 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Multi-Step Tool Orchestration with Constrained Data Synthesis and Graduated Rewards
Mar 25, 2026Multi-step tool orchestration, where LLMs must invoke multiple dependent APIs in the correct order while propagating intermediate outputs, remains challenging. State-of-the-art models frequently fail on full sequence execution, with parameter value errors accounting for a significant portion of failures. Training models to handle such workflows faces two obstacles: existing environments focus on simple per-turn function calls with simulated data, and binary rewards provide no signal for partial correctness. We present a framework addressing both challenges. First, we construct a reinforcement learning environment backed by a large-scale cache of real API responses, enabling a data synthesis pipeline that samples valid multi-step orchestration traces with controllable complexity and significantly higher generation efficiency than unconstrained methods. Second, we propose a graduated reward design that decomposes correctness into atomic validity (individual function call correctness at increasing granularity) and orchestration (correct tool sequencing with dependency respect). On ComplexFuncBench, our approach demonstrates substantial improvements in turn accuracy. Ablation studies confirm both reward components are essential: using either alone significantly degrades performance.
Stabilizing Reinforcement Learning for Honesty Alignment in Language Models on Deductive Reasoning
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has recently emerged as a promising framework for aligning language models with complex reasoning objectives. However, most existing methods optimize only for final task outcomes, leaving models vulnerable to collapse when negative rewards dominate early training. This challenge is especially pronounced in honesty alignment, where models must not only solve answerable queries but also identify when conclusions cannot be drawn from the given premises. Deductive reasoning provides an ideal testbed because it isolates reasoning capability from reliance on external factual knowledge. To investigate honesty alignment, we curate two multi-step deductive reasoning datasets from graph structures, one for linear algebra and one for logical inference, and introduce unanswerable cases by randomly perturbing an edge in half of the instances. We find that GRPO, with or without supervised fine tuning initialization, struggles on these tasks. Through extensive experiments across three models, we evaluate stabilization strategies and show that curriculum learning provides some benefit but requires carefully designed in distribution datasets with controllable difficulty. To address these limitations, we propose Anchor, a reinforcement learning method that injects ground truth trajectories into rollouts, preventing early training collapse. Our results demonstrate that this method stabilizes learning and significantly improves the overall reasoning performance, underscoring the importance of training dynamics for enabling reliable deductive reasoning in aligned language models.
On Synthetic Data Strategies for Domain-Specific Generative Retrieval
Feb 25, 2025



This paper investigates synthetic data generation strategies in developing generative retrieval models for domain-specific corpora, thereby addressing the scalability challenges inherent in manually annotating in-domain queries. We study the data strategies for a two-stage training framework: in the first stage, which focuses on learning to decode document identifiers from queries, we investigate LLM-generated queries across multiple granularity (e.g. chunks, sentences) and domain-relevant search constraints that can better capture nuanced relevancy signals. In the second stage, which aims to refine document ranking through preference learning, we explore the strategies for mining hard negatives based on the initial model's predictions. Experiments on public datasets over diverse domains demonstrate the effectiveness of our synthetic data generation and hard negative sampling approach.
Multimodal Reranking for Knowledge-Intensive Visual Question Answering
Jul 17, 2024



Knowledge-intensive visual question answering requires models to effectively use external knowledge to help answer visual questions. A typical pipeline includes a knowledge retriever and an answer generator. However, a retriever that utilizes local information, such as an image patch, may not provide reliable question-candidate relevance scores. Besides, the two-tower architecture also limits the relevance score modeling of a retriever to select top candidates for answer generator reasoning. In this paper, we introduce an additional module, a multi-modal reranker, to improve the ranking quality of knowledge candidates for answer generation. Our reranking module takes multi-modal information from both candidates and questions and performs cross-item interaction for better relevance score modeling. Experiments on OK-VQA and A-OKVQA show that multi-modal reranker from distant supervision provides consistent improvements. We also find a training-testing discrepancy with reranking in answer generation, where performance improves if training knowledge candidates are similar to or noisier than those used in testing.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

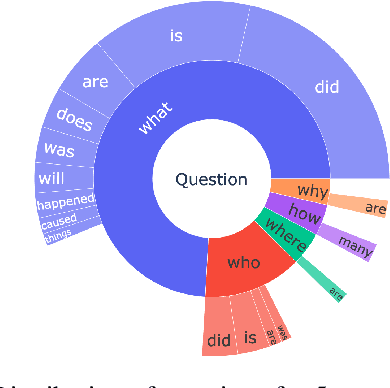
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.
VAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
Jun 02, 2021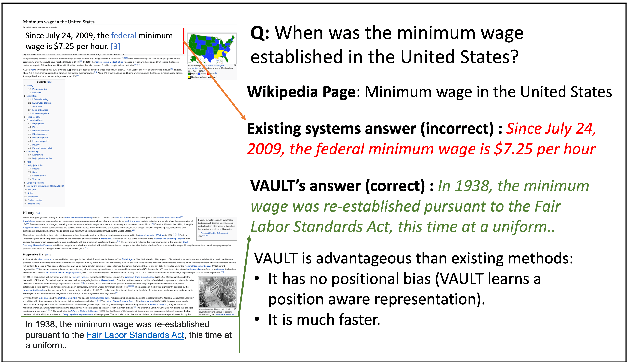
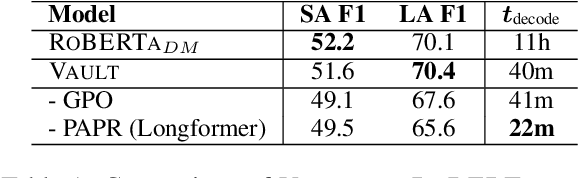
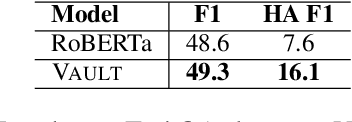
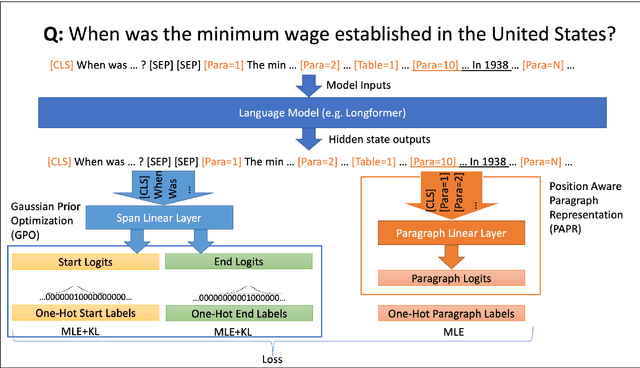
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain -- TechQA -- with large improvement over a model fine-tuned on a previously published large PLM.
Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension
May 13, 2020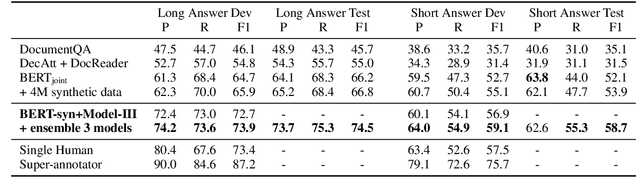

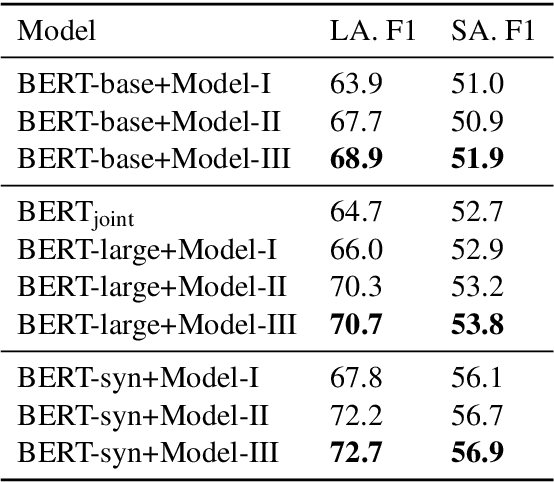

Natural Questions is a new challenging machine reading comprehension benchmark with two-grained answers, which are a long answer (typically a paragraph) and a short answer (one or more entities inside the long answer). Despite the effectiveness of existing methods on this benchmark, they treat these two sub-tasks individually during training while ignoring their dependencies. To address this issue, we present a novel multi-grained machine reading comprehension framework that focuses on modeling documents at their hierarchical nature, which are different levels of granularity: documents, paragraphs, sentences, and tokens. We utilize graph attention networks to obtain different levels of representations so that they can be learned simultaneously. The long and short answers can be extracted from paragraph-level representation and token-level representation, respectively. In this way, we can model the dependencies between the two-grained answers to provide evidence for each other. We jointly train the two sub-tasks, and our experiments show that our approach significantly outperforms previous systems at both long and short answer criteria.
