 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerendipitous Recommendation with Multimodal LLM
Jun 09, 2025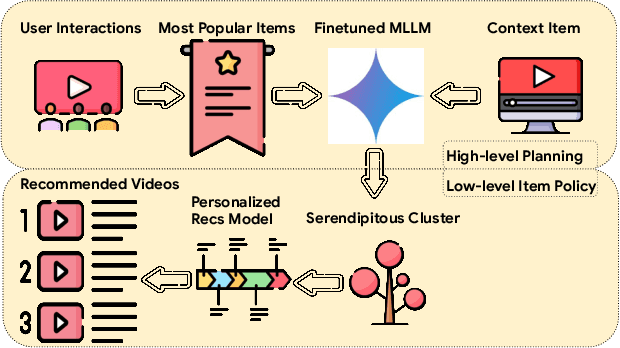
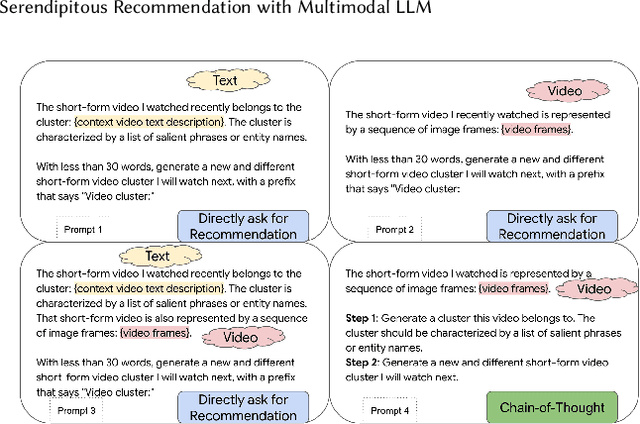
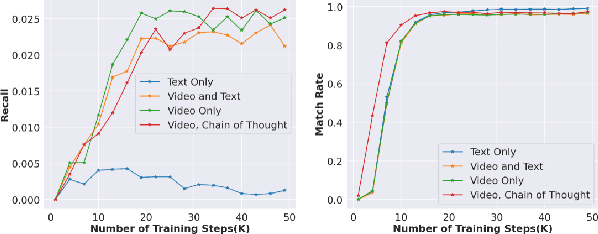
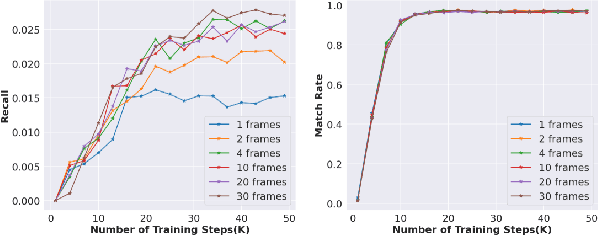
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
Conversational Planning for Personal Plans
Feb 26, 2025


The language generation and reasoning capabilities of large language models (LLMs) have enabled conversational systems with impressive performance in a variety of tasks, from code generation, to composing essays, to passing STEM and legal exams, to a new paradigm for knowledge search. Besides those short-term use applications, LLMs are increasingly used to help with real-life goals or tasks that take a long time to complete, involving multiple sessions across days, weeks, months, or even years. Thus to enable conversational systems for long term interactions and tasks, we need language-based agents that can plan for long horizons. Traditionally, such capabilities were addressed by reinforcement learning agents with hierarchical planning capabilities. In this work, we explore a novel architecture where the LLM acts as the meta-controller deciding the agent's next macro-action, and tool use augmented LLM-based option policies execute the selected macro-action. We instantiate this framework for a specific set of macro-actions enabling adaptive planning for users' personal plans through conversation and follow-up questions collecting user feedback. We show how this paradigm can be applicable in scenarios ranging from tutoring for academic and non-academic tasks to conversational coaching for personal health plans.
The Blessing of Reasoning: LLM-Based Contrastive Explanations in Black-Box Recommender Systems
Feb 24, 2025



Modern recommender systems use ML models to predict consumer preferences from consumption history. Although these "black-box" models achieve impressive predictive performance, they often suffer from a lack of transparency and explainability. Contrary to the presumed tradeoff between explainability and accuracy, we show that integrating large language models (LLMs) with deep neural networks (DNNs) can improve both. We propose LR-Recsys, which augments DNN-based systems with LLM reasoning capabilities. LR-Recsys introduces a contrastive-explanation generator that produces human-readable positive explanations and negative explanations. These explanations are embedded via a fine-tuned autoencoder and combined with consumer and product features to improve predictions. Beyond offering explainability, we show that LR-Recsys also improves learning efficiency and predictive accuracy, as supported by high-dimensional, multi-environment statistical learning theory. LR-Recsys outperforms state-of-the-art recommender systems by 3-14% on three real-world datasets. Importantly, our analysis reveals that these gains primarily derive from LLMs' reasoning capabilities rather than their external domain knowledge. LR-RecSys presents an effective approach to combine LLMs with traditional DNNs, two of the most widely used ML models today. The explanations generated by LR-Recsys provide actionable insights for consumers, sellers, and platforms, helping to build trust, optimize product offerings, and inform targeting strategies.
EVOLvE: Evaluating and Optimizing LLMs For Exploration
Oct 08, 2024



Despite their success in many domains, large language models (LLMs) remain under-studied in scenarios requiring optimal decision-making under uncertainty. This is crucial as many real-world applications, ranging from personalized recommendations to healthcare interventions, demand that LLMs not only predict but also actively learn to make optimal decisions through exploration. In this work, we measure LLMs' (in)ability to make optimal decisions in bandits, a state-less reinforcement learning setting relevant to many applications. We develop a comprehensive suite of environments, including both context-free and contextual bandits with varying task difficulties, to benchmark LLMs' performance. Motivated by the existence of optimal exploration algorithms, we propose efficient ways to integrate this algorithmic knowledge into LLMs: by providing explicit algorithm-guided support during inference; and through algorithm distillation via in-context demonstrations and fine-tuning, using synthetic data generated from these algorithms. Impressively, these techniques allow us to achieve superior exploration performance with smaller models, surpassing larger models on various tasks. We conducted an extensive ablation study to shed light on various factors, such as task difficulty and data representation, that influence the efficiency of LLM exploration. Additionally, we conduct a rigorous analysis of the LLM's exploration efficiency using the concept of regret, linking its ability to explore to the model size and underlying algorithm.
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024



Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Diversifying by Intent in Recommender Systems
May 20, 2024It has become increasingly clear that recommender systems overly focusing on short-term engagement can inadvertently hurt long-term user experience. However, it is challenging to optimize long-term user experience directly as the desired signal is sparse, noisy and manifests over a long horizon. In this work, we show the benefits of incorporating higher-level user understanding, specifically user intents that can persist across multiple interactions or recommendation sessions, for whole-page recommendation toward optimizing long-term user experience. User intent has primarily been investigated within the context of search, but remains largely under-explored for recommender systems. To bridge this gap, we develop a probabilistic intent-based whole-page diversification framework in the final stage of a recommender system. Starting with a prior belief of user intents, the proposed diversification framework sequentially selects items at each position based on these beliefs, and subsequently updates posterior beliefs about the intents. It ensures that different user intents are represented in a page towards optimizing long-term user experience. We experiment with the intent diversification framework on one of the world's largest content recommendation platforms, serving billions of users daily. Our framework incorporates the user's exploration intent, capturing their propensity to explore new interests and content. Live experiments show that the proposed framework leads to an increase in user retention and overall user enjoyment, validating its effectiveness in facilitating long-term planning. In particular, it enables users to consistently discover and engage with diverse contents that align with their underlying intents over time, thereby leading to an improved long-term user experience.
Large Language Models as Data Augmenters for Cold-Start Item Recommendation
Feb 18, 2024


The reasoning and generalization capabilities of LLMs can help us better understand user preferences and item characteristics, offering exciting prospects to enhance recommendation systems. Though effective while user-item interactions are abundant, conventional recommendation systems struggle to recommend cold-start items without historical interactions. To address this, we propose utilizing LLMs as data augmenters to bridge the knowledge gap on cold-start items during training. We employ LLMs to infer user preferences for cold-start items based on textual description of user historical behaviors and new item descriptions. The augmented training signals are then incorporated into learning the downstream recommendation models through an auxiliary pairwise loss. Through experiments on public Amazon datasets, we demonstrate that LLMs can effectively augment the training signals for cold-start items, leading to significant improvements in cold-start item recommendation for various recommendation models.
Correction with Backtracking Reduces Hallucination in Summarization
Oct 31, 2023



Abstractive summarization aims at generating natural language summaries of a source document that are succinct while preserving the important elements. Despite recent advances, neural text summarization models are known to be susceptible to hallucinating (or more correctly confabulating), that is to produce summaries with details that are not grounded in the source document. In this paper, we introduce a simple yet efficient technique, CoBa, to reduce hallucination in abstractive summarization. The approach is based on two steps: hallucination detection and mitigation. We show that the former can be achieved through measuring simple statistics about conditional word probabilities and distance to context words. Further, we demonstrate that straight-forward backtracking is surprisingly effective at mitigation. We thoroughly evaluate the proposed method with prior art on three benchmark datasets for text summarization. The results show that CoBa is effective and efficient in reducing hallucination, and offers great adaptability and flexibility.