 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented LLM-based Multi-Agent System for Automated Feature Generation on Tabular Data
Apr 22, 2026Automated feature generation extracts informative features from raw tabular data without manual intervention and is crucial for accurate, generalizable machine learning. Traditional methods rely on predefined operator libraries and cannot leverage task semantics, limiting their ability to produce diverse, high-value features for complex tasks. Recent Large Language Model (LLM)-based approaches introduce richer semantic signals, but still suffer from a restricted feature space due to fixed generation patterns and from the absence of feedback from the learning objective. To address these challenges, we propose a Memory-Augmented LLM-based Multi-Agent System (\textbf{MALMAS}) for automated feature generation. MALMAS decomposes the generation process into agents with distinct responsibilities, and a Router Agent activates an appropriate subset of agents per iteration, further broadening exploration of the feature space. We further integrate a memory module comprising procedural memory, feedback memory, and conceptual memory, enabling iterative refinement that adaptively guides subsequent feature generation and improves feature quality and diversity. Extensive experiments on multiple public datasets against state-of-the-art baselines demonstrate the effectiveness of our approach. The code is available at https://github.com/fxdong24/MALMAS
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Apr 12, 2026On-policy reinforcement learning has become the dominant paradigm for reasoning alignment in large language models, yet its sparse, outcome-level rewards make token-level credit assignment notoriously difficult. On-Policy Distillation (OPD) alleviates this by introducing dense, token-level KL supervision from a teacher model, but typically applies this supervision uniformly across all rollouts, ignoring fundamental differences in signal quality. We propose Signal-Calibrated On-Policy Distillation Enhancement (SCOPE), a dual-path adaptive training framework that routes on-policy rollouts by correctness into two complementary supervision paths. For incorrect trajectories, SCOPE performs teacher-perplexity-weighted KL distillation to prioritize instances where the teacher demonstrates genuine corrective capability, while down-weighting unreliable guidance. For correct trajectories, it applies student-perplexity-weighted MLE to concentrate reinforcement on low-confidence samples at the capability boundary rather than over-reinforcing already mastered ones. Both paths employ a group-level normalization to adaptively calibrate weight distributions, accounting for the intrinsic difficulty variance across prompts. Extensive experiments on six reasoning benchmarks show that SCOPE achieves an average relative improvement of 11.42% in Avg@32 and 7.30% in Pass@32 over competitive baselines, demonstrating its consistent effectiveness.
TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
Mar 17, 2026Text-to-SQL parsing has achieved remarkable progress under the Full Schema Assumption. However, this premise fails in real-world enterprise environments where databases contain hundreds of tables with massive noisy metadata. Rather than injecting the full schema upfront, an agent must actively identify and verify only the relevant subset, giving rise to the Unknown Schema scenario we study in this work. To address this, we propose TRUST-SQL (Truthful Reasoning with Unknown Schema via Tools). We formulate the task as a Partially Observable Markov Decision Process where our autonomous agent employs a structured four-phase protocol to ground reasoning in verified metadata. Crucially, this protocol provides a structural boundary for our novel Dual-Track GRPO strategy. By applying token-level masked advantages, this strategy isolates exploration rewards from execution outcomes to resolve credit assignment, yielding a 9.9% relative improvement over standard GRPO. Extensive experiments across five benchmarks demonstrate that TRUST-SQL achieves an average absolute improvement of 30.6% and 16.6% for the 4B and 8B variants respectively over their base models. Remarkably, despite operating entirely without pre-loaded metadata, our framework consistently matches or surpasses strong baselines that rely on schema prefilling.
Harmonizing Dense and Sparse Signals in Multi-turn RL: Dual-Horizon Credit Assignment for Industrial Sales Agents
Mar 02, 2026Optimizing large language models for industrial sales requires balancing long-term commercial objectives (e.g., conversion rate) with immediate linguistic constraints such as fluency and compliance. Conventional reinforcement learning often merges these heterogeneous goals into a single reward, causing high-magnitude session-level rewards to overwhelm subtler turn-level signals, which leads to unstable training or reward hacking. To address this issue, we propose Dual-Horizon Credit Assignment (DuCA), a framework that disentangles optimization across time scales. Its core, Horizon-Independent Advantage Normalization (HIAN), separately normalizes advantages from turn-level and session-level rewards before fusion, ensuring balanced gradient contributions from both immediate and long-term objectives to the policy update. Extensive experiments with a high-fidelity user simulator show DuCA outperforms the state-of-the-art GRPO baseline, achieving a 6.82% relative improvement in conversion rate, reducing inter-sentence repetition by 82.28%, and lowering identity detection rate by 27.35%, indicating a substantial improvement for an industrial sales scenario that effectively balances the dual demands of strategic performance and naturalistic language generation.
Reasoner for Real-World Event Detection: Scaling Reinforcement Learning via Adaptive Perplexity-Aware Sampling Strategy
Jul 02, 2025



Detecting abnormal events in real-world customer service dialogues is highly challenging due to the complexity of business data and the dynamic nature of customer interactions. Moreover, models must demonstrate strong out-of-domain (OOD) generalization to enable rapid adaptation across different business scenarios and maximize commercial value. In this work, we propose a novel Adaptive Perplexity-Aware Reinforcement Learning (APARL) framework that leverages the advanced reasoning capabilities of large language models for abnormal event detection. APARL introduces a dual-loop dynamic curriculum learning architecture, enabling the model to progressively focus on more challenging samples as its proficiency increases. This design effectively addresses performance bottlenecks and significantly enhances OOD transferability. Extensive evaluations on food delivery dialogue tasks show that our model achieves significantly enhanced adaptability and robustness, attaining the highest F1 score with an average improvement of 17.19\%, and an average improvement of 9.59\% in OOD transfer tests. This method provides a superior solution for industrial deployment of anomaly detection models, contributing to improved operational efficiency and commercial benefits.
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
Jun 08, 2025

