 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Text Enhances Generalization in Real-World Image Restoration
Dec 01, 2024



Generalization has long been a central challenge in real-world image restoration. While recent diffusion-based restoration methods, which leverage generative priors from text-to-image models, have made progress in recovering more realistic details, they still encounter "generative capability deactivation" when applied to out-of-distribution real-world data. To address this, we propose using text as an auxiliary invariant representation to reactivate the generative capabilities of these models. We begin by identifying two key properties of text input: richness and relevance, and examine their respective influence on model performance. Building on these insights, we introduce Res-Captioner, a module that generates enhanced textual descriptions tailored to image content and degradation levels, effectively mitigating response failures. Additionally, we present RealIR, a new benchmark designed to capture diverse real-world scenarios. Extensive experiments demonstrate that Res-Captioner significantly enhances the generalization abilities of diffusion-based restoration models, while remaining fully plug-and-play.
LLaVA-OneVision: Easy Visual Task Transfer
Aug 06, 2024



We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. Our experimental results demonstrate that LLaVA-OneVision is the first single model that can simultaneously push the performance boundaries of open LMMs in three important computer vision scenarios: single-image, multi-image, and video scenarios. Importantly, the design of LLaVA-OneVision allows strong transfer learning across different modalities/scenarios, yielding new emerging capabilities. In particular, strong video understanding and cross-scenario capabilities are demonstrated through task transfer from images to videos.
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
May 31, 2024



In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video. Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data. Project Page: https://video-mme.github.io
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mar 27, 2024



In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini. We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation. To enhance visual tokens, we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count. We further construct a high-quality dataset that promotes precise image comprehension and reasoning-based generation, expanding the operational scope of current VLMs. In general, Mini-Gemini further mines the potential of VLMs and empowers current frameworks with image understanding, reasoning, and generation simultaneously. Mini-Gemini supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34B. It is demonstrated to achieve leading performance in several zero-shot benchmarks and even surpasses the developed private models. Code and models are available at https://github.com/dvlab-research/MiniGemini.
RL-GPT: Integrating Reinforcement Learning and Code-as-policy
Feb 29, 2024



Large Language Models (LLMs) have demonstrated proficiency in utilizing various tools by coding, yet they face limitations in handling intricate logic and precise control. In embodied tasks, high-level planning is amenable to direct coding, while low-level actions often necessitate task-specific refinement, such as Reinforcement Learning (RL). To seamlessly integrate both modalities, we introduce a two-level hierarchical framework, RL-GPT, comprising a slow agent and a fast agent. The slow agent analyzes actions suitable for coding, while the fast agent executes coding tasks. This decomposition effectively focuses each agent on specific tasks, proving highly efficient within our pipeline. Our approach outperforms traditional RL methods and existing GPT agents, demonstrating superior efficiency. In the Minecraft game, it rapidly obtains diamonds within a single day on an RTX3090. Additionally, it achieves SOTA performance across all designated MineDojo tasks.
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models
Nov 28, 2023



In this work, we present a novel method to tackle the token generation challenge in Vision Language Models (VLMs) for video and image understanding, called LLaMA-VID. Current VLMs, while proficient in tasks like image captioning and visual question answering, face computational burdens when processing long videos due to the excessive visual tokens. LLaMA-VID addresses this issue by representing each frame with two distinct tokens, namely context token and content token. The context token encodes the overall image context based on user input, whereas the content token encapsulates visual cues in each frame. This dual-token strategy significantly reduces the overload of long videos while preserving critical information. Generally, LLaMA-VID empowers existing frameworks to support hour-long videos and pushes their upper limit with an extra context token. It is proved to surpass previous methods on most of video- or image-based benchmarks. Code is available https://github.com/dvlab-research/LLaMA-VID}{https://github.com/dvlab-research/LLaMA-VID
LISA: Reasoning Segmentation via Large Language Model
Aug 03, 2023Although perception systems have made remarkable advancements in recent years, they still rely on explicit human instruction to identify the target objects or categories before executing visual recognition tasks. Such systems lack the ability to actively reason and comprehend implicit user intentions. In this work, we propose a new segmentation task -- reasoning segmentation. The task is designed to output a segmentation mask given a complex and implicit query text. Furthermore, we establish a benchmark comprising over one thousand image-instruction pairs, incorporating intricate reasoning and world knowledge for evaluation purposes. Finally, we present LISA: large Language Instructed Segmentation Assistant, which inherits the language generation capabilities of the multi-modal Large Language Model (LLM) while also possessing the ability to produce segmentation masks. We expand the original vocabulary with a <SEG> token and propose the embedding-as-mask paradigm to unlock the segmentation capability. Remarkably, LISA can handle cases involving: 1) complex reasoning; 2) world knowledge; 3) explanatory answers; 4) multi-turn conversation. Also, it demonstrates robust zero-shot capability when trained exclusively on reasoning-free datasets. In addition, fine-tuning the model with merely 239 reasoning segmentation image-instruction pairs results in further performance enhancement. Experiments show our method not only unlocks new reasoning segmentation capabilities but also proves effective in both complex reasoning segmentation and standard referring segmentation tasks. Code, models, and demo are at https://github.com/dvlab-research/LISA.
Democratizing Pathological Image Segmentation with Lay Annotators via Molecular-empowered Learning
May 31, 2023Multi-class cell segmentation in high-resolution Giga-pixel whole slide images (WSI) is critical for various clinical applications. Training such an AI model typically requires labor-intensive pixel-wise manual annotation from experienced domain experts (e.g., pathologists). Moreover, such annotation is error-prone when differentiating fine-grained cell types (e.g., podocyte and mesangial cells) via the naked human eye. In this study, we assess the feasibility of democratizing pathological AI deployment by only using lay annotators (annotators without medical domain knowledge). The contribution of this paper is threefold: (1) We proposed a molecular-empowered learning scheme for multi-class cell segmentation using partial labels from lay annotators; (2) The proposed method integrated Giga-pixel level molecular-morphology cross-modality registration, molecular-informed annotation, and molecular-oriented segmentation model, so as to achieve significantly superior performance via 3 lay annotators as compared with 2 experienced pathologists; (3) A deep corrective learning (learning with imperfect label) method is proposed to further improve the segmentation performance using partially annotated noisy data. From the experimental results, our learning method achieved F1 = 0.8496 using molecular-informed annotations from lay annotators, which is better than conventional morphology-based annotations (F1 = 0.7051) from experienced pathologists. Our method democratizes the development of a pathological segmentation deep model to the lay annotator level, which consequently scales up the learning process similar to a non-medical computer vision task. The official implementation and cell annotations are publicly available at https://github.com/hrlblab/MolecularEL.
GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction
May 30, 2023



