 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025



A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
BRIDGE: Bootstrapping Text to Control Time-Series Generation via Multi-Agent Iterative Optimization and Diffusion Modelling
Mar 05, 2025



Time-series Generation (TSG) is a prominent research area with broad applications in simulations, data augmentation, and counterfactual analysis. While existing methods have shown promise in unconditional single-domain TSG, real-world applications demand for cross-domain approaches capable of controlled generation tailored to domain-specific constraints and instance-level requirements. In this paper, we argue that text can provide semantic insights, domain information and instance-specific temporal patterns, to guide and improve TSG. We introduce ``Text-Controlled TSG'', a task focused on generating realistic time series by incorporating textual descriptions. To address data scarcity in this setting, we propose a novel LLM-based Multi-Agent framework that synthesizes diverse, realistic text-to-TS datasets. Furthermore, we introduce BRIDGE, a hybrid text-controlled TSG framework that integrates semantic prototypes with text description for supporting domain-level guidance. This approach achieves state-of-the-art generation fidelity on 11 of 12 datasets, and improves controllability by 12.52% on MSE and 6.34% MAE compared to no text input generation, highlighting its potential for generating tailored time-series data.
TimeDP: Learning to Generate Multi-Domain Time Series with Domain Prompts
Jan 09, 2025



Time series generation models are crucial for applications like data augmentation and privacy preservation. Most existing time series generation models are typically designed to generate data from one specified domain. While leveraging data from other domain for better generalization is proved to work in other application areas, this approach remains challenging for time series modeling due to the large divergence in patterns among different real world time series categories. In this paper, we propose a multi-domain time series diffusion model with domain prompts, named TimeDP. In TimeDP, we utilize a time series semantic prototype module which defines time series prototypes to represent time series basis, each prototype vector serving as "word" representing some elementary time series feature. A prototype assignment module is applied to extract the extract domain specific prototype weights, for learning domain prompts as generation condition. During sampling, we extract "domain prompt" with few-shot samples from the target domain and use the domain prompts as condition to generate time series samples. Experiments demonstrate that our method outperforms baselines to provide the state-of-the-art in-domain generation quality and strong unseen domain generation capability.
InvDiff: Invariant Guidance for Bias Mitigation in Diffusion Models
Dec 11, 2024



As one of the most successful generative models, diffusion models have demonstrated remarkable efficacy in synthesizing high-quality images. These models learn the underlying high-dimensional data distribution in an unsupervised manner. Despite their success, diffusion models are highly data-driven and prone to inheriting the imbalances and biases present in real-world data. Some studies have attempted to address these issues by designing text prompts for known biases or using bias labels to construct unbiased data. While these methods have shown improved results, real-world scenarios often contain various unknown biases, and obtaining bias labels is particularly challenging. In this paper, we emphasize the necessity of mitigating bias in pre-trained diffusion models without relying on auxiliary bias annotations. To tackle this problem, we propose a framework, InvDiff, which aims to learn invariant semantic information for diffusion guidance. Specifically, we propose identifying underlying biases in the training data and designing a novel debiasing training objective. Then, we employ a lightweight trainable module that automatically preserves invariant semantic information and uses it to guide the diffusion model's sampling process toward unbiased outcomes simultaneously. Notably, we only need to learn a small number of parameters in the lightweight learnable module without altering the pre-trained diffusion model. Furthermore, we provide a theoretical guarantee that the implementation of InvDiff is equivalent to reducing the error upper bound of generalization. Extensive experimental results on three publicly available benchmarks demonstrate that InvDiff effectively reduces biases while maintaining the quality of image generation. Our code is available at https://github.com/Hundredl/InvDiff.
NumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
May 01, 2024



Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.
Automatic Emergency Dust-Free solution on-board International Space Station with Bi-GRU (AED-ISS)
Oct 16, 2022
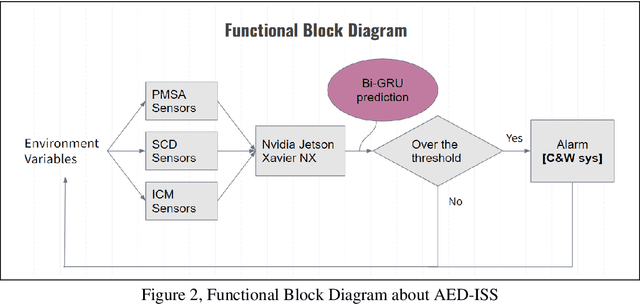
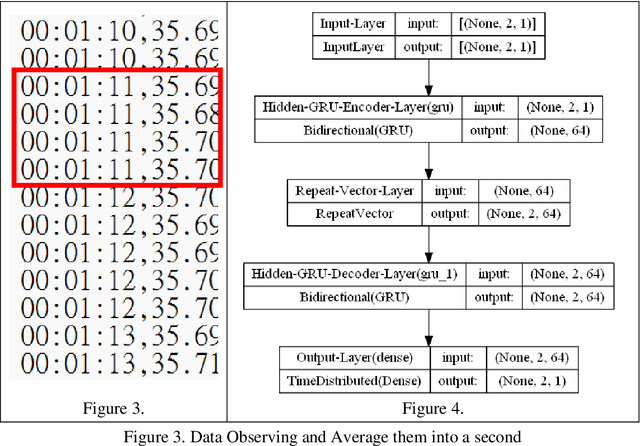
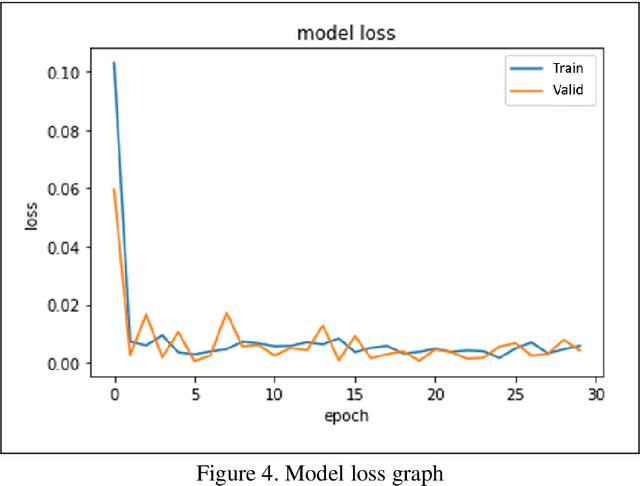
With a rising attention for the issue of PM2.5 or PM0.3, particulate matters have become not only a potential threat to both the environment and human, but also a harming existence to instruments onboard International Space Station (ISS). Our team is aiming to relate various concentration of particulate matters to magnetic fields, humidity, acceleration, temperature, pressure and CO2 concentration. Our goal is to establish an early warning system (EWS), which is able to forecast the levels of particulate matters and provides ample reaction time for astronauts to protect their instruments in some experiments or increase the accuracy of the measurements; In addition, the constructed model can be further developed into a prototype of a remote-sensing smoke alarm for applications related to fires. In this article, we will implement the Bi-GRU (Bidirectional Gated Recurrent Unit) algorithms that collect data for past 90 minutes and predict the levels of particulates which over 2.5 micrometer per 0.1 liter for the next 1 minute, which is classified as an early warning
Bridging Unsupervised and Supervised Depth from Focus via All-in-Focus Supervision
Aug 24, 2021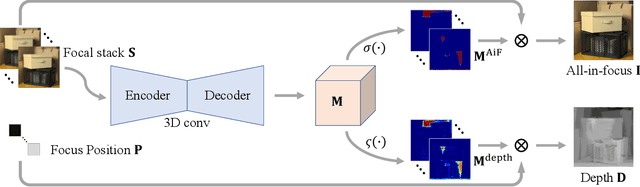

