 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-360: Geometry-Consistent Zero-Shot Panoramic Depth Estimation
Mar 19, 2026This paper presents VGGT-360, a novel training-free framework for zero-shot, geometry-consistent panoramic depth estimation. Unlike prior view-independent training-free approaches, VGGT-360 reformulates the task as panoramic reprojection over multi-view reconstructed 3D models by leveraging the intrinsic 3D consistency of VGGT-like foundation models, thereby unifying fragmented per-view reasoning into a coherent panoramic understanding. To achieve robust and accurate estimation, VGGT-360 integrates three plug-and-play modules that form a unified panorama-to-3D-to-depth framework: (i) Uncertainty-guided adaptive projection slices panoramas into perspective views to bridge the domain gap between panoramic inputs and VGGT's perspective prior. It estimates gradient-based uncertainty to allocate denser views to geometry-poor regions, yielding geometry-informative inputs for VGGT. (ii) Structure-saliency enhanced attention strengthens VGGT's robustness during 3D reconstruction by injecting structure-aware confidence into its attention layers, guiding focus toward geometrically reliable regions and enhancing cross-view coherence. (iii) Correlation-weighted 3D model correction refines the reconstructed 3D model by reweighting overlapping points using attention-inferred correlation scores, providing a consistent geometric basis for accurate panoramic reprojection. Extensive experiments show that VGGT-360 outperforms both trained and training-free state-of-the-art methods across multiple resolutions and diverse indoor and outdoor datasets.
AgenticRed: Optimizing Agentic Systems for Automated Red-teaming
Jan 20, 2026While recent automated red-teaming methods show promise for systematically exposing model vulnerabilities, most existing approaches rely on human-specified workflows. This dependence on manually designed workflows suffers from human biases and makes exploring the broader design space expensive. We introduce AgenticRed, an automated pipeline that leverages LLMs' in-context learning to iteratively design and refine red-teaming systems without human intervention. Rather than optimizing attacker policies within predefined structures, AgenticRed treats red-teaming as a system design problem. Inspired by methods like Meta Agent Search, we develop a novel procedure for evolving agentic systems using evolutionary selection, and apply it to the problem of automatic red-teaming. Red-teaming systems designed by AgenticRed consistently outperform state-of-the-art approaches, achieving 96% attack success rate (ASR) on Llama-2-7B (36% improvement) and 98% on Llama-3-8B on HarmBench. Our approach exhibits strong transferability to proprietary models, achieving 100% ASR on GPT-3.5-Turbo and GPT-4o-mini, and 60% on Claude-Sonnet-3.5 (24% improvement). This work highlights automated system design as a powerful paradigm for AI safety evaluation that can keep pace with rapidly evolving models.
Accelerating MHC-II Epitope Discovery via Multi-Scale Prediction in Antigen Presentation
Dec 16, 2025

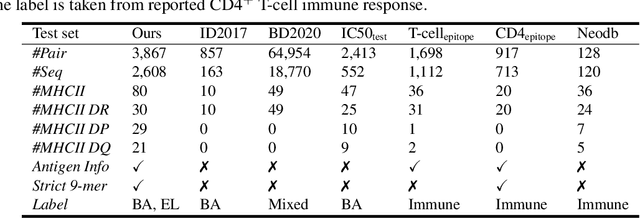
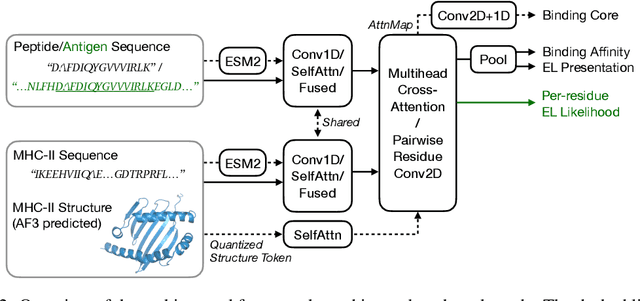
Antigenic epitope presented by major histocompatibility complex II (MHC-II) proteins plays an essential role in immunotherapy. However, compared to the more widely studied MHC-I in computational immunotherapy, the study of MHC-II antigenic epitope poses significantly more challenges due to its complex binding specificity and ambiguous motif patterns. Consequently, existing datasets for MHC-II interactions are smaller and less standardized than those available for MHC-I. To address these challenges, we present a well-curated dataset derived from the Immune Epitope Database (IEDB) and other public sources. It not only extends and standardizes existing peptide-MHC-II datasets, but also introduces a novel antigen-MHC-II dataset with richer biological context. Leveraging this dataset, we formulate three major machine learning (ML) tasks of peptide binding, peptide presentation, and antigen presentation, which progressively capture the broader biological processes within the MHC-II antigen presentation pathway. We further employ a multi-scale evaluation framework to benchmark existing models, along with a comprehensive analysis over various modeling designs to this problem with a modular framework. Overall, this work serves as a valuable resource for advancing computational immunotherapy, providing a foundation for future research in ML guided epitope discovery and predictive modeling of immune responses.
BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Dec 12, 2025The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.
Generating Piano Music with Transformers: A Comparative Study of Scale, Data, and Metrics
Nov 10, 2025Although a variety of transformers have been proposed for symbolic music generation in recent years, there is still little comprehensive study on how specific design choices affect the quality of the generated music. In this work, we systematically compare different datasets, model architectures, model sizes, and training strategies for the task of symbolic piano music generation. To support model development and evaluation, we examine a range of quantitative metrics and analyze how well they correlate with human judgment collected through listening studies. Our best-performing model, a 950M-parameter transformer trained on 80K MIDI files from diverse genres, produces outputs that are often rated as human-composed in a Turing-style listening survey.
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
Jun 11, 2025Large Language Models (LLMs) are now integral across various domains and have demonstrated impressive performance. Progress, however, rests on the premise that benchmark scores are both accurate and reproducible. We demonstrate that the reproducibility of LLM performance is fragile: changing system configuration such as evaluation batch size, GPU count, and GPU version can introduce significant difference in the generated responses. This issue is especially pronounced in reasoning models, where minor rounding differences in early tokens can cascade into divergent chains of thought, ultimately affecting accuracy. For instance, under bfloat16 precision with greedy decoding, a reasoning model like DeepSeek-R1-Distill-Qwen-7B can exhibit up to 9% variation in accuracy and 9,000 tokens difference in response length due to differences in GPU count, type, and evaluation batch size. We trace the root cause of this variability to the non-associative nature of floating-point arithmetic under limited numerical precision. This work presents the first systematic investigation into how numerical precision affects reproducibility in LLM inference. Through carefully controlled experiments across various hardware, software, and precision settings, we quantify when and how model outputs diverge. Our analysis reveals that floating-point precision -- while critical for reproducibility -- is often neglected in evaluation practices. Inspired by this, we develop a lightweight inference pipeline, dubbed LayerCast, that stores weights in 16-bit precision but performs all computations in FP32, balancing memory efficiency with numerical stability. Code is available at https://github.com/nanomaoli/llm_reproducibility.
AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
Interpreting and Steering LLMs with Mutual Information-based Explanations on Sparse Autoencoders
Feb 21, 2025



Large language models (LLMs) excel at handling human queries, but they can occasionally generate flawed or unexpected responses. Understanding their internal states is crucial for understanding their successes, diagnosing their failures, and refining their capabilities. Although sparse autoencoders (SAEs) have shown promise for interpreting LLM internal representations, limited research has explored how to better explain SAE features, i.e., understanding the semantic meaning of features learned by SAE. Our theoretical analysis reveals that existing explanation methods suffer from the frequency bias issue, where they emphasize linguistic patterns over semantic concepts, while the latter is more critical to steer LLM behaviors. To address this, we propose using a fixed vocabulary set for feature interpretations and designing a mutual information-based objective, aiming to better capture the semantic meaning behind these features. We further propose two runtime steering strategies that adjust the learned feature activations based on their corresponding explanations. Empirical results show that, compared to baselines, our method provides more discourse-level explanations and effectively steers LLM behaviors to defend against jailbreak attacks. These findings highlight the value of explanations for steering LLM behaviors in downstream applications. We will release our code and data once accepted.
Robot Learning with Super-Linear Scaling
Dec 02, 2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/