Entity-Consistent End-to-end Task-Oriented Dialogue System with KB Retriever
Sep 18, 2019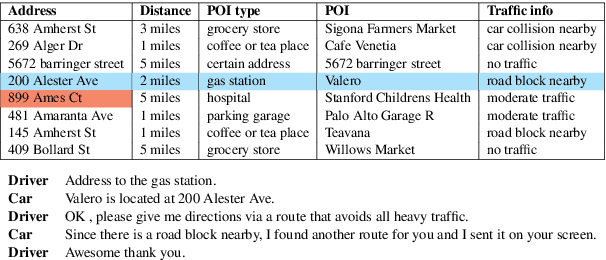
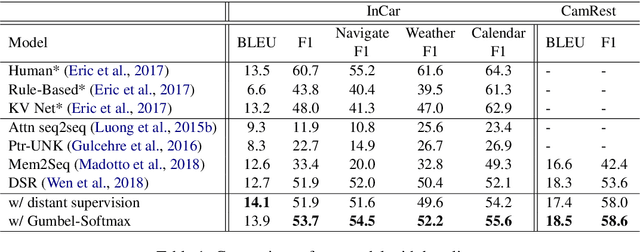
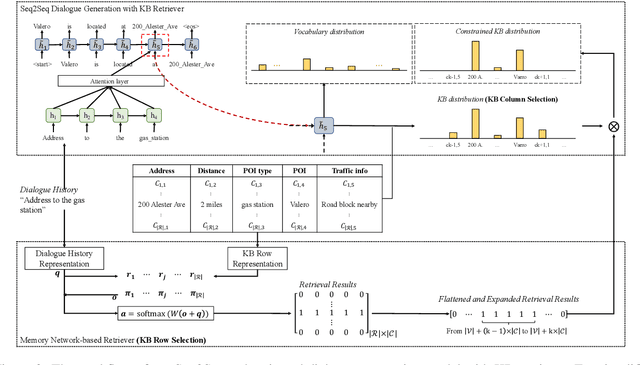
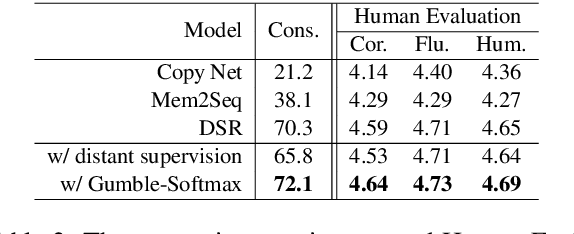
Querying the knowledge base (KB) has long been a challenge in the end-to-end task-oriented dialogue system. Previous sequence-to-sequence (Seq2Seq) dialogue generation work treats the KB query as an attention over the entire KB, without the guarantee that the generated entities are consistent with each other. In this paper, we propose a novel framework which queries the KB in two steps to improve the consistency of generated entities. In the first step, inspired by the observation that a response can usually be supported by a single KB row, we introduce a KB retrieval component which explicitly returns the most relevant KB row given a dialogue history. The retrieval result is further used to filter the irrelevant entities in a Seq2Seq response generation model to improve the consistency among the output entities. In the second step, we further perform the attention mechanism to address the most correlated KB column. Two methods are proposed to make the training feasible without labeled retrieval data, which include distant supervision and Gumbel-Softmax technique. Experiments on two publicly available task oriented dialog datasets show the effectiveness of our model by outperforming the baseline systems and producing entity-consistent responses.