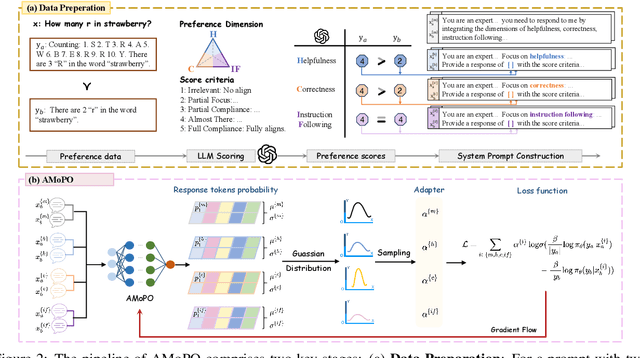
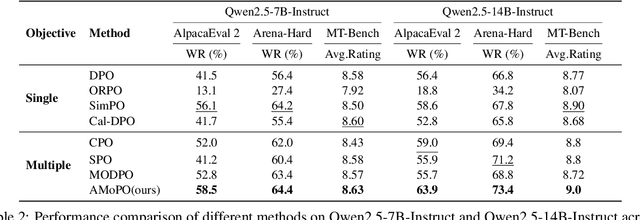
Existing multi-objective preference alignment methods for large language models (LLMs) face limitations: (1) the inability to effectively balance various preference dimensions, and (2) reliance on auxiliary reward/reference models introduces computational complexity. To address these challenges, we propose Adaptive Multi-objective Preference Optimization (AMoPO), a novel framework that achieves dynamic balance across preference dimensions. By introducing the multi-objective optimization paradigm to use the dimension-aware generation metrics as implicit rewards, AMoPO aligns LLMs with diverse preferences without additional reward models or reference models. We introduce an adaptive weight assignment mechanism that models the generation space as a Gaussian distribution, allowing dynamic prioritization of preference dimensions. Empirical results demonstrate that AMoPO outperforms state-of-the-art baselines by 28.5%, and the experiments on 7B, 14B, and 32B models reveal the scaling ability of AMoPO. Moreover, additional analysis of multiple dimensions verifies its adaptability and effectiveness. These findings validate AMoPO's capability to achieve dimension-aware preference alignment, highlighting its superiority. Our codes and datasets are available at https://github.com/Javkonline/AMoPO.
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
QPO: Query-dependent Prompt Optimization via Multi-Loop Offline Reinforcement Learning
Aug 20, 2024Prompt engineering has demonstrated remarkable success in enhancing the performance of large language models (LLMs) across diverse tasks. However, most existing prompt optimization methods only focus on the task-level performance, overlooking the importance of query-preferred prompts, which leads to suboptimal performances. Additionally, these methods rely heavily on frequent interactions with LLMs to obtain feedback for guiding the optimization process, incurring substantial redundant interaction costs. In this paper, we introduce Query-dependent Prompt Optimization (QPO), which leverages multi-loop offline reinforcement learning to iteratively fine-tune a small pretrained language model to generate optimal prompts tailored to the input queries, thus significantly improving the prompting effect on the large target LLM. We derive insights from offline prompting demonstration data, which already exists in large quantities as a by-product of benchmarking diverse prompts on open-sourced tasks, thereby circumventing the expenses of online interactions. Furthermore, we continuously augment the offline dataset with the generated prompts in each loop, as the prompts from the fine-tuned model are supposed to outperform the source prompts in the original dataset. These iterative loops bootstrap the model towards generating optimal prompts. Experiments on various LLM scales and diverse NLP and math tasks demonstrate the efficacy and cost-efficiency of our method in both zero-shot and few-shot scenarios.
GuideLight: "Industrial Solution" Guidance for More Practical Traffic Signal Control Agents
Jul 15, 2024



Currently, traffic signal control (TSC) methods based on reinforcement learning (RL) have proven superior to traditional methods. However, most RL methods face difficulties when applied in the real world due to three factors: input, output, and the cycle-flow relation. The industry's observable input is much more limited than simulation-based RL methods. For real-world solutions, only flow can be reliably collected, whereas common RL methods need more. For the output action, most RL methods focus on acyclic control, which real-world signal controllers do not support. Most importantly, industry standards require a consistent cycle-flow relationship: non-decreasing and different response strategies for low, medium, and high-level flows, which is ignored by the RL methods. To narrow the gap between RL methods and industry standards, we innovatively propose to use industry solutions to guide the RL agent. Specifically, we design behavior cloning and curriculum learning to guide the agent to mimic and meet industry requirements and, at the same time, leverage the power of exploration and exploitation in RL for better performance. We theoretically prove that such guidance can largely decrease the sample complexity to polynomials in the horizon when searching for an optimal policy. Our rigid experiments show that our method has good cycle-flow relation and superior performance.
CoSLight: Co-optimizing Collaborator Selection and Decision-making to Enhance Traffic Signal Control
May 27, 2024



Effective multi-intersection collaboration is pivotal for reinforcement-learning-based traffic signal control to alleviate congestion. Existing work mainly chooses neighboring intersections as collaborators. However, quite an amount of congestion, even some wide-range congestion, is caused by non-neighbors failing to collaborate. To address these issues, we propose to separate the collaborator selection as a second policy to be learned, concurrently being updated with the original signal-controlling policy. Specifically, the selection policy in real-time adaptively selects the best teammates according to phase- and intersection-level features. Empirical results on both synthetic and real-world datasets provide robust validation for the superiority of our approach, offering significant improvements over existing state-of-the-art methods. The code is available at https://github.com/AnonymousAccountss/CoSLight.