 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoner for Real-World Event Detection: Scaling Reinforcement Learning via Adaptive Perplexity-Aware Sampling Strategy
Jul 02, 2025



Detecting abnormal events in real-world customer service dialogues is highly challenging due to the complexity of business data and the dynamic nature of customer interactions. Moreover, models must demonstrate strong out-of-domain (OOD) generalization to enable rapid adaptation across different business scenarios and maximize commercial value. In this work, we propose a novel Adaptive Perplexity-Aware Reinforcement Learning (APARL) framework that leverages the advanced reasoning capabilities of large language models for abnormal event detection. APARL introduces a dual-loop dynamic curriculum learning architecture, enabling the model to progressively focus on more challenging samples as its proficiency increases. This design effectively addresses performance bottlenecks and significantly enhances OOD transferability. Extensive evaluations on food delivery dialogue tasks show that our model achieves significantly enhanced adaptability and robustness, attaining the highest F1 score with an average improvement of 17.19\%, and an average improvement of 9.59\% in OOD transfer tests. This method provides a superior solution for industrial deployment of anomaly detection models, contributing to improved operational efficiency and commercial benefits.
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
Jun 08, 2025

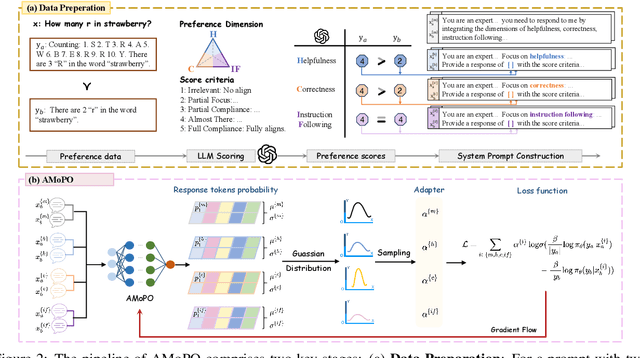
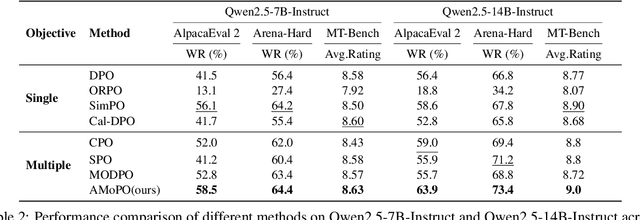
Existing multi-objective preference alignment methods for large language models (LLMs) face limitations: (1) the inability to effectively balance various preference dimensions, and (2) reliance on auxiliary reward/reference models introduces computational complexity. To address these challenges, we propose Adaptive Multi-objective Preference Optimization (AMoPO), a novel framework that achieves dynamic balance across preference dimensions. By introducing the multi-objective optimization paradigm to use the dimension-aware generation metrics as implicit rewards, AMoPO aligns LLMs with diverse preferences without additional reward models or reference models. We introduce an adaptive weight assignment mechanism that models the generation space as a Gaussian distribution, allowing dynamic prioritization of preference dimensions. Empirical results demonstrate that AMoPO outperforms state-of-the-art baselines by 28.5%, and the experiments on 7B, 14B, and 32B models reveal the scaling ability of AMoPO. Moreover, additional analysis of multiple dimensions verifies its adaptability and effectiveness. These findings validate AMoPO's capability to achieve dimension-aware preference alignment, highlighting its superiority. Our codes and datasets are available at https://github.com/Javkonline/AMoPO.