A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding
Sep 05, 2019
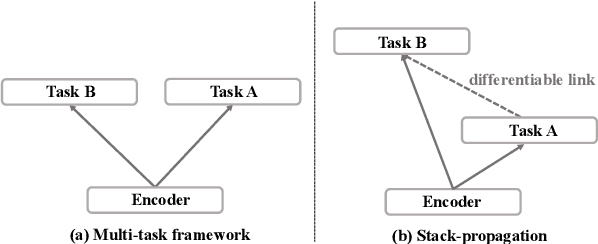
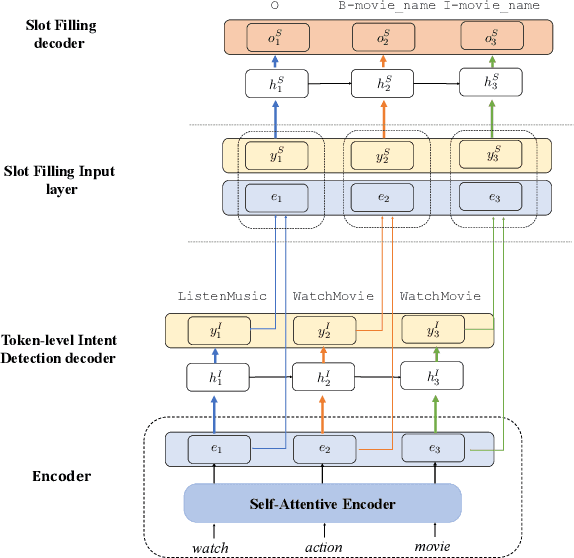
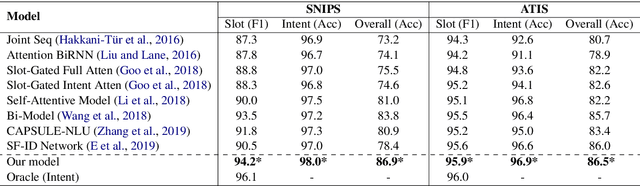
Intent detection and slot filling are two main tasks for building a spoken language understanding (SLU) system. The two tasks are closely tied and the slots often highly depend on the intent. In this paper, we propose a novel framework for SLU to better incorporate the intent information, which further guides the slot filling. In our framework, we adopt a joint model with Stack-Propagation which can directly use the intent information as input for slot filling, thus to capture the intent semantic knowledge. In addition, to further alleviate the error propagation, we perform the token-level intent detection for the Stack-Propagation framework. Experiments on two publicly datasets show that our model achieves the state-of-the-art performance and outperforms other previous methods by a large margin. Finally, we use the Bidirectional Encoder Representation from Transformer (BERT) model in our framework, which further boost our performance in SLU task.
Sequence-to-Sequence Learning for Task-oriented Dialogue with Dialogue State Representation
Jun 12, 2018



Classic pipeline models for task-oriented dialogue system require explicit modeling the dialogue states and hand-crafted action spaces to query a domain-specific knowledge base. Conversely, sequence-to-sequence models learn to map dialogue history to the response in current turn without explicit knowledge base querying. In this work, we propose a novel framework that leverages the advantages of classic pipeline and sequence-to-sequence models. Our framework models a dialogue state as a fixed-size distributed representation and use this representation to query a knowledge base via an attention mechanism. Experiment on Stanford Multi-turn Multi-domain Task-oriented Dialogue Dataset shows that our framework significantly outperforms other sequence-to-sequence based baseline models on both automatic and human evaluation.