 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Waypoints: A Trajectory-Centric Waypointing Paradigm for Vision-Language Navigation
Jun 05, 2026Vision-Language Navigation in Continuous Environments (VLN-CE) requires agents to follow natural-language instructions while navigating in real-world-like environments. Most VLN-CE approach\-es adopt a three-stage framework: a waypoint predictor proposes navigable waypoints, and a navigator selects the best waypoint, with a low-level controller executing the movement to it. However, this decoupled paradigm often leads to unreachable waypoints or inconsistencies between planning and control. In this work, instead of predicting isolated waypoints, we introduce a novel paradigm called Trajectory Waypoint, which grounds each candidate waypoint in an executable trajectory. To realize this, we design a Trajectory Waypoint Predictor formulated as a TSDF-guided diffusion policy, which steers trajectory generation away from obstacles, inherently ensuring the reachability of the predicted waypoints. We further propose a trajectory-enhanced navigator that injects the associated trajectory as additional information for planning, enabling strict consistency between high-level semantic decisions and low-level execution. Extensive experiments on the VLN-CE benchmark show that our Trajectory Waypoint paradigm achieves superior performance over the baselines.
Cortical Policy: A Dual-Stream View Transformer for Robotic Manipulation
Mar 22, 2026View transformers process multi-view observations to predict actions and have shown impressive performance in robotic manipulation. Existing methods typically extract static visual representations in a view-specific manner, leading to inadequate 3D spatial reasoning ability and a lack of dynamic adaptation. Taking inspiration from how the human brain integrates static and dynamic views to address these challenges, we propose Cortical Policy, a novel dual-stream view transformer for robotic manipulation that jointly reasons from static-view and dynamic-view streams. The static-view stream enhances spatial understanding by aligning features of geometrically consistent keypoints extracted from a pretrained 3D foundation model. The dynamic-view stream achieves adaptive adjustment through position-aware pretraining of an egocentric gaze estimation model, computationally replicating the human cortical dorsal pathway. Subsequently, the complementary view representations of both streams are integrated to determine the final actions, enabling the model to handle spatially-complex and dynamically-changing tasks under language conditions. Empirical evaluations on RLBench, the challenging COLOSSEUM benchmark, and real-world tasks demonstrate that Cortical Policy outperforms state-of-the-art baselines substantially, validating the superiority of dual-stream design for visuomotor control. Our cortex-inspired framework offers a fresh perspective for robotic manipulation and holds potential for broader application in vision-based robot control.
GeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Feb 27, 2026Reconstructing photorealistic and animatable 4D head avatars from a single portrait image remains a fundamental challenge in computer vision. While diffusion models have enabled remarkable progress in image and video generation for avatar reconstruction, existing methods primarily rely on 2D priors and struggle to achieve consistent 3D geometry. We propose a novel framework that leverages geometry-aware diffusion to learn strong geometry priors for high-fidelity head avatar reconstruction. Our approach jointly synthesizes portrait images and corresponding surface normals, while a pose-free expression encoder captures implicit expression representations. Both synthesized images and expression latents are incorporated into 3D Gaussian-based avatars, enabling photorealistic rendering with accurate geometry. Extensive experiments demonstrate that our method substantially outperforms state-of-the-art approaches in visual quality, expression fidelity, and cross-identity generalization, while supporting real-time rendering.
U-Mind: A Unified Framework for Real-Time Multimodal Interaction with Audiovisual Generation
Feb 27, 2026Full-stack multimodal interaction in real-time is a central goal in building intelligent embodied agents capable of natural, dynamic communication. However, existing systems are either limited to unimodal generation or suffer from degraded reasoning and poor cross-modal alignment, preventing coherent and perceptually grounded interactions. In this work, we introduce U-Mind, the first unified system for high-intelligence multimodal dialogue that supports real-time generation and jointly models language, speech, motion, and video synthesis within a single interactive loop. At its core, U-Mind implements a Unified Alignment and Reasoning Framework that addresses two key challenges: enhancing cross-modal synchronization via a segment-wise alignment strategy, and preserving reasoning abilities through Rehearsal-Driven Learning. During inference, U-Mind adopts a text-first decoding pipeline that performs internal chain-of-thought planning followed by temporally synchronized generation across modalities. To close the loop, we implement a real-time video rendering framework conditioned on pose and speech, enabling expressive and synchronized visual feedback. Extensive experiments demonstrate that U-Mind achieves state-of-the-art performance on a range of multimodal interaction tasks, including question answering, instruction following, and motion generation, paving the way toward intelligent, immersive conversational agents.
Imitation Learning for Multi-turn LM Agents via On-policy Expert Corrections
Dec 16, 2025



