provided at https://github.com/microsoft/LMOps/tree/main/opo.
Think Only When You Need with Large Hybrid-Reasoning Models
May 21, 2025Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model's capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
Reward Reasoning Model
May 20, 2025



Reward models play a critical role in guiding large language models toward outputs that align with human expectations. However, an open challenge remains in effectively utilizing test-time compute to enhance reward model performance. In this work, we introduce Reward Reasoning Models (RRMs), which are specifically designed to execute a deliberate reasoning process before generating final rewards. Through chain-of-thought reasoning, RRMs leverage additional test-time compute for complex queries where appropriate rewards are not immediately apparent. To develop RRMs, we implement a reinforcement learning framework that fosters self-evolved reward reasoning capabilities without requiring explicit reasoning traces as training data. Experimental results demonstrate that RRMs achieve superior performance on reward modeling benchmarks across diverse domains. Notably, we show that RRMs can adaptively exploit test-time compute to further improve reward accuracy. The pretrained reward reasoning models are available at https://huggingface.co/Reward-Reasoning.