 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileDreamer: Generative Sketch World Model for GUI Agent
Jan 07, 2026Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
Jun 08, 2025

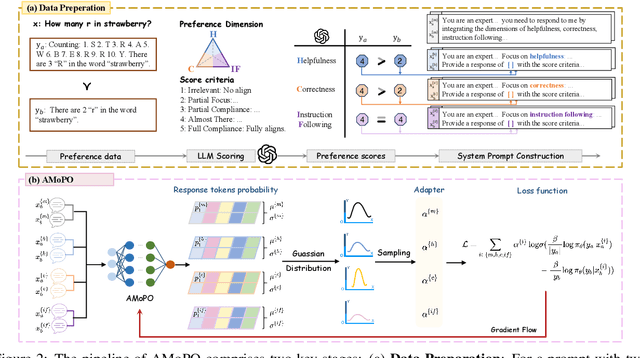
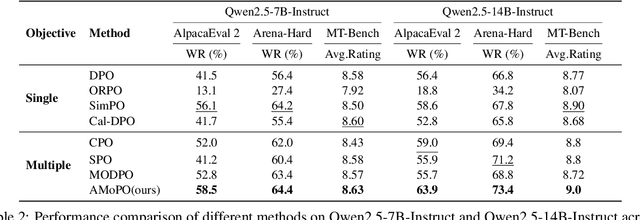
Existing multi-objective preference alignment methods for large language models (LLMs) face limitations: (1) the inability to effectively balance various preference dimensions, and (2) reliance on auxiliary reward/reference models introduces computational complexity. To address these challenges, we propose Adaptive Multi-objective Preference Optimization (AMoPO), a novel framework that achieves dynamic balance across preference dimensions. By introducing the multi-objective optimization paradigm to use the dimension-aware generation metrics as implicit rewards, AMoPO aligns LLMs with diverse preferences without additional reward models or reference models. We introduce an adaptive weight assignment mechanism that models the generation space as a Gaussian distribution, allowing dynamic prioritization of preference dimensions. Empirical results demonstrate that AMoPO outperforms state-of-the-art baselines by 28.5%, and the experiments on 7B, 14B, and 32B models reveal the scaling ability of AMoPO. Moreover, additional analysis of multiple dimensions verifies its adaptability and effectiveness. These findings validate AMoPO's capability to achieve dimension-aware preference alignment, highlighting its superiority. Our codes and datasets are available at https://github.com/Javkonline/AMoPO.