A popular paradigm for training LM agents relies on imitation learning, fine-tuning on expert trajectories. However, we show that the off-policy nature of imitation learning for multi-turn LM agents suffers from the fundamental limitation known as covariate shift: as the student policy's behavior diverges from the expert's, it encounters states not present in the training data, reducing the effectiveness of fine-tuning. Taking inspiration from the classic DAgger algorithm, we propose a novel data generation methodology for addressing covariate shift for multi-turn LLM training. We introduce on-policy expert corrections (OECs), partially on-policy data generated by starting rollouts with a student model and then switching to an expert model part way through the trajectory. We explore the effectiveness of our data generation technique in the domain of software engineering (SWE) tasks, a multi-turn setting where LLM agents must interact with a development environment to fix software bugs. Our experiments compare OEC data against various other on-policy and imitation learning approaches on SWE agent problems and train models using a common rejection sampling (i.e., using environment reward) combined with supervised fine-tuning technique. Experiments find that OEC trajectories show a relative 14% and 13% improvement over traditional imitation learning in the 7b and 32b setting, respectively, on SWE-bench verified. Our results demonstrate the need for combining expert demonstrations with on-policy data for effective multi-turn LM agent training.
Task-Aware 3D Affordance Segmentation via 2D Guidance and Geometric Refinement
Nov 12, 2025Understanding 3D scene-level affordances from natural language instructions is essential for enabling embodied agents to interact meaningfully in complex environments. However, this task remains challenging due to the need for semantic reasoning and spatial grounding. Existing methods mainly focus on object-level affordances or merely lift 2D predictions to 3D, neglecting rich geometric structure information in point clouds and incurring high computational costs. To address these limitations, we introduce Task-Aware 3D Scene-level Affordance segmentation (TASA), a novel geometry-optimized framework that jointly leverages 2D semantic cues and 3D geometric reasoning in a coarse-to-fine manner. To improve the affordance detection efficiency, TASA features a task-aware 2D affordance detection module to identify manipulable points from language and visual inputs, guiding the selection of task-relevant views. To fully exploit 3D geometric information, a 3D affordance refinement module is proposed to integrate 2D semantic priors with local 3D geometry, resulting in accurate and spatially coherent 3D affordance masks. Experiments on SceneFun3D demonstrate that TASA significantly outperforms the baselines in both accuracy and efficiency in scene-level affordance segmentation.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025



Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
UAV-ON: A Benchmark for Open-World Object Goal Navigation with Aerial Agents
Aug 01, 2025Aerial navigation is a fundamental yet underexplored capability in embodied intelligence, enabling agents to operate in large-scale, unstructured environments where traditional navigation paradigms fall short. However, most existing research follows the Vision-and-Language Navigation (VLN) paradigm, which heavily depends on sequential linguistic instructions, limiting its scalability and autonomy. To address this gap, we introduce UAV-ON, a benchmark for large-scale Object Goal Navigation (ObjectNav) by aerial agents in open-world environments, where agents operate based on high-level semantic goals without relying on detailed instructional guidance as in VLN. UAV-ON comprises 14 high-fidelity Unreal Engine environments with diverse semantic regions and complex spatial layouts, covering urban, natural, and mixed-use settings. It defines 1270 annotated target objects, each characterized by an instance-level instruction that encodes category, physical footprint, and visual descriptors, allowing grounded reasoning. These instructions serve as semantic goals, introducing realistic ambiguity and complex reasoning challenges for aerial agents. To evaluate the benchmark, we implement several baseline methods, including Aerial ObjectNav Agent (AOA), a modular policy that integrates instruction semantics with egocentric observations for long-horizon, goal-directed exploration. Empirical results show that all baselines struggle in this setting, highlighting the compounded challenges of aerial navigation and semantic goal grounding. UAV-ON aims to advance research on scalable UAV autonomy driven by semantic goal descriptions in complex real-world environments.
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards
Jun 13, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has been widely adopted as the de facto method for enhancing the reasoning capabilities of large language models and has demonstrated notable success in verifiable domains like math and competitive programming tasks. However, the efficacy of RLVR diminishes significantly when applied to agentic environments. These settings, characterized by multi-step, complex problem solving, lead to high failure rates even for frontier LLMs, as the reward landscape is too sparse for effective model training via conventional RLVR. In this work, we introduce Agent-RLVR, a framework that makes RLVR effective in challenging agentic settings, with an initial focus on software engineering tasks. Inspired by human pedagogy, Agent-RLVR introduces agent guidance, a mechanism that actively steers the agent towards successful trajectories by leveraging diverse informational cues. These cues, ranging from high-level strategic plans to dynamic feedback on the agent's errors and environmental interactions, emulate a teacher's guidance, enabling the agent to navigate difficult solution spaces and promotes active self-improvement via additional environment exploration. In the Agent-RLVR training loop, agents first attempt to solve tasks to produce initial trajectories, which are then validated by unit tests and supplemented with agent guidance. Agents then reattempt with guidance, and the agent policy is updated with RLVR based on the rewards of these guided trajectories. Agent-RLVR elevates the pass@1 performance of Qwen-2.5-72B-Instruct from 9.4% to 22.4% on SWE-Bench Verified. We find that our guidance-augmented RLVR data is additionally useful for test-time reward model training, shown by further boosting pass@1 to 27.8%. Agent-RLVR lays the groundwork for training agents with RLVR in complex, real-world environments where conventional RL methods struggle.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025
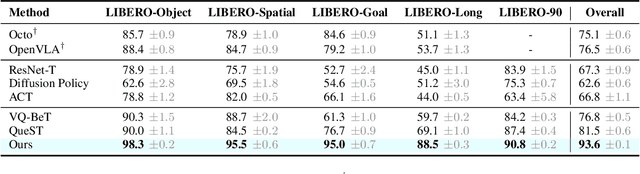
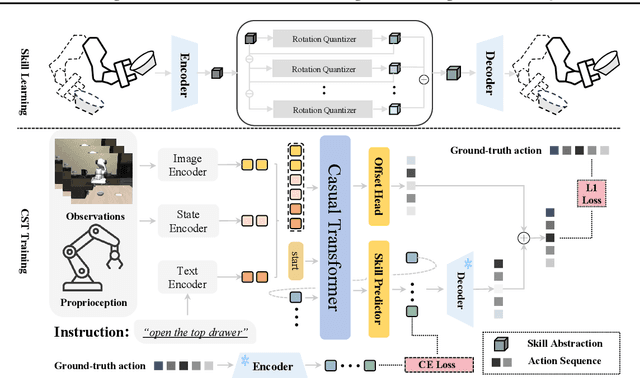

Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight