 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynSFX: Multi-Model Sound Effects Synthesis Dataset for Deepfake Detection and Evaluation
Jul 06, 2026While audio deepfake detection has advanced significantly, representative detectors show limited generalization to synthetic sound effects. Existing environmental audio datasets such as EnvSDD provide important initial resources, but remain limited in scale and generation provenance for studying isolated sound-effect deepfakes. To support this direction, we present SynSFX, a large-scale corpus of 43374 clips (26452 synthetic, 16922 real) spanning 7 popular text-to-audio models.
CompSpoof: A Dataset and Joint Learning Framework for Component-Level Audio Anti-spoofing Countermeasures
Sep 19, 2025



Component-level audio Spoofing (Comp-Spoof) targets a new form of audio manipulation where only specific components of a signal, such as speech or environmental sound, are forged or substituted while other components remain genuine. Existing anti-spoofing datasets and methods treat an utterance or a segment as entirely bona fide or entirely spoofed, and thus cannot accurately detect component-level spoofing. To address this, we construct a new dataset, CompSpoof, covering multiple combinations of bona fide and spoofed speech and environmental sound. We further propose a separation-enhanced joint learning framework that separates audio components apart and applies anti-spoofing models to each one. Joint learning is employed, preserving information relevant for detection. Extensive experiments demonstrate that our method outperforms the baseline, highlighting the necessity of separate components and the importance of detecting spoofing for each component separately. Datasets and code are available at: https://github.com/XuepingZhang/CompSpoof.
The DKU System Description for The Interspeech 2021 Auto-KWS Challenge
Apr 11, 2021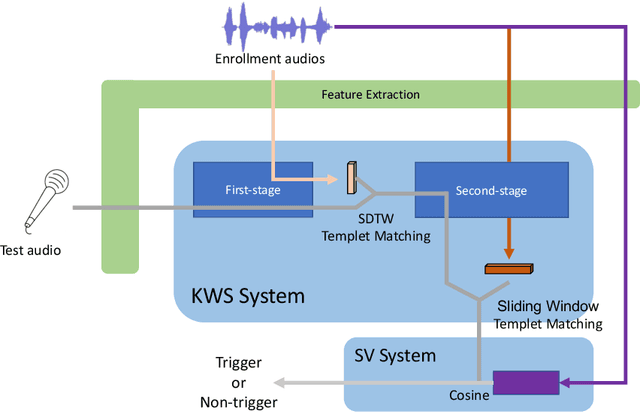
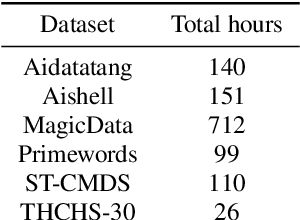
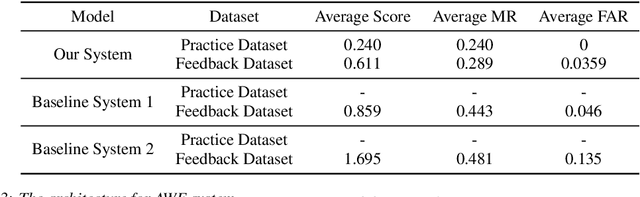
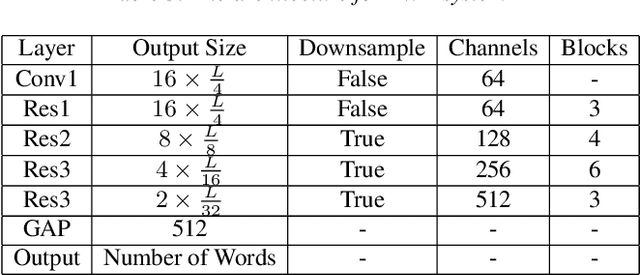
This paper introduces the system submitted by the DKU-SMIIP team for the Auto-KWS 2021 Challenge. Our implementation consists of a two-stage keyword spotting system based on query-by-example spoken term detection and a speaker verification system. We employ two different detection algorithms in our proposed keyword spotting system. The first stage adopts subsequence dynamic time warping for template matching based on frame-level language-independent bottleneck feature and phoneme posterior probability. We use a sliding window template matching algorithm based on acoustic word embeddings to further verify the detection from the first stage. As a result, our KWS system achieves an average score of 0.61 on the feedback dataset, which outperforms the baseline1 system by 0.25.