 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025



Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
Jun 11, 2025Large Language Models (LLMs) are now integral across various domains and have demonstrated impressive performance. Progress, however, rests on the premise that benchmark scores are both accurate and reproducible. We demonstrate that the reproducibility of LLM performance is fragile: changing system configuration such as evaluation batch size, GPU count, and GPU version can introduce significant difference in the generated responses. This issue is especially pronounced in reasoning models, where minor rounding differences in early tokens can cascade into divergent chains of thought, ultimately affecting accuracy. For instance, under bfloat16 precision with greedy decoding, a reasoning model like DeepSeek-R1-Distill-Qwen-7B can exhibit up to 9% variation in accuracy and 9,000 tokens difference in response length due to differences in GPU count, type, and evaluation batch size. We trace the root cause of this variability to the non-associative nature of floating-point arithmetic under limited numerical precision. This work presents the first systematic investigation into how numerical precision affects reproducibility in LLM inference. Through carefully controlled experiments across various hardware, software, and precision settings, we quantify when and how model outputs diverge. Our analysis reveals that floating-point precision -- while critical for reproducibility -- is often neglected in evaluation practices. Inspired by this, we develop a lightweight inference pipeline, dubbed LayerCast, that stores weights in 16-bit precision but performs all computations in FP32, balancing memory efficiency with numerical stability. Code is available at https://github.com/nanomaoli/llm_reproducibility.
FuXi-Air: Urban Air Quality Forecasting Based on Emission-Meteorology-Pollutant multimodal Machine Learning
Jun 09, 2025Air pollution has emerged as a major public health challenge in megacities. Numerical simulations and single-site machine learning approaches have been widely applied in air quality forecasting tasks. However, these methods face multiple limitations, including high computational costs, low operational efficiency, and limited integration with observational data. With the rapid advancement of artificial intelligence, there is an urgent need to develop a low-cost, efficient air quality forecasting model for smart urban management. An air quality forecasting model, named FuXi-Air, has been constructed in this study based on multimodal data fusion to support high-precision air quality forecasting and operated in typical megacities. The model integrates meteorological forecasts, emission inventories, and pollutant monitoring data under the guidance of air pollution mechanism. By combining an autoregressive prediction framework with a frame interpolation strategy, the model successfully completes 72-hour forecasts for six major air pollutants at an hourly resolution across multiple monitoring sites within 25-30 seconds. In terms of both computational efficiency and forecasting accuracy, it outperforms the mainstream numerical air quality models in operational forecasting work. Ablation experiments concerning key influencing factors show that although meteorological data contribute more to model accuracy than emission inventories do, the integration of multimodal data significantly improves forecasting precision and ensures that reliable predictions are obtained under differing pollution mechanisms across megacities. This study provides both a technical reference and a practical example for applying multimodal data-driven models to air quality forecasting and offers new insights into building hybrid forecasting systems to support air pollution risk warning in smart city management.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025



A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
Serendipitous Recommendation with Multimodal LLM
Jun 09, 2025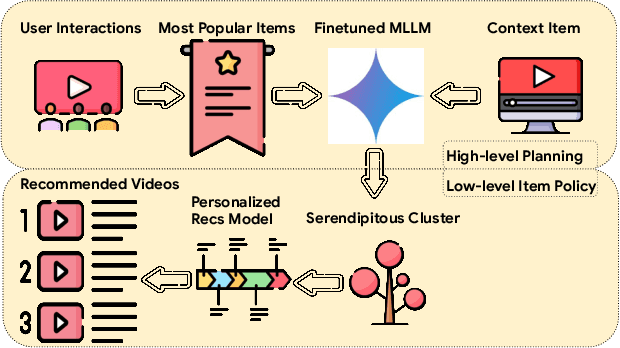
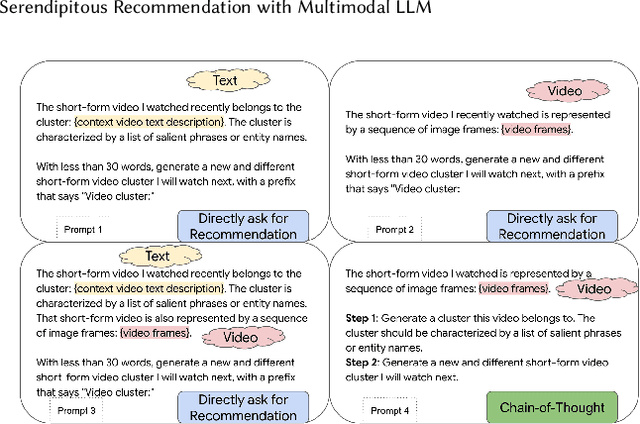
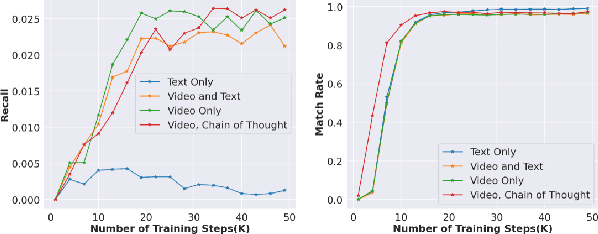
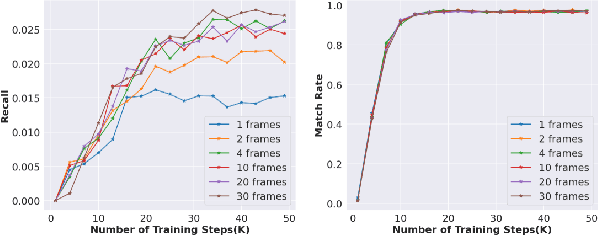
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
Jun 08, 2025