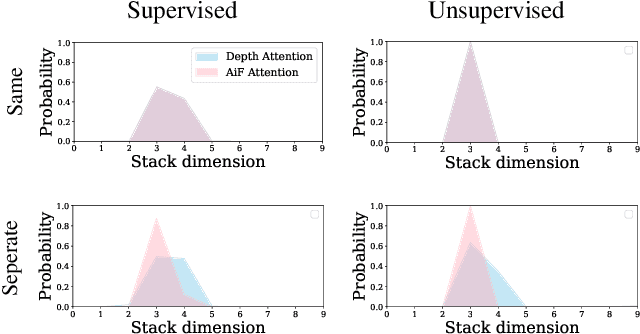
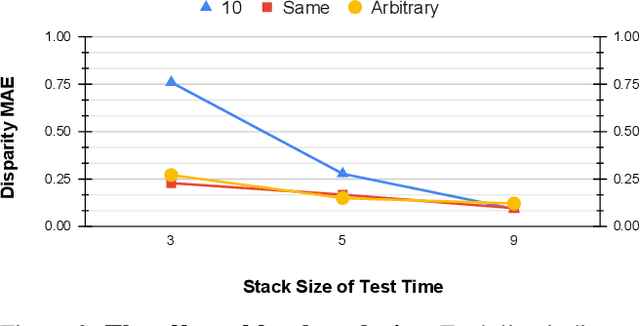
Depth estimation is a long-lasting yet important task in computer vision. Most of the previous works try to estimate depth from input images and assume images are all-in-focus (AiF), which is less common in real-world applications. On the other hand, a few works take defocus blur into account and consider it as another cue for depth estimation. In this paper, we propose a method to estimate not only a depth map but an AiF image from a set of images with different focus positions (known as a focal stack). We design a shared architecture to exploit the relationship between depth and AiF estimation. As a result, the proposed method can be trained either supervisedly with ground truth depth, or \emph{unsupervisedly} with AiF images as supervisory signals. We show in various experiments that our method outperforms the state-of-the-art methods both quantitatively and qualitatively, and also has higher efficiency in inference time.
CLCC: Contrastive Learning for Color Constancy
Jun 09, 2021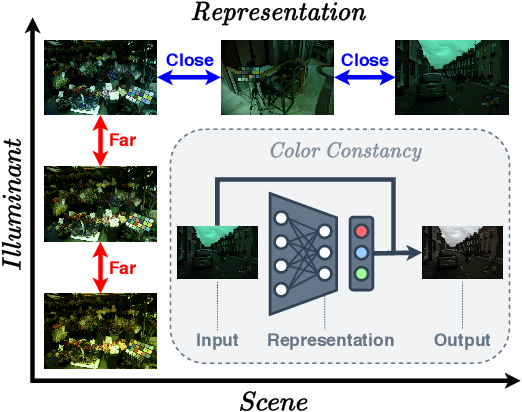
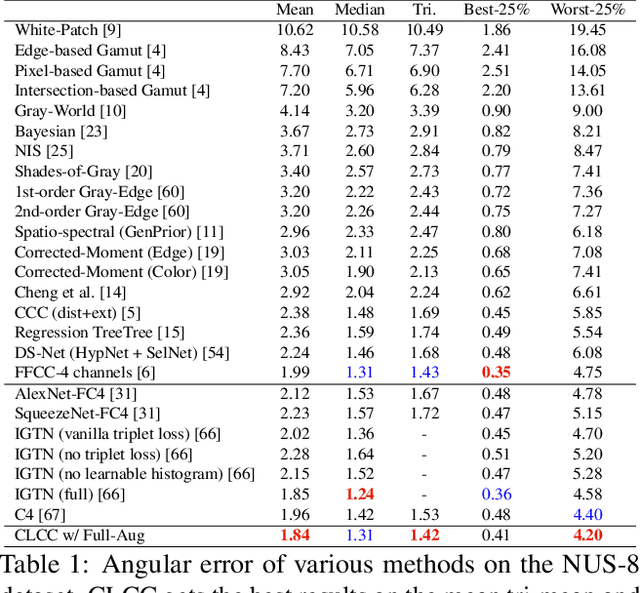
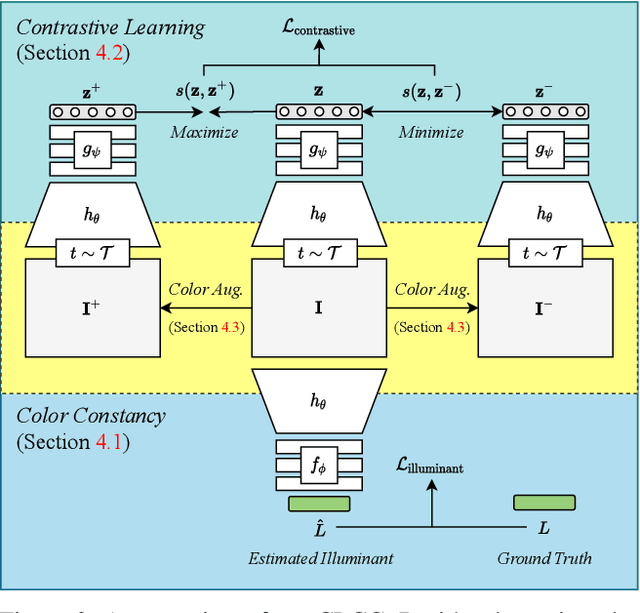
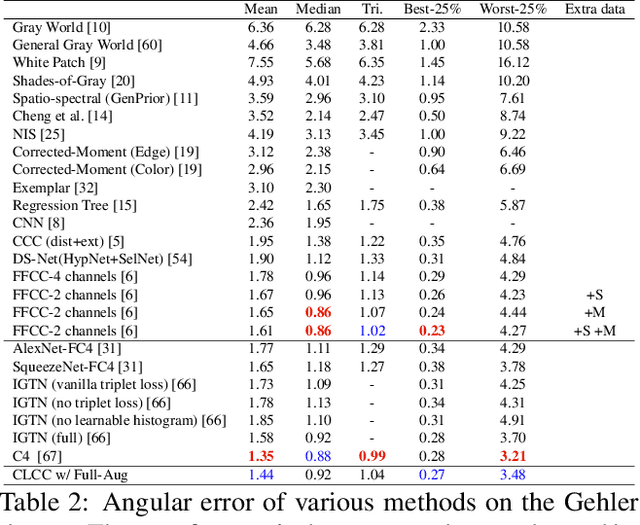
In this paper, we present CLCC, a novel contrastive learning framework for color constancy. Contrastive learning has been applied for learning high-quality visual representations for image classification. One key aspect to yield useful representations for image classification is to design illuminant invariant augmentations. However, the illuminant invariant assumption conflicts with the nature of the color constancy task, which aims to estimate the illuminant given a raw image. Therefore, we construct effective contrastive pairs for learning better illuminant-dependent features via a novel raw-domain color augmentation. On the NUS-8 dataset, our method provides $17.5\%$ relative improvements over a strong baseline, reaching state-of-the-art performance without increasing model complexity. Furthermore, our method achieves competitive performance on the Gehler dataset with $3\times$ fewer parameters compared to top-ranking deep learning methods. More importantly, we show that our model is more robust to different scenes under close proximity of illuminants, significantly reducing $28.7\%$ worst-case error in data-sparse regions.