 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionMap: Robot Policy Learning via Voxel Action Heatmap
Jun 05, 2026Vision-language-action (VLA) models have advanced rapidly across backbones, training recipes, and data scale, yet the action decoder, which converts the backbone's hidden state into a continuous control signal, has barely changed and remains a single-point predictor across the majority of current VLAs. Whether implemented via autoregressive token bins, L1 regression, or flow-matching denoising, the resulting decoder treats the action space as unstructured, leaving the geometric proximity of neighboring actions unexploited during training. To advance this, we introduce ActionMap, a voxel heatmap action head that drops into an existing VLA in place of its native action decoder. For each new action, the head predicts a voxel heatmap over the action space, where each voxel directly stores the probability of the corresponding action. Across LIBERO simulation and real-world Franka manipulation, our heatmap head surpasses two architecturally distinct backbones at matched training steps (e.g., +8.2% over OpenVLA-OFT's L1 regression head on the LIBERO four-suite average), converges at comparable or faster rates on both backbones, and remains markedly more data-efficient at low training data. The cross-backbone consistency indicates that action representation is a real lever for VLA performance, distinct from further backbone or recipe scaling. Project Page: https://github.com/showlab/ActionMap.
LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment
Apr 13, 2026While the shortage of explicit action data limits Vision-Language-Action (VLA) models, human action videos offer a scalable yet unlabeled data source. A critical challenge in utilizing large-scale human video datasets lies in transforming visual signals into ontology-independent representations, known as latent actions. However, the capacity of latent action representation to derive robust control from visual observations has yet to be rigorously evaluated. We introduce the Latent Action Representation Yielding (LARY) Benchmark, a unified framework for evaluating latent action representations on both high-level semantic actions (what to do) and low-level robotic control (how to do). The comprehensively curated dataset encompasses over one million videos (1,000 hours) spanning 151 action categories, alongside 620K image pairs and 595K motion trajectories across diverse embodiments and environments. Our experiments reveal two crucial insights: (i) General visual foundation models, trained without any action supervision, consistently outperform specialized embodied latent action models. (ii) Latent-based visual space is fundamentally better aligned to physical action space than pixel-based space. These results suggest that general visual representations inherently encode action-relevant knowledge for physical control, and that semantic-level abstraction serves as a fundamentally more effective pathway from vision to action than pixel-level reconstruction.
Cortical Policy: A Dual-Stream View Transformer for Robotic Manipulation
Mar 22, 2026View transformers process multi-view observations to predict actions and have shown impressive performance in robotic manipulation. Existing methods typically extract static visual representations in a view-specific manner, leading to inadequate 3D spatial reasoning ability and a lack of dynamic adaptation. Taking inspiration from how the human brain integrates static and dynamic views to address these challenges, we propose Cortical Policy, a novel dual-stream view transformer for robotic manipulation that jointly reasons from static-view and dynamic-view streams. The static-view stream enhances spatial understanding by aligning features of geometrically consistent keypoints extracted from a pretrained 3D foundation model. The dynamic-view stream achieves adaptive adjustment through position-aware pretraining of an egocentric gaze estimation model, computationally replicating the human cortical dorsal pathway. Subsequently, the complementary view representations of both streams are integrated to determine the final actions, enabling the model to handle spatially-complex and dynamically-changing tasks under language conditions. Empirical evaluations on RLBench, the challenging COLOSSEUM benchmark, and real-world tasks demonstrate that Cortical Policy outperforms state-of-the-art baselines substantially, validating the superiority of dual-stream design for visuomotor control. Our cortex-inspired framework offers a fresh perspective for robotic manipulation and holds potential for broader application in vision-based robot control.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025



Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Aug 28, 2025The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025
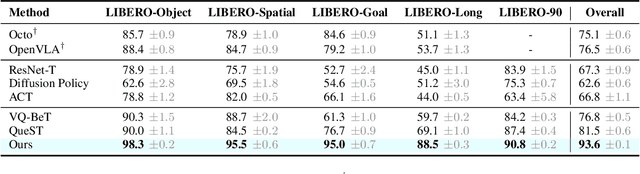
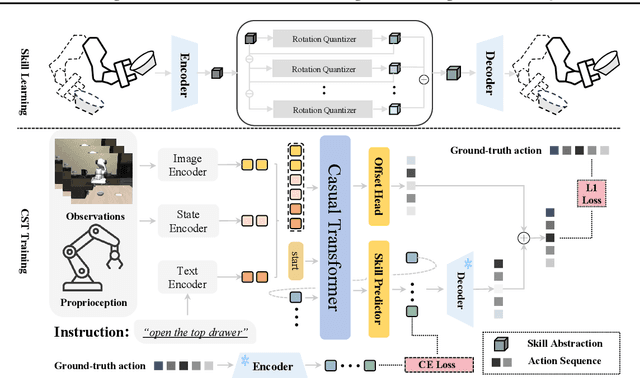

Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
May 29, 2025



Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
Few-Shot Vision-Language Action-Incremental Policy Learning
Apr 22, 2025Recently, Transformer-based robotic manipulation methods utilize multi-view spatial representations and language instructions to learn robot motion trajectories by leveraging numerous robot demonstrations. However, the collection of robot data is extremely challenging, and existing methods lack the capability for continuous learning on new tasks with only a few demonstrations. In this paper, we formulate these challenges as the Few-Shot Action-Incremental Learning (FSAIL) task, and accordingly design a Task-prOmpt graPh evolutIon poliCy (TOPIC) to address these issues. Specifically, to address the data scarcity issue in robotic imitation learning, TOPIC learns Task-Specific Prompts (TSP) through the deep interaction of multi-modal information within few-shot demonstrations, thereby effectively extracting the task-specific discriminative information. On the other hand, to enhance the capability for continual learning on new tasks and mitigate the issue of catastrophic forgetting, TOPIC adopts a Continuous Evolution Strategy (CES). CES leverages the intrinsic relationships between tasks to construct a task relation graph, which effectively facilitates the adaptation of new tasks by reusing skills learned from previous tasks. TOPIC pioneers few-shot continual learning in the robotic manipulation task, and extensive experimental results demonstrate that TOPIC outperforms state-of-the-art baselines by over 26$\%$ in success rate, significantly enhancing the continual learning capabilities of existing Transformer-based policies.
Spatial-Temporal Graph Diffusion Policy with Kinematic Modeling for Bimanual Robotic Manipulation
Mar 13, 2025



Despite the significant success of imitation learning in robotic manipulation, its application to bimanual tasks remains highly challenging. Existing approaches mainly learn a policy to predict a distant next-best end-effector pose (NBP) and then compute the corresponding joint rotation angles for motion using inverse kinematics. However, they suffer from two important issues: (1) rarely considering the physical robotic structure, which may cause self-collisions or interferences, and (2) overlooking the kinematics constraint, which may result in the predicted poses not conforming to the actual limitations of the robot joints. In this paper, we propose Kinematics enhanced Spatial-TemporAl gRaph Diffuser (KStar Diffuser). Specifically, (1) to incorporate the physical robot structure information into action prediction, KStar Diffuser maintains a dynamic spatial-temporal graph according to the physical bimanual joint motions at continuous timesteps. This dynamic graph serves as the robot-structure condition for denoising the actions; (2) to make the NBP learning objective consistent with kinematics, we introduce the differentiable kinematics to provide the reference for optimizing KStar Diffuser. This module regularizes the policy to predict more reliable and kinematics-aware next end-effector poses. Experimental results show that our method effectively leverages the physical structural information and generates kinematics-aware actions in both simulation and real-world