 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPO: Condition Preference Optimization for Controllable Image Generation
Nov 06, 2025To enhance controllability in text-to-image generation, ControlNet introduces image-based control signals, while ControlNet++ improves pixel-level cycle consistency between generated images and the input control signal. To avoid the prohibitive cost of back-propagating through the sampling process, ControlNet++ optimizes only low-noise timesteps (e.g., $t < 200$) using a single-step approximation, which not only ignores the contribution of high-noise timesteps but also introduces additional approximation errors. A straightforward alternative for optimizing controllability across all timesteps is Direct Preference Optimization (DPO), a fine-tuning method that increases model preference for more controllable images ($I^{w}$) over less controllable ones ($I^{l}$). However, due to uncertainty in generative models, it is difficult to ensure that win--lose image pairs differ only in controllability while keeping other factors, such as image quality, fixed. To address this, we propose performing preference learning over control conditions rather than generated images. Specifically, we construct winning and losing control signals, $\mathbf{c}^{w}$ and $\mathbf{c}^{l}$, and train the model to prefer $\mathbf{c}^{w}$. This method, which we term \textit{Condition Preference Optimization} (CPO), eliminates confounding factors and yields a low-variance training objective. Our approach theoretically exhibits lower contrastive loss variance than DPO and empirically achieves superior results. Moreover, CPO requires less computation and storage for dataset curation. Extensive experiments show that CPO significantly improves controllability over the state-of-the-art ControlNet++ across multiple control types: over $10\%$ error rate reduction in segmentation, $70$--$80\%$ in human pose, and consistent $2$--$5\%$ reductions in edge and depth maps.
RETuning: Upgrading Inference-Time Scaling for Stock Movement Prediction with Large Language Models
Oct 24, 2025Recently, large language models (LLMs) have demonstrated outstanding reasoning capabilities on mathematical and coding tasks. However, their application to financial tasks-especially the most fundamental task of stock movement prediction-remains underexplored. We study a three-class classification problem (up, hold, down) and, by analyzing existing reasoning responses, observe that: (1) LLMs follow analysts' opinions rather than exhibit a systematic, independent analytical logic (CoTs). (2) LLMs list summaries from different sources without weighing adversarial evidence, yet such counterevidence is crucial for reliable prediction. It shows that the model does not make good use of its reasoning ability to complete the task. To address this, we propose Reflective Evidence Tuning (RETuning), a cold-start method prior to reinforcement learning, to enhance prediction ability. While generating CoT, RETuning encourages dynamically constructing an analytical framework from diverse information sources, organizing and scoring evidence for price up or down based on that framework-rather than on contextual viewpoints-and finally reflecting to derive the prediction. This approach maximally aligns the model with its learned analytical framework, ensuring independent logical reasoning and reducing undue influence from context. We also build a large-scale dataset spanning all of 2024 for 5,123 A-share stocks, with long contexts (32K tokens) and over 200K samples. In addition to price and news, it incorporates analysts' opinions, quantitative reports, fundamental data, macroeconomic indicators, and similar stocks. Experiments show that RETuning successfully unlocks the model's reasoning ability in the financial domain. Inference-time scaling still works even after 6 months or on out-of-distribution stocks, since the models gain valuable insights about stock movement prediction.
CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025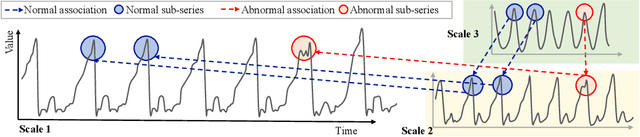

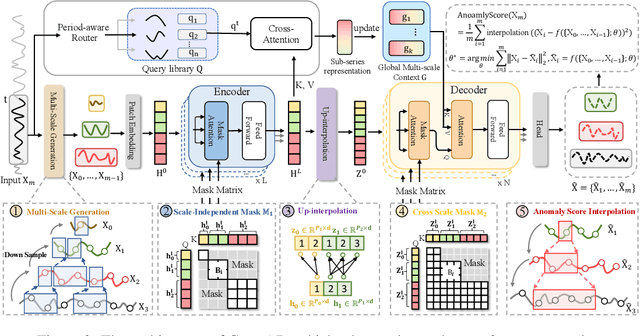

Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.
Spatially-Augmented Sequence-to-Sequence Neural Diarization for Meetings
Oct 10, 2025This paper proposes a Spatially-Augmented Sequence-to-Sequence Neural Diarization (SA-S2SND) framework, which integrates direction-of-arrival (DOA) cues estimated by SRP-DNN into the S2SND backbone. A two-stage training strategy is adopted: the model is first trained with single-channel audio and DOA features, and then further optimized with multi-channel inputs under DOA guidance. In addition, a simulated DOA generation scheme is introduced to alleviate dependence on matched multi-channel corpora. On the AliMeeting dataset, SA-S2SND consistently outperform the S2SND baseline, achieving a 7.4% relative DER reduction in the offline mode and over 19% improvement when combined with channel attention. These results demonstrate that spatial cues are highly complementary to cross-channel modeling, yielding good performance in both online and offline settings.
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Oct 02, 2025Diffusion models have revolutionized image and video generation, achieving unprecedented visual quality. However, their reliance on transformer architectures incurs prohibitively high computational costs, particularly when extending generation to long videos. Recent work has explored autoregressive formulations for long video generation, typically by distilling from short-horizon bidirectional teachers. Nevertheless, given that teacher models cannot synthesize long videos, the extrapolation of student models beyond their training horizon often leads to pronounced quality degradation, arising from the compounding of errors within the continuous latent space. In this paper, we propose a simple yet effective approach to mitigate quality degradation in long-horizon video generation without requiring supervision from long-video teachers or retraining on long video datasets. Our approach centers on exploiting the rich knowledge of teacher models to provide guidance for the student model through sampled segments drawn from self-generated long videos. Our method maintains temporal consistency while scaling video length by up to 20x beyond teacher's capability, avoiding common issues such as over-exposure and error-accumulation without recomputing overlapping frames like previous methods. When scaling up the computation, our method shows the capability of generating videos up to 4 minutes and 15 seconds, equivalent to 99.9% of the maximum span supported by our base model's position embedding and more than 50x longer than that of our baseline model. Experiments on standard benchmarks and our proposed improved benchmark demonstrate that our approach substantially outperforms baseline methods in both fidelity and consistency. Our long-horizon videos demo can be found at https://self-forcing-plus-plus.github.io/
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


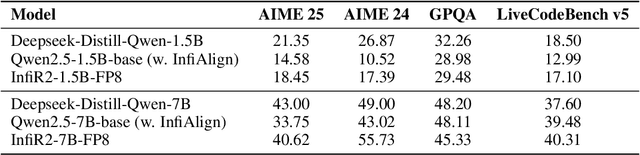
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
InfiAgent: Self-Evolving Pyramid Agent Framework for Infinite Scenarios
Sep 26, 2025
Large Language Model (LLM) agents have demonstrated remarkable capabilities in organizing and executing complex tasks, and many such agents are now widely used in various application scenarios. However, developing these agents requires carefully designed workflows, carefully crafted prompts, and iterative tuning, which requires LLM techniques and domain-specific expertise. These hand-crafted limitations hinder the scalability and cost-effectiveness of LLM agents across a wide range of industries. To address these challenges, we propose \textbf{InfiAgent}, a Pyramid-like DAG-based Multi-Agent Framework that can be applied to \textbf{infi}nite scenarios, which introduces several key innovations: a generalized "agent-as-a-tool" mechanism that automatically decomposes complex agents into hierarchical multi-agent systems; a dual-audit mechanism that ensures the quality and stability of task completion; an agent routing function that enables efficient task-agent matching; and an agent self-evolution mechanism that autonomously restructures the agent DAG based on new tasks, poor performance, or optimization opportunities. Furthermore, InfiAgent's atomic task design supports agent parallelism, significantly improving execution efficiency. This framework evolves into a versatile pyramid-like multi-agent system capable of solving a wide range of problems. Evaluations on multiple benchmarks demonstrate that InfiAgent achieves 9.9\% higher performance compared to ADAS (similar auto-generated agent framework), while a case study of the AI research assistant InfiHelper shows that it generates scientific papers that have received recognition from human reviewers at top-tier IEEE conferences.
CompSpoof: A Dataset and Joint Learning Framework for Component-Level Audio Anti-spoofing Countermeasures
Sep 19, 2025



Component-level audio Spoofing (Comp-Spoof) targets a new form of audio manipulation where only specific components of a signal, such as speech or environmental sound, are forged or substituted while other components remain genuine. Existing anti-spoofing datasets and methods treat an utterance or a segment as entirely bona fide or entirely spoofed, and thus cannot accurately detect component-level spoofing. To address this, we construct a new dataset, CompSpoof, covering multiple combinations of bona fide and spoofed speech and environmental sound. We further propose a separation-enhanced joint learning framework that separates audio components apart and applies anti-spoofing models to each one. Joint learning is employed, preserving information relevant for detection. Extensive experiments demonstrate that our method outperforms the baseline, highlighting the necessity of separate components and the importance of detecting spoofing for each component separately. Datasets and code are available at: https://github.com/XuepingZhang/CompSpoof.
Understanding the Thinking Process of Reasoning Models: A Perspective from Schoenfeld's Episode Theory
Sep 18, 2025While Large Reasoning Models (LRMs) generate extensive chain-of-thought reasoning, we lack a principled framework for understanding how these thoughts are structured. In this paper, we introduce a novel approach by applying Schoenfeld's Episode Theory, a classic cognitive framework for human mathematical problem-solving, to analyze the reasoning traces of LRMs. We annotated thousands of sentences and paragraphs from model-generated solutions to math problems using seven cognitive labels (e.g., Plan, Implement, Verify). The result is the first publicly available benchmark for the fine-grained analysis of machine reasoning, including a large annotated corpus and detailed annotation guidebooks. Our preliminary analysis reveals distinct patterns in LRM reasoning, such as the transition dynamics between cognitive states. This framework provides a theoretically grounded methodology for interpreting LRM cognition and enables future work on more controllable and transparent reasoning systems.
VSE-MOT: Multi-Object Tracking in Low-Quality Video Scenes Guided by Visual Semantic Enhancement
Sep 17, 2025Current multi-object tracking (MOT) algorithms typically overlook issues inherent in low-quality videos, leading to significant degradation in tracking performance when confronted with real-world image deterioration. Therefore, advancing the application of MOT algorithms in real-world low-quality video scenarios represents a critical and meaningful endeavor. To address the challenges posed by low-quality scenarios, inspired by vision-language models, this paper proposes a Visual Semantic Enhancement-guided Multi-Object Tracking framework (VSE-MOT). Specifically, we first design a tri-branch architecture that leverages a vision-language model to extract global visual semantic information from images and fuse it with query vectors. Subsequently, to further enhance the utilization of visual semantic information, we introduce the Multi-Object Tracking Adapter (MOT-Adapter) and the Visual Semantic Fusion Module (VSFM). The MOT-Adapter adapts the extracted global visual semantic information to suit multi-object tracking tasks, while the VSFM improves the efficacy of feature fusion. Through extensive experiments, we validate the effectiveness and superiority of the proposed method in real-world low-quality video scenarios. Its tracking performance metrics outperform those of existing methods by approximately 8% to 20%, while maintaining robust performance in conventional scenarios.