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023



As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
Confidence Calibration for Intent Detection via Hyperspherical Space and Rebalanced Accuracy-Uncertainty Loss
Mar 17, 2022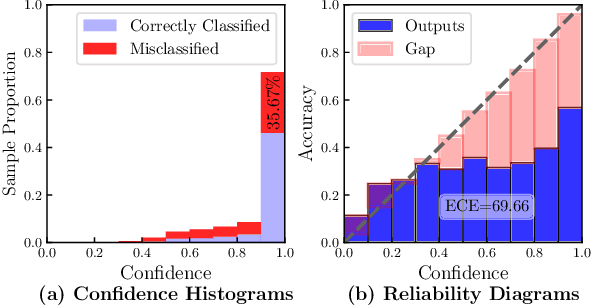
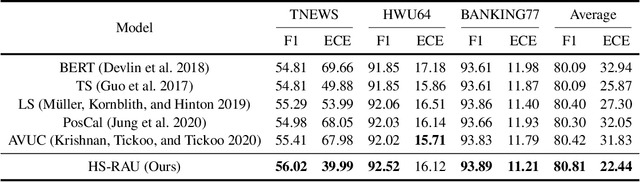
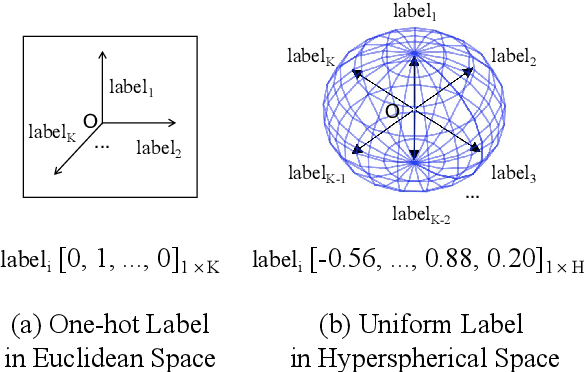
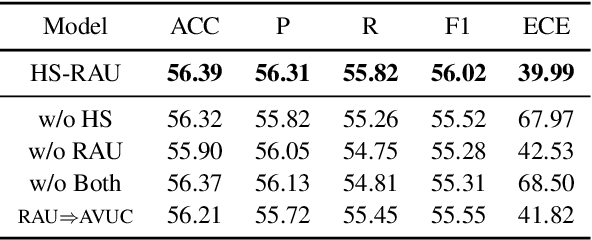
Data-driven methods have achieved notable performance on intent detection, which is a task to comprehend user queries. Nonetheless, they are controversial for over-confident predictions. In some scenarios, users do not only care about the accuracy but also the confidence of model. Unfortunately, mainstream neural networks are poorly calibrated, with a large gap between accuracy and confidence. To handle this problem defined as confidence calibration, we propose a model using the hyperspherical space and rebalanced accuracy-uncertainty loss. Specifically, we project the label vector onto hyperspherical space uniformly to generate a dense label representation matrix, which mitigates over-confident predictions due to overfitting sparce one-hot label matrix. Besides, we rebalance samples of different accuracy and uncertainty to better guide model training. Experiments on the open datasets verify that our model outperforms the existing calibration methods and achieves a significant improvement on the calibration metric.
Density-Based Dynamic Curriculum Learning for Intent Detection
Aug 24, 2021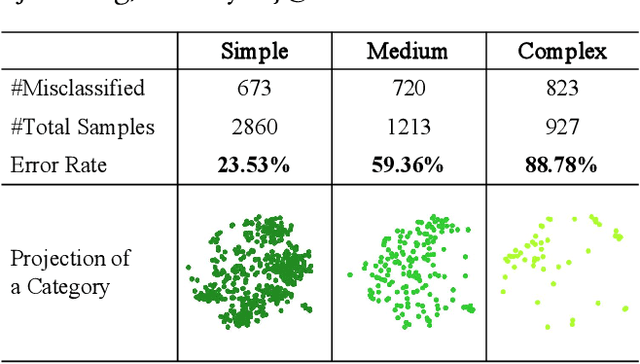

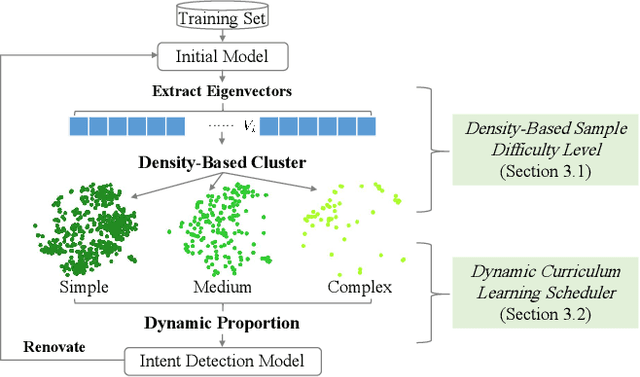
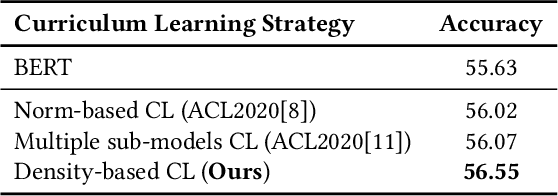
Pre-trained language models have achieved noticeable performance on the intent detection task. However, due to assigning an identical weight to each sample, they suffer from the overfitting of simple samples and the failure to learn complex samples well. To handle this problem, we propose a density-based dynamic curriculum learning model. Our model defines the sample's difficulty level according to their eigenvectors' density. In this way, we exploit the overall distribution of all samples' eigenvectors simultaneously. Then we apply a dynamic curriculum learning strategy, which pays distinct attention to samples of various difficulty levels and alters the proportion of samples during the training process. Through the above operation, simple samples are well-trained, and complex samples are enhanced. Experiments on three open datasets verify that the proposed density-based algorithm can distinguish simple and complex samples significantly. Besides, our model obtains obvious improvement over the strong baselines.
