 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiAgent: An Infinite-Horizon Framework for General-Purpose Autonomous Agents
Jan 06, 2026LLM agents can reason and use tools, but they often break down on long-horizon tasks due to unbounded context growth and accumulated errors. Common remedies such as context compression or retrieval-augmented prompting introduce trade-offs between information fidelity and reasoning stability. We present InfiAgent, a general-purpose framework that keeps the agent's reasoning context strictly bounded regardless of task duration by externalizing persistent state into a file-centric state abstraction. At each step, the agent reconstructs context from a workspace state snapshot plus a fixed window of recent actions. Experiments on DeepResearch and an 80-paper literature review task show that, without task-specific fine-tuning, InfiAgent with a 20B open-source model is competitive with larger proprietary systems and maintains substantially higher long-horizon coverage than context-centric baselines. These results support explicit state externalization as a practical foundation for stable long-horizon agents. Github Repo:https://github.com/ChenglinPoly/infiAgent
InfiAgent: Self-Evolving Pyramid Agent Framework for Infinite Scenarios
Sep 26, 2025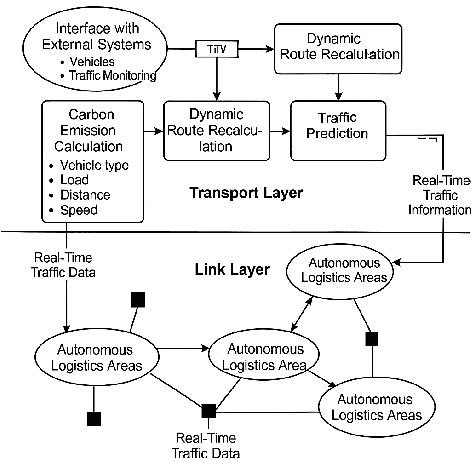
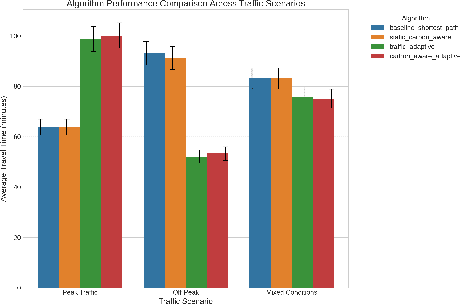
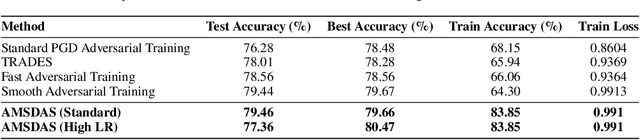
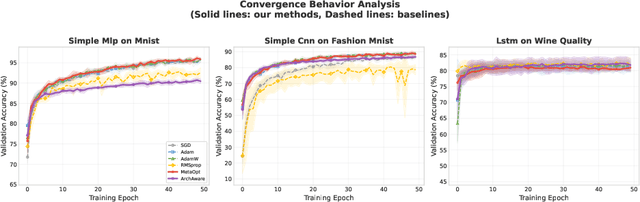
Large Language Model (LLM) agents have demonstrated remarkable capabilities in organizing and executing complex tasks, and many such agents are now widely used in various application scenarios. However, developing these agents requires carefully designed workflows, carefully crafted prompts, and iterative tuning, which requires LLM techniques and domain-specific expertise. These hand-crafted limitations hinder the scalability and cost-effectiveness of LLM agents across a wide range of industries. To address these challenges, we propose \textbf{InfiAgent}, a Pyramid-like DAG-based Multi-Agent Framework that can be applied to \textbf{infi}nite scenarios, which introduces several key innovations: a generalized "agent-as-a-tool" mechanism that automatically decomposes complex agents into hierarchical multi-agent systems; a dual-audit mechanism that ensures the quality and stability of task completion; an agent routing function that enables efficient task-agent matching; and an agent self-evolution mechanism that autonomously restructures the agent DAG based on new tasks, poor performance, or optimization opportunities. Furthermore, InfiAgent's atomic task design supports agent parallelism, significantly improving execution efficiency. This framework evolves into a versatile pyramid-like multi-agent system capable of solving a wide range of problems. Evaluations on multiple benchmarks demonstrate that InfiAgent achieves 9.9\% higher performance compared to ADAS (similar auto-generated agent framework), while a case study of the AI research assistant InfiHelper shows that it generates scientific papers that have received recognition from human reviewers at top-tier IEEE conferences.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
Panoramic Human Activity Recognition
Mar 08, 2022
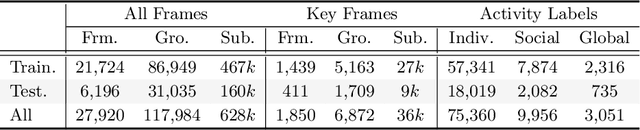
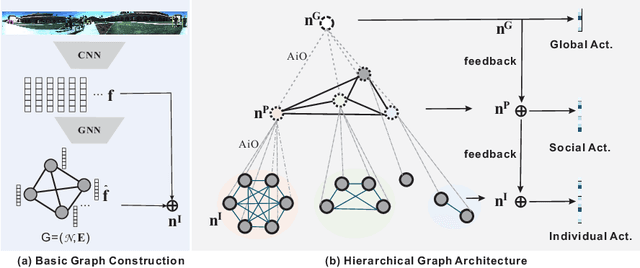
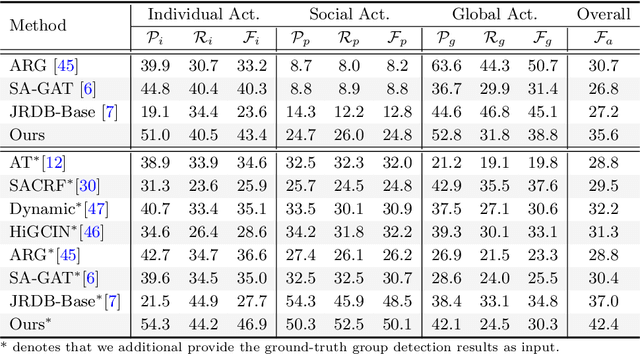
To obtain a more comprehensive activity understanding for a crowded scene, in this paper, we propose a new problem of panoramic human activity recognition (PAR), which aims to simultaneous achieve the individual action, social group activity, and global activity recognition. This is a challenging yet practical problem in real-world applications. For this problem, we develop a novel hierarchical graph neural network to progressively represent and model the multi-granularity human activities and mutual social relations for a crowd of people. We further build a benchmark to evaluate the proposed method and other existing related methods. Experimental results verify the rationality of the proposed PAR problem, the effectiveness of our method and the usefulness of the benchmark. We will release the source code and benchmark to the public for promoting the study on this problem.