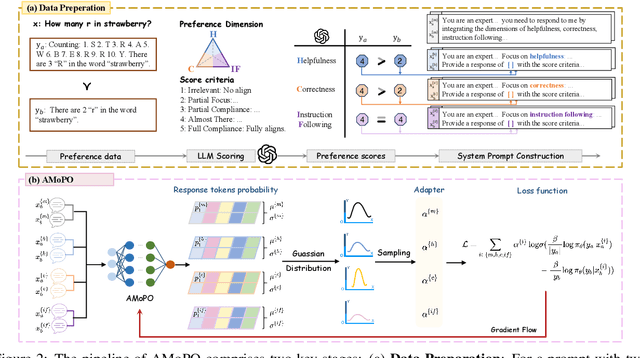
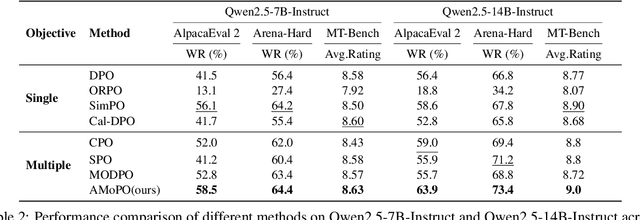
Existing multi-objective preference alignment methods for large language models (LLMs) face limitations: (1) the inability to effectively balance various preference dimensions, and (2) reliance on auxiliary reward/reference models introduces computational complexity. To address these challenges, we propose Adaptive Multi-objective Preference Optimization (AMoPO), a novel framework that achieves dynamic balance across preference dimensions. By introducing the multi-objective optimization paradigm to use the dimension-aware generation metrics as implicit rewards, AMoPO aligns LLMs with diverse preferences without additional reward models or reference models. We introduce an adaptive weight assignment mechanism that models the generation space as a Gaussian distribution, allowing dynamic prioritization of preference dimensions. Empirical results demonstrate that AMoPO outperforms state-of-the-art baselines by 28.5%, and the experiments on 7B, 14B, and 32B models reveal the scaling ability of AMoPO. Moreover, additional analysis of multiple dimensions verifies its adaptability and effectiveness. These findings validate AMoPO's capability to achieve dimension-aware preference alignment, highlighting its superiority. Our codes and datasets are available at https://github.com/Javkonline/AMoPO.
Hi-VAE: Efficient Video Autoencoding with Global and Detailed Motion
Jun 08, 2025Recent breakthroughs in video autoencoders (Video AEs) have advanced video generation, but existing methods fail to efficiently model spatio-temporal redundancies in dynamics, resulting in suboptimal compression factors. This shortfall leads to excessive training costs for downstream tasks. To address this, we introduce Hi-VAE, an efficient video autoencoding framework that hierarchically encode coarse-to-fine motion representations of video dynamics and formulate the decoding process as a conditional generation task. Specifically, Hi-VAE decomposes video dynamics into two latent spaces: Global Motion, capturing overarching motion patterns, and Detailed Motion, encoding high-frequency spatial details. Using separate self-supervised motion encoders, we compress video latents into compact motion representations to reduce redundancy significantly. A conditional diffusion decoder then reconstructs videos by combining hierarchical global and detailed motions, enabling high-fidelity video reconstructions. Extensive experiments demonstrate that Hi-VAE achieves a high compression factor of 1428$\times$, almost 30$\times$ higher than baseline methods (e.g., Cosmos-VAE at 48$\times$), validating the efficiency of our approach. Meanwhile, Hi-VAE maintains high reconstruction quality at such high compression rates and performs effectively in downstream generative tasks. Moreover, Hi-VAE exhibits interpretability and scalability, providing new perspectives for future exploration in video latent representation and generation.
Stepwise Decomposition and Dual-stream Focus: A Novel Approach for Training-free Camouflaged Object Segmentation
Jun 07, 2025