From Paraphrasing to Semantic Parsing: Unsupervised Semantic Parsing via Synchronous Semantic Decoding
Jun 11, 2021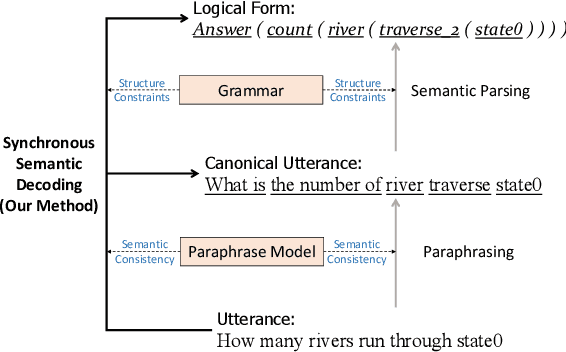
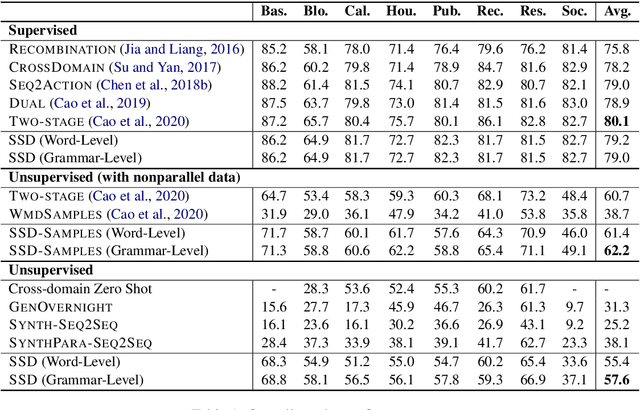
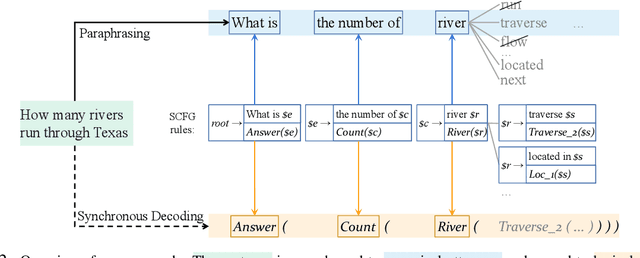
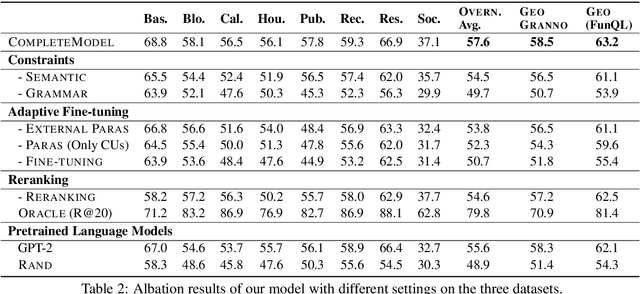
Semantic parsing is challenging due to the structure gap and the semantic gap between utterances and logical forms. In this paper, we propose an unsupervised semantic parsing method - Synchronous Semantic Decoding (SSD), which can simultaneously resolve the semantic gap and the structure gap by jointly leveraging paraphrasing and grammar constrained decoding. Specifically, we reformulate semantic parsing as a constrained paraphrasing problem: given an utterance, our model synchronously generates its canonical utterance and meaning representation. During synchronous decoding: the utterance paraphrasing is constrained by the structure of the logical form, therefore the canonical utterance can be paraphrased controlledly; the semantic decoding is guided by the semantics of the canonical utterance, therefore its logical form can be generated unsupervisedly. Experimental results show that SSD is a promising approach and can achieve competitive unsupervised semantic parsing performance on multiple datasets.