 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiCoEvalChain: A Blockchain-Based Decentralized Framework for Collaborative LLM Evaluation
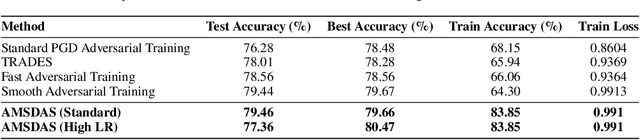
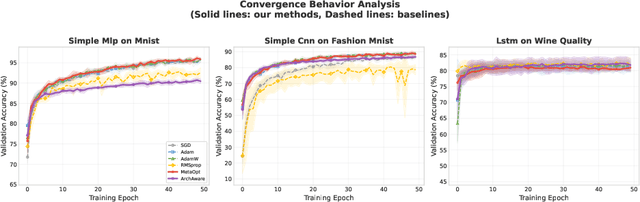
Feb 09, 2026The rapid advancement of large language models (LLMs) demands increasingly reliable evaluation, yet current centralized evaluation suffers from opacity, overfitting, and hardware-induced variance. Our empirical analysis reveals an alarming inconsistency in existing evaluations: the standard deviation across ten repeated runs of a single model on HumanEval (1.67) actually exceeds the performance gap among the top-10 models on the official leaderboard (0.91), rendering current rankings statistically precarious. To mitigate these instabilities, we propose a decentralized evaluation framework that enables hardware and parameter diversity through large-scale benchmarking across heterogeneous compute nodes. By leveraging the blockchain-based protocol, the framework incentivizes global contributors to act as independent validators, using a robust reward system to ensure evaluation integrity and discourage dishonest participation. This collective verification transforms evaluation from a "centralized black box" into a "decentralized endorsement" where multi-party consensus and diverse inference environments yield a more stable, representative metric. Experimental results demonstrate that the decentralized evaluation framework reduces the standard deviation across ten runs on the same model to 0.28. This significant improvement over conventional frameworks ensures higher statistical confidence in model rankings. We have completely implemented this platform and will soon release it to the community.
InfiAgent: Self-Evolving Pyramid Agent Framework for Infinite Scenarios
Sep 26, 2025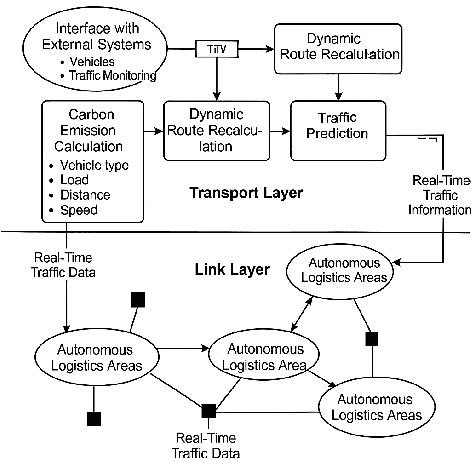
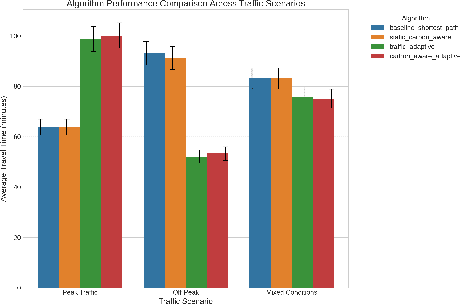
Large Language Model (LLM) agents have demonstrated remarkable capabilities in organizing and executing complex tasks, and many such agents are now widely used in various application scenarios. However, developing these agents requires carefully designed workflows, carefully crafted prompts, and iterative tuning, which requires LLM techniques and domain-specific expertise. These hand-crafted limitations hinder the scalability and cost-effectiveness of LLM agents across a wide range of industries. To address these challenges, we propose \textbf{InfiAgent}, a Pyramid-like DAG-based Multi-Agent Framework that can be applied to \textbf{infi}nite scenarios, which introduces several key innovations: a generalized "agent-as-a-tool" mechanism that automatically decomposes complex agents into hierarchical multi-agent systems; a dual-audit mechanism that ensures the quality and stability of task completion; an agent routing function that enables efficient task-agent matching; and an agent self-evolution mechanism that autonomously restructures the agent DAG based on new tasks, poor performance, or optimization opportunities. Furthermore, InfiAgent's atomic task design supports agent parallelism, significantly improving execution efficiency. This framework evolves into a versatile pyramid-like multi-agent system capable of solving a wide range of problems. Evaluations on multiple benchmarks demonstrate that InfiAgent achieves 9.9\% higher performance compared to ADAS (similar auto-generated agent framework), while a case study of the AI research assistant InfiHelper shows that it generates scientific papers that have received recognition from human reviewers at top-tier IEEE conferences.