While promptable segmentation (\textit{e.g.}, SAM) has shown promise for various segmentation tasks, it still requires manual visual prompts for each object to be segmented. In contrast, task-generic promptable segmentation aims to reduce the need for such detailed prompts by employing only a task-generic prompt to guide segmentation across all test samples. However, when applied to Camouflaged Object Segmentation (COS), current methods still face two critical issues: 1) \textit{\textbf{semantic ambiguity in getting instance-specific text prompts}}, which arises from insufficient discriminative cues in holistic captions, leading to foreground-background confusion; 2) \textit{\textbf{semantic discrepancy combined with spatial separation in getting instance-specific visual prompts}}, which results from global background sampling far from object boundaries with low feature correlation, causing SAM to segment irrelevant regions. To address the issues above, we propose \textbf{RDVP-MSD}, a novel training-free test-time adaptation framework that synergizes \textbf{R}egion-constrained \textbf{D}ual-stream \textbf{V}isual \textbf{P}rompting (RDVP) via \textbf{M}ultimodal \textbf{S}tepwise \textbf{D}ecomposition Chain of Thought (MSD-CoT). MSD-CoT progressively disentangles image captions to eliminate semantic ambiguity, while RDVP injects spatial constraints into visual prompting and independently samples visual prompts for foreground and background points, effectively mitigating semantic discrepancy and spatial separation. Without requiring any training or supervision, RDVP-MSD achieves a state-of-the-art segmentation result on multiple COS benchmarks and delivers a faster inference speed than previous methods, demonstrating significantly improved accuracy and efficiency. The codes will be available at \href{https://github.com/ycyinchao/RDVP-MSD}{https://github.com/ycyinchao/RDVP-MSD}
ChronoTailor: Harnessing Attention Guidance for Fine-Grained Video Virtual Try-On
Jun 06, 2025Video virtual try-on aims to seamlessly replace the clothing of a person in a source video with a target garment. Despite significant progress in this field, existing approaches still struggle to maintain continuity and reproduce garment details. In this paper, we introduce ChronoTailor, a diffusion-based framework that generates temporally consistent videos while preserving fine-grained garment details. By employing a precise spatio-temporal attention mechanism to guide the integration of fine-grained garment features, ChronoTailor achieves robust try-on performance. First, ChronoTailor leverages region-aware spatial guidance to steer the evolution of spatial attention and employs an attention-driven temporal feature fusion mechanism to generate more continuous temporal features. This dual approach not only enables fine-grained local editing but also effectively mitigates artifacts arising from video dynamics. Second, ChronoTailor integrates multi-scale garment features to preserve low-level visual details and incorporates a garment-pose feature alignment to ensure temporal continuity during dynamic motion. Additionally, we collect StyleDress, a new dataset featuring intricate garments, varied environments, and diverse poses, offering advantages over existing public datasets, and will be publicly available for research. Extensive experiments show that ChronoTailor maintains spatio-temporal continuity and preserves garment details during motion, significantly outperforming previous methods.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025
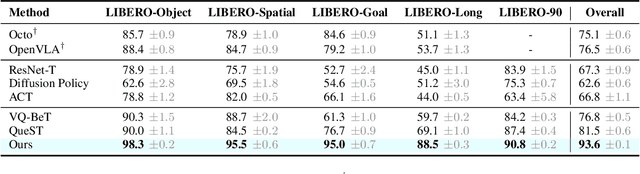
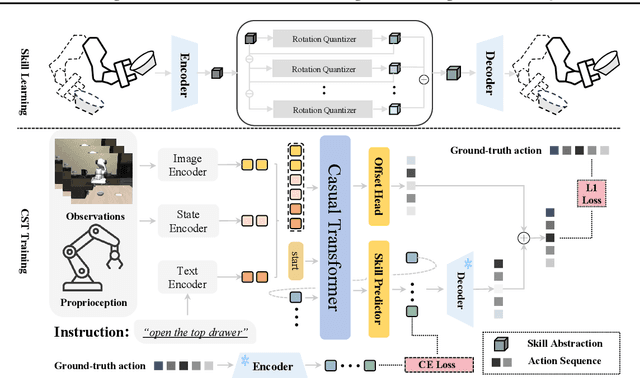

Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight