 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic-J: An AI Agent for Biological Microscopy Image Analysis
Jun 01, 2026Biological image analysis increasingly demands integration across heterogeneous tools, programming environments, and domain knowledge that few researchers can command simultaneously. We present Agentic-J, a containerised, multi-agent AI assistant, primarily for ImageJ/Fiji that enables biologists to specify analysis tasks in natural language, from nuclei segmentation and cell tracking to multi-condition quantification. The agent generates executable scripts organised into a documented project structure, so every analysis decision is traceable and the workflow can be reproduced or shared. The specialised sub-agents handle plugin management, code generation, debugging, quality assurance, and statistical reporting. In this paper we introduce the system's design, demonstrate real biological microscopy image analysis workflows, and detailed the technical implementation.
MedMemoryBench: Benchmarking Agent Memory in Personalized Healthcare
May 12, 2026The large-scale deployment of personalized healthcare agents demands memory mechanisms that are exceptionally precise, safe, and capable of long-term clinical tracking. However, existing benchmarks primarily focus on daily open-domain conversations, failing to capture the high-stakes complexity of real-world medical applications. Motivated by the stringent production requirements of an industry-leading health management agent serving tens of millions of active users, we introduce MedMemoryBench. We develop a human-agent collaborative pipeline to synthesize highly realistic, long-horizon medical trajectories based on clinically grounded, synthetic patient archetypes. This process yields a massive, expertly validated dataset comprising approximately 2,000 sessions and 16,000 interaction turns. Crucially, MedMemoryBench departs from traditional static evaluations by pioneering an "evaluate-while-constructing" streaming assessment protocol, which precisely mirrors dynamic memory accumulation in production environments. Furthermore, we formalize and systematically investigate the critical phenomenon of memory saturation, where sustained information influx actively degrades retrieval and reasoning robustness. Comprehensive benchmarking reveals severe bottlenecks in mainstream architectures, particularly concerning complex medical reasoning and noise resilience. By exposing these fundamental flaws, MedMemoryBench establishes a vital foundation for developing robust, production-ready medical agents.
PatRe: A Full-Stage Office Action and Rebuttal Generation Benchmark for Patent Examination
May 05, 2026Patent examination is a complex, multi-stage process requiring both technical expertise and legal reasoning, increasingly challenged by rising application volumes. Prior benchmarks predominantly view patent examination as discriminative classification or static extraction, failing to capture its inherently interactive and iterative nature, similar to the peer review and rebuttal process in academic publishing. In this paper, we introduce PatRe, the first benchmark that models the full patent examination lifecycle, including Office Action generation and applicant rebuttal. PatRe comprises 480 real-world cases and supports both oracle and retrieval-simulated evaluation settings. Our benchmark reframes patent examination as a dynamic, multi-turn process of justification and response. Extensive experiments across various LLMs reveal critical insights into model performance, including differences between proprietary and open-source models, as well as task asymmetries between examiner analysis and applicant-side rebuttal. These findings highlight both the potential and current limitations of LLMs in modeling complex, real-world legal reasoning and technical novelty judgment in patent examination. We release our code and dataset to facilitate future research on patent examination modeling.
FutureVLA: Joint Visuomotor Prediction for Vision-Language-Action Model
Mar 11, 2026Predictive foresight is important to intelligent embodied agents. Since the motor execution of a robot is intrinsically constrained by its visual perception of environmental geometry, effectively anticipating the future requires capturing this tightly coupled visuomotor interplay. While recent vision-language-action models attempt to incorporate future guidance, they struggle with this joint modeling. Existing explicit methods divert capacity to task-irrelevant visual details, whereas implicit methods relying on sparse frame pairs disrupt temporal continuity. By heavily relying on visual reconstruction, these methods become visually dominated, entangling static scene context with dynamic action intent. We argue that effective joint visuomotor predictive modeling requires both temporal continuity and visually-conditioned supervision decoupling. To this end, we propose FutureVLA, featuring a novel Joint Visuomotor Predictive Architecture. FutureVLA is designed to extract joint visuomotor embeddings by first decoupling visual and motor information, and then jointly encoding generalized physical priors. Specifically, in the pretraining stage, we leverage heterogeneous manipulation datasets and introduce a Joint Visuomotor Gating mechanism to structurally separate visual state preservation from temporal action modeling. It allows the motor stream to focus on continuous physical dynamics while explicitly querying visual tokens for environmental constraints, yielding highly generalizable joint visuomotor embeddings. Subsequently, in the post-training stage, we employ a latent embeddings alignment strategy, enabling diverse downstream VLA models to internalize these temporal priors without modifying their inference architectures. Extensive experiments demonstrate that FutureVLA consistently improves VLA frameworks.
A Stepwise-Enhanced Reasoning Framework for Large Language Models Based on External Subgraph Generation
Dec 29, 2025Large Language Models (LLMs) have achieved strong performance across a wide range of natural language processing tasks in recent years, including machine translation, text generation, and question answering. As their applications extend to increasingly complex scenarios, however, LLMs continue to face challenges in tasks that require deep reasoning and logical inference. In particular, models trained on large scale textual corpora may incorporate noisy or irrelevant information during generation, which can lead to incorrect predictions or outputs that are inconsistent with factual knowledge. To address this limitation, we propose a stepwise reasoning enhancement framework for LLMs based on external subgraph generation, termed SGR. The proposed framework dynamically constructs query relevant subgraphs from external knowledge bases and leverages their semantic structure to guide the reasoning process. By performing reasoning in a step by step manner over structured subgraphs, SGR reduces the influence of noisy information and improves reasoning accuracy. Specifically, the framework first generates an external subgraph tailored to the input query, then guides the model to conduct multi step reasoning grounded in the subgraph, and finally integrates multiple reasoning paths to produce the final answer. Experimental results on multiple benchmark datasets demonstrate that SGR consistently outperforms strong baselines, indicating its effectiveness in enhancing the reasoning capabilities of LLMs.
Multiscale Cross-Modal Mapping of Molecular, Pathologic, and Radiologic Phenotypes in Lipid-Deficient Clear Cell Renal CellCarcinoma
Dec 13, 2025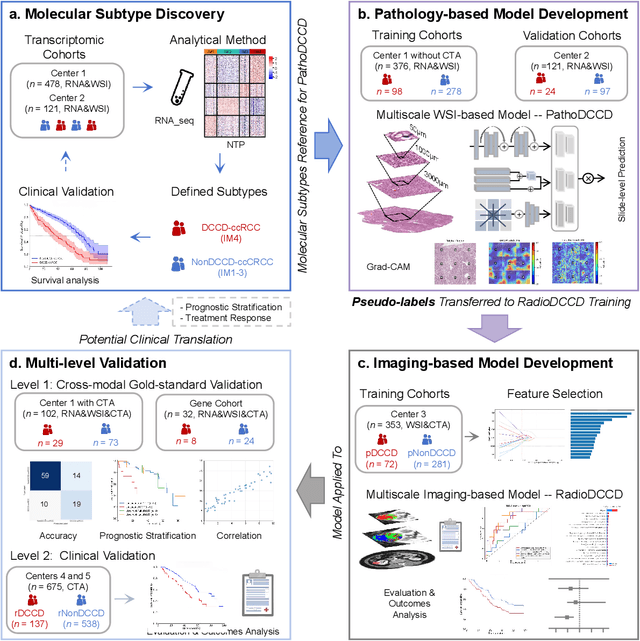
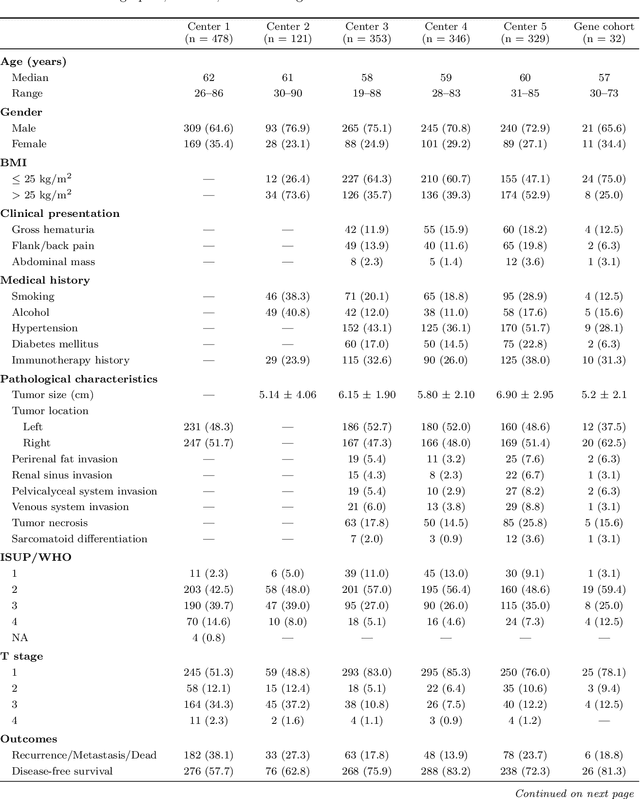
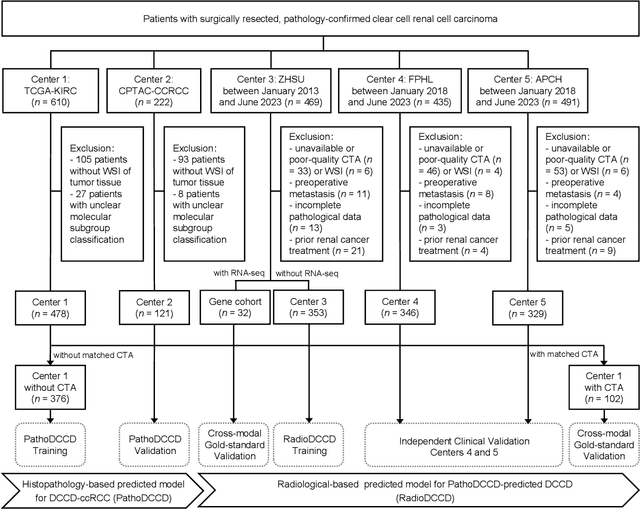
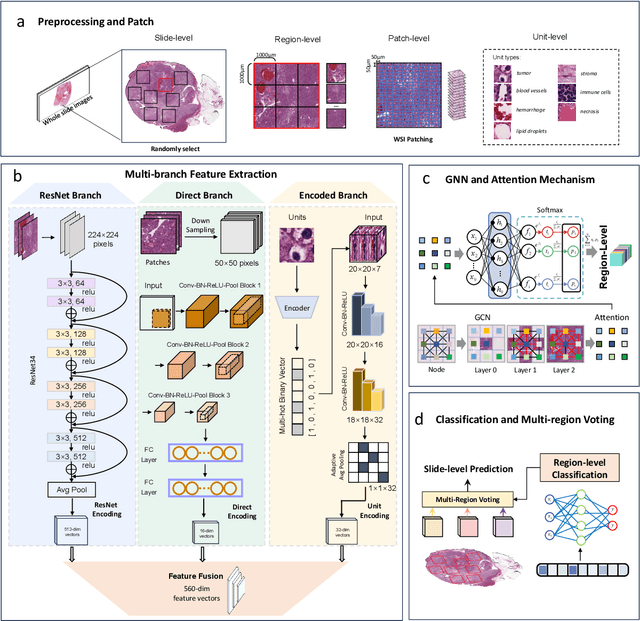
Clear cell renal cell carcinoma (ccRCC) exhibits extensive intratumoral heterogeneity on multiple biological scales, contributing to variable clinical outcomes and limiting the effectiveness of conventional TNM staging, which highlights the urgent need for multiscale integrative analytic frameworks. The lipid-deficient de-clear cell differentiated (DCCD) ccRCC subtype, defined by multi-omics analyses, is associated with adverse outcomes even in early-stage disease. Here, we establish a hierarchical cross-scale framework for the preoperative identification of DCCD-ccRCC. At the highest layer, cross-modal mapping transferred molecular signatures to histological and CT phenotypes, establishing a molecular-to-pathology-to-radiology supervisory bridge. Within this framework, each modality-specific model is designed to mirror the inherent hierarchical structure of tumor biology. PathoDCCD captured multi-scale microscopic features, from cellular morphology and tissue architecture to meso-regional organization. RadioDCCD integrated complementary macroscopic information by combining whole-tumor and its habitat-subregions radiomics with a 2D maximal-section heterogeneity metric. These nested models enabled integrated molecular subtype prediction and clinical risk stratification. Across five cohorts totaling 1,659 patients, PathoDCCD reliably recapitulated molecular subtypes, while RadioDCCD provided reliable preoperative prediction. The consistent predictions identified patients with the poorest clinical outcomes. This cross-scale paradigm unifies molecular biology, computational pathology, and quantitative radiology into a biologically grounded strategy for preoperative noninvasive molecular phenotyping of ccRCC.
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
AFT: An Exemplar-Free Class Incremental Learning Method for Environmental Sound Classification
Sep 19, 2025



As sounds carry rich information, environmental sound classification (ESC) is crucial for numerous applications such as rare wild animals detection. However, our world constantly changes, asking ESC models to adapt to new sounds periodically. The major challenge here is catastrophic forgetting, where models lose the ability to recognize old sounds when learning new ones. Many methods address this using replay-based continual learning. This could be impractical in scenarios such as data privacy concerns. Exemplar-free methods are commonly used but can distort old features, leading to worse performance. To overcome such limitations, we propose an Acoustic Feature Transformation (AFT) technique that aligns the temporal features of old classes to the new space, including a selectively compressed feature space. AFT mitigates the forgetting of old knowledge without retaining past data. We conducted experiments on two datasets, showing consistent improvements over baseline models with accuracy gains of 3.7\% to 3.9\%.
CronusVLA: Transferring Latent Motion Across Time for Multi-Frame Prediction in Manipulation
Jun 24, 2025



Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong generalization across manipulation tasks. However, they remain constrained by a single-frame observation paradigm and cannot fully benefit from the motion information offered by aggregated multi-frame historical observations, as the large vision-language backbone introduces substantial computational cost and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm through an efficient post-training stage. CronusVLA comprises three key components: (1) single-frame pretraining on large-scale embodied datasets with autoregressive action tokens prediction, which establishes an embodied vision-language foundation; (2) multi-frame encoding, adapting the prediction of vision-language backbones from discrete action tokens to motion features during post-training, and aggregating motion features from historical frames into a feature chunking; (3) cross-frame decoding, which maps the feature chunking to accurate actions via a shared decoder with cross-attention. By reducing redundant token computation and caching past motion features, CronusVLA achieves efficient inference. As an application of motion features, we further propose an action adaptation mechanism based on feature-action retrieval to improve model performance during finetuning. CronusVLA achieves state-of-the-art performance on SimplerEnv with 70.9% success rate, and 12.7% improvement over OpenVLA on LIBERO. Real-world Franka experiments also show the strong performance and robustness.
GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025



Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.