This paper aims to efficiently enable Large Language Models (LLMs) to use multimodal tools. Advanced proprietary LLMs, such as ChatGPT and GPT-4, have shown great potential for tool usage through sophisticated prompt engineering. Nevertheless, these models typically rely on prohibitive computational costs and publicly inaccessible data. To address these challenges, we propose the GPT4Tools based on self-instruct to enable open-source LLMs, such as LLaMA and OPT, to use tools. It generates an instruction-following dataset by prompting an advanced teacher with various multi-modal contexts. By using the Low-Rank Adaptation (LoRA) optimization, our approach facilitates the open-source LLMs to solve a range of visual problems, including visual comprehension and image generation. Moreover, we provide a benchmark to evaluate the ability of LLMs to use tools, which is performed in both zero-shot and fine-tuning ways. Extensive experiments demonstrate the effectiveness of our method on various language models, which not only significantly improves the accuracy of invoking seen tools, but also enables the zero-shot capacity for unseen tools. The code and demo are available at https://github.com/StevenGrove/GPT4Tools.
Diversified Dynamic Routing for Vision Tasks
Sep 26, 2022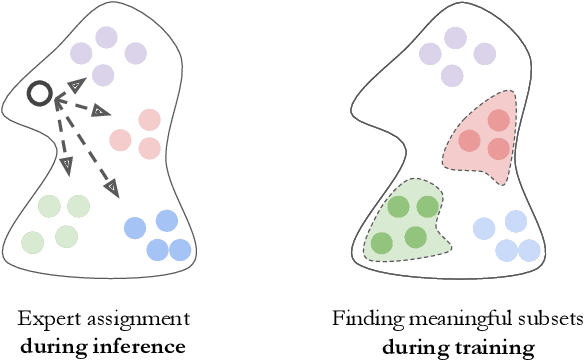
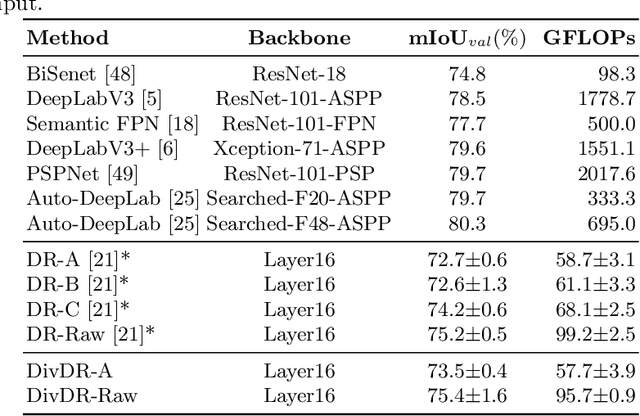
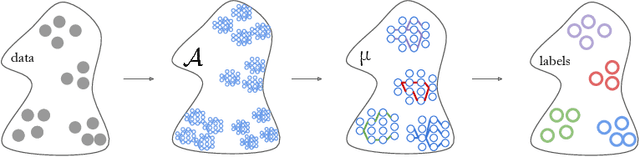
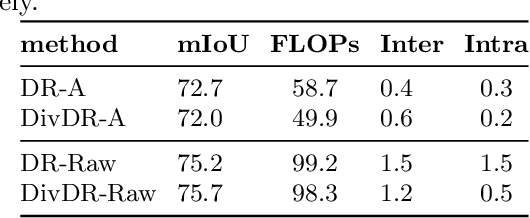
Deep learning models for vision tasks are trained on large datasets under the assumption that there exists a universal representation that can be used to make predictions for all samples. Whereas high complexity models are proven to be capable of learning such representations, a mixture of experts trained on specific subsets of the data can infer the labels more efficiently. However using mixture of experts poses two new problems, namely (i) assigning the correct expert at inference time when a new unseen sample is presented. (ii) Finding the optimal partitioning of the training data, such that the experts rely the least on common features. In Dynamic Routing (DR) a novel architecture is proposed where each layer is composed of a set of experts, however without addressing the two challenges we demonstrate that the model reverts to using the same subset of experts. In our method, Diversified Dynamic Routing (DivDR) the model is explicitly trained to solve the challenge of finding relevant partitioning of the data and assigning the correct experts in an unsupervised approach. We conduct several experiments on semantic segmentation on Cityscapes and object detection and instance segmentation on MS-COCO showing improved performance over several baselines.